









 本文深入探讨了二叉搜索树及其变种,包括平衡二叉树AVL和红黑树,以及B树和B+树。详细阐述了它们的特性、插入、删除、查找操作,以及在数据库索引中的应用。此外,还分析了各自在不同场景下的优缺点和适用性。
本文深入探讨了二叉搜索树及其变种,包括平衡二叉树AVL和红黑树,以及B树和B+树。详细阐述了它们的特性、插入、删除、查找操作,以及在数据库索引中的应用。此外,还分析了各自在不同场景下的优缺点和适用性。
版权声明
本文非纯粹原创,是综合了多位作者的资料融合而成的学习笔记。部分图片也来源于其他文章。欢迎转载,注明来源即可。文末附上了所有参考来源。
本文主要内容
每一知识点下都包含了力扣一些题目方便检验学习成果,文中代码使用语法为C++,代码均可通过,且有较详细的注释。
-
二叉树
- 二叉树生成
- 二叉树遍历
- 递归先中后序遍历
- 非递归先中后遍历
- DFS和BFS遍历
- 线索二叉树
- 哈弗曼树
-
分治法
- 常用场景
- 模板
- 代码结构(3步)
- 处理情况(3种)
- 逻辑判断
- 例题
-
二叉树例题
-
BFS层次遍历例题
-
延申内容
- 二叉搜索树
- B树
- B+树
- AVL树
- 红黑树
-
树中的常见面试问题
-
未完成
- 堆
二叉树
常见的数据结构,因此衍生的数据结构有平衡二叉树,红黑树,Btree,B+tree。
二叉树结构体
struct treeNode{
int val;
treeNode *left;
treeNode *right;
treeNode(int x): val=x,left=NULL,right=NULL {};//结构体的构造函数,cpp特性。赋值语句在{}外相当于初始化,若在括号内则等同于赋值。
};
生成二叉树
由list转为二叉树数据结构,数字0标记为空点
TreeNode* listCreateTree (vector<int> treeList,int ptr){
if (ptr > treeList.size()-1 || treeList[ptr] == 0)//当作空点
return NULL;
TreeNode* node;
node = (TreeNode*)malloc(sizeof(TreeNode));
node->val = treeList[ptr];
node->left = listCreateTree(treeList,2*ptr+1);
node->right = listCreateTree(treeList,2*ptr+2);
return node;
}
遍历
先序遍历是根左右的遍历顺序,中序遍历是左根右的遍历顺序,后序遍历是左右根的遍历顺序。先中后指示了根的位置,永远都是先左再右。其中递归方法的先中后序遍历,仅需要修改对应的迭代函数顺序即可。
递归先序遍历
void preOrderTravelsal (treeNode * root){
if (root == NULL)
return ;
printf("%s",root->val);
preOrderTravalsal(root->left);
preOrderTravalsal(root->right);
}
非递归先序遍历
该方法需要用到栈对已遍历的内容进行暂存,需要占用较大的储存空间
void preOderTravelsal (treeNode * root){
//a stack for saving treeNode
Stack<treeNode*> treeNodeStack = new Stack<treeNode*>();
treeNode * node = root;
//if node is the last one and stack is empty , all treeNode have been passed
while (node! = NULL || !treeNodeStack.empty()){
while (node != NULL){//in this loop will move to the most deep left node
//.....operation.......
printf("%s",node->val);
//.....................
// push node into stack for travel right node in the future
treeNodeStack.push(node);
// left node
node = node->left;
}
if(!treeNodeStack.empty()){
node = treeNodeStack.top();
treeNodeStack.pop();
node = node->right;
}
}
}
非递归中序遍历
左根右
void inorderTraversal(treeNode * root){
Stack<treeNode*> treeNodeStack = new Stack<treeNode*>();
treeNode * node = root;
while(node!=NULL || !treeNodeStack.empty()){
while(node!=NULL){
treeNodeStack.push(node);//root
node = node->left;
}
node = treeNodeStack.top();
treeNodeStack.pop();
//...operate...
printf("%s",node->val);
node = node -> right;
}
}
非递归后序遍历
左右根 注意先右再根,这一步必须打标记
void postorderTraversal(treeNode * root){
stack<treeNode*> treeNodeStack = new Stack<treeNode*>();
treeNode* node = root;
treeNode* lastvisit;
while(node!=NULL || !treeNodeStack.empty()){
while(node!=NULL){
treeNodeStack.push(node);
node = node->left;
}
node = treeNodeStack.top();
if( node->right == NULL || node->right == lastvisit){//the root node should be operate after right node
treeNodeStack.pop();
//..operate..
printf("%s",node->val);
lastvisit = node;
}
else{
node = node->right;
}
}
}
}
DFS深度搜索-从上到下
使用指针标记位置,逐步填入数组,增加一个参数用于标记当前level可计算最大深度。
void dfs(treeNode* root, vector<int>& result){
if root == NULL
return result;
result.append(root->val);
dfs(root->left,result);
dfs(root->right, result);
}
vector<int> dfsTraversal(treeNode* root){
vector<int> result = {};
dfs(root,result);
return result;
}
DFS深度搜索-从下到上(分治法)
输出结果相同,运行顺序不同
先经历到了最深的子树处,再返回合并成结果。
递归返回结果并合并。
vector<int> divideAndConquer(TreeNode* root) {
vector<int> result = {} ;
// 返回条件(null & leaf)
if (root == NULL) {
return result;
}
// 分治(Divide)
vector<int> left,right;
left = divideAndConquer(root->left);
right = divideAndConquer(root->right);
// 合并结果(Conquer)
result.push_back(root->val);
result.insert(result.end(),left.begin(),left.end());
result.insert(result.end(), right.begin(),right.end());
return result;
}
BFS广度搜索-层次遍历
先入先出,借助队列辅助计算
vector<int> levelOrder(TreeNode* root){
vector<int> result = {};
queue<TreeNode*> treeQueue;
TreeNode* node = NULL;
if(root == NULL){
return result;
}
treeQueue.push(root);
//左进 右进 存 出队
while(!treeQueue.empty()){
node = treeQueue.front();
if(node->left != NULL)
treeQueue.push(root->left);
if(node->right != NULL)
treeQueue.push(root->right);
result.push_back(node->val);
treeQueue.pop();
}
}
线索二叉树数据结构
线索二叉树目的 : 充分利用指针的作用,防止出现空指针浪费内存空间。将空指针改为指向前驱或者后继的线索(依据中序遍历)。
在经常需要遍历或查找节点需要按照某种顺序的时候可以使用。
可以再补充一个头结点,头结点左指向根节点,头结点右指向尾节点(中序最后一个); 中序第一个节点的前驱(左)指向头结点,中序最后一个节点(尾)指向头结点。这样整个二叉树将会变成一个双向链表。
此时可以从头结点(新建的那个)进行遍历: 如果有左子树经过左,如果无左子树则往右子树走(后驱节点)。遍历结果是中序遍历。
也可以从尾节点(最后一个,右下)进行遍历
typedef enum{Child,Thread} pointTag; //Child==0 代表指针指向孩子
//Thread==1 代表指针指向中序遍历的前驱或者后驱节点(左指前,右指后)
struct clueTreeNode{
int val;
pointTag lTag,rTag;
clueTreeNode *left;
clueTreeNode *right;
};
构造过程
构建二叉树时无法确定前驱后驱信息,故需要在中序遍历过程中进行线索化需要定义全局变量记录访问的上一个节点用于指定后继线索。
clueTreeNode* pre;
void clueCreateTree (clueTreeNode * root)
{
if(root == NULL)
return ;
clueCreateTree(root->left);
if(!root->left){
root->lTag = Thread;
root->left = pre;//第一次这里是NULL
}
if(!pre->right){
pre->rTag = Thread;
pre->right = root;
}
pre = root;
clueCreateTree(root->right);
}
双链表方式遍历过程
//T是头结点,左指向根节点,右指向中序遍历的最后一个节点
void linkInOrderTraversal(clueTreeNode* T){
vector<int> result;
clueTreeNode* ptr;
ptr = T->left;//根节点
while(ptr!= T){
while(ptr->lTag == Child)
ptr = ptr->left;
//operate...
result.push_back(ptr->val);
while(ptr->rTag == Thread && p->right!= T)//右节点指向的都是某个根节点或者右子树,如果是根节点则输出,子树则重新进迭代。
{
ptr = ptr->right;
result.push_back(ptr->val);
}
ptr = ptr->right;//终点或者有右子树的情况 出了上一个循环。
}
return;
}
哈夫曼树(带权路径的二叉树)
叶子节点带权,根节点到叶子节点的距离称为路径长度。哈弗曼(huffman)树为带权路径长度(WPL)最小的二叉树。
算法过程:
-
n个权值{w1,…,wn}构成n个二叉树集合F={T1,…Tn}此时每个二叉树Ti只有一个带权wi的节点
-
从F中选取权值最小的2个节点构造一棵新树,左小右大,根节点权重为左右子树权重和。
-
删除这两个树,构成的新树加入。
-
重复2,3直到F只剩一棵树。
哈夫曼编码
常用于数据压缩。根据使用字符的频率构造01编码。只需要保证所有数据点都在叶子节点上(即不会发生某一字符的编码是另一字符的前缀的情况,前缀编码)。即可使用哈夫曼编码表达数据。并且由于使用01编码代替原数据结构,达到了压缩的目的。一般左0右1
字母 A B C D E F 二进制字符 01 1001 101 00 11 1000
分治法
思想: 先处理局部,再合并结果:
常用场景
- 快速排序
- 归并排序
- 二叉树问题
分治法模板
- 递归返回条件
- 分段处理
- 合并结果
DFS深度搜索-从下到上(分治法) ,中就是一个典型的分治法模型。由返回条件,拆分情况处理,合并结果3部分组成。
分治法遍历二叉树
vector<int> divideAndConquTra(TreeNode* root){
vector<int> result = {};
//返回条件
if(root = NULL){
return result;
}
//分治
vector<int> left,right;
left = divideAndConquTra(root->left);
right = divideAndConquTra(root->right);
//合并 (操作一般在在这部分)
result.push_back(root->val);//操作
result.insert(result.end(),left.begin(),left.end());
result.insert(result.end(),right.begin(),right.end());
return result;
}
归并排序(分治法)
数组拆分成多个部分,各个部分逐个排序,然后再两两合并复原。
vector<int> mergeSort(vecrtor<int> nums){
//stop condition
if nums.size() <= 1{
return nums;
}
//divide
int mid = nums.size() / 2;
vector<int> temp_l(nums.begin(),nums.begin() + mid);
vector<int> left = mergeSort(temp_l);
vector<int> temp_r(nums.begin()+mid,nums.end());
vector<int> right = mergeSort(temp_r);
//merge operate in this part
vector<int> result = merge(left, right);
return result;
}
vector<int> merge(vector<int> left,vector<int> right){
int ind_l = 0, ind_r = 0;
vector<int> result;
for (ind_l<left.size() && ind_r < right.size()){
//谁的小谁先进
if (left[ind_l]<=right[ind_r]){//所以是稳定的算法
result.push_back(left[ind_l]);
ind_l--;
}
else{
result.push_back(right[ind_r]);
ind_r--;
}
} result.insert(result.end(),left.begin()+ind_l,left.end());
result.insert(result.end(),right.begin()+ind_r,right.end());
}
快速排序(分治法)
//调用语句
quickSort(nums,0,nums.size()-1);
vecrot<int> quickSort(vector<int>&nums,int start, int end){
//退出条件
if(start < end){
int pivot = partition(nums, 0,end);//确定分割点
//分割后左右操作
quickSort(nums,0,pivot-1);
quickSort(nums,pivot+1,end);
//因为是原地操作所以无需合并
}
//因为在数组中直接进行交换所以合并变成自动的了
}
int partition(vector<int>&nums,int start , int end){
//将比基准值小的放在左边即可,不需要从两边向中间搜索
int baseVal = nums[end];
int indi = start;
for(int indj=start; indj<end;intj++){
if (nums[indj] < baseVal){
swap(nums,indi ,indj);
indi++;
}
}
//此时baseVal归为到i
swap(nums,i,end);
return i;
}
//工具函数
void swap(vector<int> nums,int i ,int j){
int t = nums[i];
num[i] = nums[j];
nums[j] = t;
}
例题
题目部分参考:
104_二叉树最大深度
希望求得的类型值int,中间过程需要的类型值Int。可以一个函数搞定
int maxDepth(TreeNode* root) {
//返回条件
if(root == NULL){
return 0;
}
//divide
int left = maxDepth(root->left) + 1;
int right = maxDepth(root->right) +1 ;
//加一其实就是operation
//合并结果
return left>right?left:right;
}
110_平衡二叉树
平衡二叉树的判定标准是,每个节点的平衡因子的绝对值小于等于1。其中平衡因子=左子树最大深度-右子树最大深度。根据此条件,我们只需要计算每个节点的左右子树深度差是否符合条件即可。
其中计算当前节点是否平衡这个过程是最小操作单元。
操作单元:
- 左子树是不是平衡
- 右子树是不是平衡
- 该节点是不是平衡的(差是不是小于<=1)
优化思路: 仔细观察isBalanced和maxDepth函数,输入对象都是TreeNode对象。其中一个返回bool变量,另一个返回正数。因此其实可以将2者融合到一起。以-1代表子树是不平衡的,返回值为正数则代表深度。
不过一般工程不使用一个变量表示两种含义
bool isBalanced(TreeNode* root){
//return
if(root == NULL){
return true;//空节点肯定是平衡的
}
//divide
//左子树 右子树 分别计算深度
int depL = maxDepth(root->left);
int depR = maxDepth(root->right);
//merge
return ((isBalanced(root->left) && isBalanced(root->right)) &&((depL-depR<2)&&(depL-depR>-2)));
}
int maxDepth(TreeNode* root) {
//返回条件
if(root == NULL){
return 0;
}
//divide
int left = maxDepth(root->left) + 1;
int right = maxDepth(root->right) +1 ;
//加一其实就是operation
//合并结果
return left>right?left:right;
}
124_二叉树最大路径和
首先分析最大路径会是什么样子的,只有3种情况。
- 类似左斜树与其变形
- 类似右斜树与其变形
- 倒V字型的树
对于一个有子树的节点而言,他应该把与分别与左右子树结合后中较大的那个数值传上去。同时检查以它自身为根节点与左右子树结合所形成的的路径是否会更大。由此可以使用分治法。
操作单元:
- 获取左子树最大路径
- 获取右子树最大路径
- 左+右+根对比当前最大路径是否超越,如果超越则更新。返回根,跟+左,根+右中较大的那个数值同时以这个最大数值去刷最大值。
tips : 当divide中需要返回的数值意义与当前函数意义相同(本题中本质都是求深度),则可以直接使用当前函数迭代,否则需要写新函数并调用(上题中深度与平衡即不同。)
中间过程值int,目标类型int。但是内在含义不同,所以设定全局变量。或者需要通过辅助操作函数完成。此题中注意需要的结果存在全局变量maxPath中,而不是返回值maxPathNode中,所以需要多一个主函数main。
int maxPath = -100000;//设置一个全局变量用于储存最大路径,需要是足够小的负数
int maxPathSum(TreeNode* root){
if(root == NULL){
return 0;
}
//divide
int pathLeft = maxPath(root->left);
int pathRight = maxPath(root->left);
//merge
int pathLMR = pathLeft + pathRight + root->val;
if (pathLMR > maxPath){
maxPath = pathLMR;
}
int maxPathNode = root->val;
if(pathLeft>0 && pathLeft>pathRight){
maxPathNOde+=pathLeft;
}else if(pathRight>0){
maxPathNOde+=pathRight;
}
if (maxPathNode > maxPath){
maxPath = maxPathNode;
}
return maxPathNode;
}
236_二叉树最近公共祖先
操作单元:
- 检测左子树是否包含目标节点
- 检查右子树是否包含目标节点
- 自己是否是目标节点
判断逻辑,满足这个条件的节点实际上只有目标公共祖先节点
KaTeX parse error: Undefined control sequence: \and at position 10: (f_lson \̲a̲n̲d̲ ̲ ̲f_rson)\or[(roo…
有了判断逻辑则可以简单的写出来merge后的返回值具体内容。
本题中,主函数返回值类型,树指针。中间值类型,bool类型。如果不使用同变量多意义,则必须要使用辅助函数。
如果使用同变量多意义则可以使指针为NULL代表false,否则代表true
TreeNode* targetNode = NULL;
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
//主函数写个入口即可
dfs(root,p,q);
return targetNode;
}
bool dfs(TreeNode* root, TreeNode* p, TreeNode* q){
//check
if(root == NULL)
return false;
//divide
bool left = dfs(root->left,p,q);
bool right = dfs(root->right,p,q);
//merge and return
if( (left&&right) || ((left||right)&&(sameNode(root,p)||sameNode(root,q)) ){
targetNode = root;
}
return left||right||sameNode(root,p)||sameNode(root,q);
}
//通用函数
bool sameNode(TreeNode* p,TreeNode* q){
if(p->val == q->val)
return true;
else
return false;
}
106. 从中序与后序遍历序列构造二叉树
O(N)时间复杂度,空间复杂度为递归产生的额外空间,也为O(N).
class Solution {
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
return dfs(inorder,postorder,0,inorder.size(),0,postorder.size());
}
TreeNode* dfs(vector<int>& inorder, vector<int>& postorder,int inb,int ine,int postb, int poste){//左闭右开区间
if(inb>=ine) return nullptr;
//cout<<inb<<' '<<ine<<' '<<postb<<' '<<poste<<endl;
int rootval = postorder[poste-1];
TreeNode* root = new TreeNode(rootval);
if(ine-inb > 1){
auto miditer = find(inorder.begin()+inb , inorder.begin()+ine,rootval);
int mididx = miditer-inorder.begin();
//直接把这个root删了,这是为了
root->left = dfs(inorder, postorder, inb , mididx, postb, (postb - inb) + mididx);//不包括根
root->right = dfs(inorder, postorder , mididx+1, ine, (postb - inb) + mididx, poste-1);
}
return root;
}
};
迭代方法
迭代方法非常巧妙, 主要基于以下几点:
- 如果将中序遍历反序,则得到反向的中序遍历,即每次遍历右孩子,再遍历根节点,最后遍历做孩子。
- 如果将后序遍历反序,则得到反向的前序遍历,即每次遍历根节点,再遍历右孩子,最后遍历左孩子。
用一个栈 stack 来维护「当前节点的所有还没有考虑过左儿子的祖先节点」,栈顶就是当前节点。也就是说,只有在栈中的节点才可能连接一个新的左儿子。同时,我们用一个指针 index 指向中序遍历的某个位置,初始值为 n - 1,其中 n 为数组的长度。index 对应的节点是「当前节点不断往右走达到的最终节点」,这也是符合反向中序遍历的。
算法流程:
- 我们用一个栈和一个指针辅助进行二叉树的构造。初始时栈中存放了根节点(后序遍历的最后一个节点),指针指向中序遍历的最后一个节点;
- 我们依次枚举后序遍历中除了第一个节点以外的每个节点。如果 index 恰好指向栈顶节点,那么我们不断地弹出栈顶节点并向左移动 index,并将当前节点作为最后一个弹出的节点的左儿子;如果 index 和栈顶节点不同,我们将当前节点作为栈顶节点的右儿子;
- 无论是哪一种情况,我们最后都将当前的节点入栈。
其中有一个很有意思的特点,可以观察到后序遍历从后往前看,恰好是由根节点一直向右遍历的子树的逆序。
3
/ \
9 20
/ \ \
15 10 7
/ \
5 8
\
4
inorder = [15, 9, 10, 3, 20, 5, 7, 8, 4]
postorder = [15, 10, 9, 5, 4, 8, 7, 20, 3]
class Solution {
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if (postorder.size() == 0) {
return nullptr;
}
auto root = new TreeNode(postorder[postorder.size() - 1]);
auto s = stack<TreeNode*>();
s.push(root);
int inorderIndex = inorder.size() - 1;
for (int i = int(postorder.size()) - 2; i >= 0; i--) {
int postorderVal = postorder[i];
auto node = s.top();
if (node->val != inorder[inorderIndex]) {
node->right = new TreeNode(postorderVal);
s.push(node->right);
} else {
while (!s.empty() && s.top()->val == inorder[inorderIndex]) {
node = s.top();
s.pop();
inorderIndex--;
}
node->left = new TreeNode(postorderVal);
s.push(node->left);
}
}
return root;
}
};
分治法总结
-
如果分治后中间数据类型与主函数返回值类型相同,意义相同。一个函数即可搞定。
-
如果分治中间数据类型与函数返回值类型相同,意义不同。可以根据情况使用全局变量,辅助函数,使用同一变量表达多种意思(例如负数表示false,正数表示true同时表示长度)
-
分治中数据类型与函数返回值类型意义均不同,则使用辅助函数+全局变量,使用同一变量表达多种意思。
分治法做题步骤
-
形成操作单元,确定中间计算过程的数据类型
-
确定根据左右分支形成的逻辑
-
确定是否需要辅助函数
BFS层次遍历应用例题
102_二叉树逐层遍历
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> result = {};
if(root==NULL)
return result;
queue<TreeNode*> levelQueue;
levelQueue.push(root);
while(!levelQueue.empty()){
int len = levelQueue.size();
vector<int> levelVec = {};
for(int i=0;i<len;i++){
//左存 右存 取 出
TreeNode* node=levelQueue.front();
if(node->left!=NULL)
levelQueue.push(node->left);
if(node->right!=NULL)
levelQueue.push(node->right);
levelVec.push_back(node->val);
levelQueue.pop();
}
result.push_back(levelVec);
}
return result;
}
107_层次遍历自底向上
借用辅助栈
vector<vector<int>> levelOrderBottom(TreeNode* root) {
vector<vector<int>> result = {};
stack<vector<int>> tempres = {};
if(root==NULL)
return result;
queue<TreeNode*> levelQueue;
levelQueue.push(root);
while(!levelQueue.empty()){
int len = levelQueue.size();
vector<int> levelVec = {};
for(int i=0;i<len;i++){
//左存 右存 取 出
TreeNode* node=levelQueue.front();
if(node->left!=NULL)
levelQueue.push(node->left);
if(node->right!=NULL)
levelQueue.push(node->right);
levelVec.push_back(node->val);
levelQueue.pop();
}
tempres.push(levelVec);
}
while(!tempres.empty()){
result.push_back(tempres.top());
tempres.pop();
}
return result;
}
103_二叉树Z形遍历
void reverse(vector<int>& nums) {
for (int i=0,j=nums.size()-1 ; i<j;i = i+1,j=j-1){
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
vector<vector<int>> zigzagLevelOrder(TreeNode* root) {
vector<vector<int>> result = {};
if(root==NULL)
return result;
queue<TreeNode*> levelQueue;
levelQueue.push(root);
int level = 0;//代表层数
while(!levelQueue.empty()){
level++;
int len = levelQueue.size();
vector<int> levelVec = {};
for(int i=0;i<len;i++){
//左存 右存 取 出
TreeNode* node=levelQueue.front();
if(node->left!=NULL)
levelQueue.push(node->left);
if(node->right!=NULL)
levelQueue.push(node->right);
levelVec.push_back(node->val);
levelQueue.pop();
}
if (level&1)
result.push_back(levelVec);
else
{
reverse(levelVec);
result.push_back(levelVec);
}
}
return result;
}
98_验证二叉搜索树
二叉搜索树特征:
- 左子树都小于当前节点
- 右子树都大于当前节点
- 左右子树分别也是二叉搜索树
中间数据类型int+bool,所以需要辅助函数+全局变量/创建结构体的形式。
逻辑判断式
KaTeX parse error: Undefined control sequence: \and at position 10: (f_lson \̲a̲n̲d̲ ̲f_rson)\and(roo…
方法二:中序遍历储存,然后检查是否有序即可
struct resType{
bool isval;
TreeNode* maxval;
TreeNode* minval;
};
bool isValidBST(TreeNode* root) {
resType rootres = isvalue(root);
if (rootres.isval)
return true;
else
return false;
}
//核心函数
resType isvalue(TreeNode* root){
resType res;//最好设定一个初始化函数
//check
if(root==NULL){
res.isval = true;
res.maxval = NULL;
res.minval = NULL;
return res;
}
//divide
resType left = isvalue(root->left);
resType right = isvalue(root->right);
//merge
if((left.isval)&&(right.isval))
{
if((left.maxval ==NULL||left.maxval->val < root->val) &&
(right.minval == NULL||right.minval->val > root->val))
{
res.isval = true;
}
else{
res.isval = false;
}
}
else
{
res.isval = false;
}
//此时只要是false就可以退出了
if(res.isval){
if(right.maxval == NULL)
res.maxval = root;
else
res.maxval = right.maxval;
if(left.minval == NULL)
res.minval = root;
else
res.minval = left.minval;
}
return res;
}
701_搜索树插入
//只需要找到符合条件的叶子节点插入即可。可以论证,一定存在某个叶子节点可以将所需二叉树插入。
TreeNode* insertIntoBST(TreeNode* root, int val) {
if(!root)
return new TreeNode(val);
if(val > root -> val)
root -> right = insertIntoBST(root -> right, val);
else
root -> left = insertIntoBST(root -> left, val);
return root;
}
1530_好叶子节点
当需要储存一定的节点信息时,可以使用map配合数组的数据结构。后续遍历思路。
unordered_map<TreeNode* , vector<int> > stats;
//本题中stats用于存放距离信息
//stats[root][dist] 表示距离root这一节点,距离为dist的叶子节点的数目。
延申内容
延伸内容参考:
二叉树延伸树类型包括: 二叉搜索树、B树、B+树、AVL树、红黑树
常见应用场景:
B和B+数: 主要应用于数据库和文件系统中做索引
AVL树 : 平衡二叉树之一,应用较少。windows对进程地址空间管理应用了AVL
红黑树 : 平衡二叉树,广泛应用在C++STL的map和set中,java的TreeMap中。
二叉搜索树
二叉搜索树是延伸树的基础。
1.概念
平衡二叉树采用二分思想把数据按规则组装成树形结构数据,则在搜索数据时减少了无关数据检索,提升检索速度。
同时使用中序遍历就能得到有序的序列。
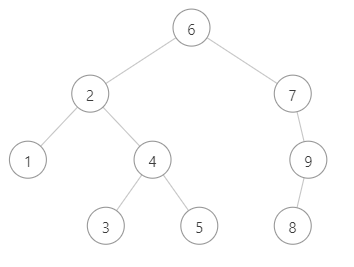
2.特点
- 任意节点左子树不为空,则左子树所有节点值均小于根节点值。
- 任意节点右子树不为空,则右子树的值均大于根节点的值。
- 任意节点的左右子树也分别是二叉查找树。
- 没有键值相等的点。
3.二叉搜索树存在的局限
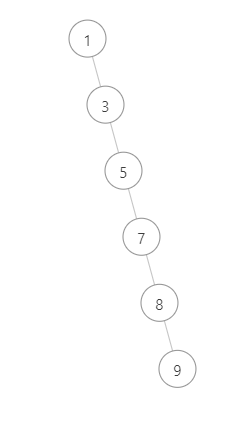
二叉搜索树在查找数据时,最好的时间复杂度是O(logN),最坏情况的时间复杂度是O(N)如上图所示。因为选择了最大或最小的节点做root,二叉搜索树退化为链表。节点排成一条直线。且实践中,平均增删查时间复杂度为O(N)。
如果将二叉搜索树转化为平衡二叉搜索树(AVL树),则增删查时间复杂度均可以保证在O(logn)完成。
| 操作 | 理想时间复杂度 | 最坏 |
|---|---|---|
| 插入 | O(logn) | O(n) |
| 查找 | O(logn) | O(n) |
| 增加 | O(logn) | O(n) |
| 删除 | O(logn) | O(n) |
4.实现代码
由于不需要转化为平衡二叉树,所以实现代码较为简单,此处忽略。
B树
概念
balanced-tree。B数又名平衡多路查找树(查找路径不止2个),不同于常见的二叉树,这是一种多叉树。又名B-树,数据库索引中会大量使用B树和B+树。
在大规模存储中,因为磁盘会有大量的数据,有可能没有办法一次将需要的所有数据加入到内存中,所以只能逐一加载磁盘页,每个磁盘页就对应一个节点,如果树节点存储的元素数量过少(比如二叉查找树)会导致由于树的深度过大造成磁盘IO读写频繁,降低查询效率。
所以很直接的解决方案就是减少树的深度,采用多叉树的结构。对于B树来说,B树很好的将树的高度降低了,这样就会减少IO查询次数,虽然一次加载到内存的数据变多了,但速度绝对快于AVL或是红黑树的。
特点
B树是一种平衡的多路查找树,一棵M阶B树,或为空树,或为满足下列特性的M叉树。(作者PS: 如果当前对于下列特点无法理解请继续看完增删改查具体过程,就都懂了)
- 每个节点最多只能有M个子树;且M>=2;M等于几也被称作几叉树
- 若根节点不是叶子节点,则至少有两个孩子;非叶子节点的子节点数>1且<=M,空树除外
- 所有节点关键字是按递增次序排列,并且遵循左小右大的原则。除了根节点以外,其余节点关键字的个数n满足ceil(m/2)-1<=n<=m-1。孩子数量则满足 [ceil(m/2),m]为关键字数量+1;
- 所有叶子节点都在同一层,这些叶子节点不再包含孩子的信息和指向孩子的指针(匹配就是直接取数据了,不匹配就是null,没有下一级索引。)
- 每个非终端节点包含信息如下
- (n, A0 , K1 , A1 , K2 , A3 … Kn,An)
- Ki
(1<=i<=n)为关键字,且关键字按升序排序 - 指针Ai
(0<=i<=n)指向子树的根节点 - 注意 :关键字的个数n(非子树个数)必须满足ceil(m/2)-1<=n<=m-1。
第3点可以通过反证法证明,注意需要通过删除操作去思考。该要求主要是为了能够实时降低高度,同时保证合并的便捷性。参考
一棵含n个结点的B树额高度也为O(logn),但可能比一棵红黑树高度小很多,因为他的分支因子较大。所以B树可以在O(logn)的时间内,实现各种增删查的操作。
增删改查具体过程
查找过程
这是一个3阶B树,第二层第三层都能很明显的看出来分了三叉,所以是三叉树。可以观察到,每个节点中最多只有(m-1)2个关键字(key)。
可以观察到,所有叶子节点都在同一层,注意:叶子节点不再包含key关键字的数据,仅包含数据信息。往往有时候也会将下图中的第三行的叶子节点省略,写到第二行就终止。
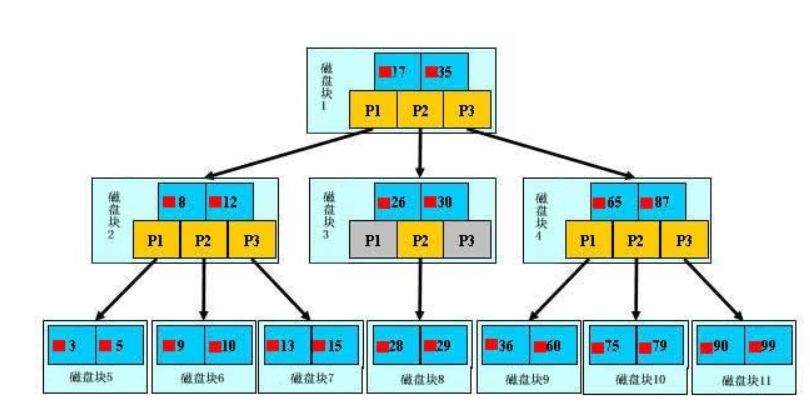
由上图可以观察到,每一个节点将会对应一个磁盘块,其中Pi就是指向各个磁盘块的指针,红点则是key同时对应着真实数据,如果在叶子节点仍未匹配上key,则会退出返回null搜索失败。
举例需要查找文件29的过程:
- 根据根节点指针找到磁盘块1,把磁盘块1导入内存。[磁盘IO第一次]
- 根据索引key,由于17<29<35,所以得到指针p2
- 根据p2找到磁盘块3,信息导入内存。[磁盘IO第二次]
- 根据算法得到26<29<30。得到指针p2。(注意此时如果目标key<26或者>30,得到的是空指针p1,p3直接寻找失败)
- 根据新p2找到磁盘块8,信息载入内存。[磁盘IO第三次]
- 在此时的内存中寻找key找到key29被匹配,确定该文件内存的磁盘地址。
分析上面过程可以发现,算法最多需要进行3次磁盘IO和3次内存查找操作。由于内存中的key查找是要有序表结构,所以使用二分方法可以提高效率。最慢的IO操作是影响整个B树查找效率的关键因素。最大时间复杂度与平均时间复杂度相同均是O(logn)也就是树的高度。观察到对比平衡二叉树的磁盘存储结构来查找,需要4-5次磁盘IO。而且文件越多,B树比平衡二叉树所用的磁盘IO操作次数将越少,所以效率也更高。
插入操作
定义一个5阶树,(平衡5路查找树;)希望将3、8、31、11、23、29、50、28插入构建5阶树
规则:
- 节点拆分规则: 组成一个5阶树,所以m=5,各个节点关键词数目<=4。所以当关键字>4就要进行拆分。
- 排序规则: 满足节点本身比左边节点大,比右边节点小的排序规则。
- 插入过程总是由底向上的,子树部分都会更快的比向上部分达到满状态,这是为了保持树的平衡。
插入过程: 组成一个4阶b树插入1-10,过程实际上就是不断的拆合并拆合并。
- 首先根据key值找到合适的叶子节点进行添加。
- 判断当前节点key个数是否<=m-1,满足则插入成功,否则第三步
- 以节点中间的key分裂左右两部分,然后将中间key插入到父节点中,这个key的左边指向分列后的左半部分,右边指向分裂后的右半部分。随后重复第二部进行检查。
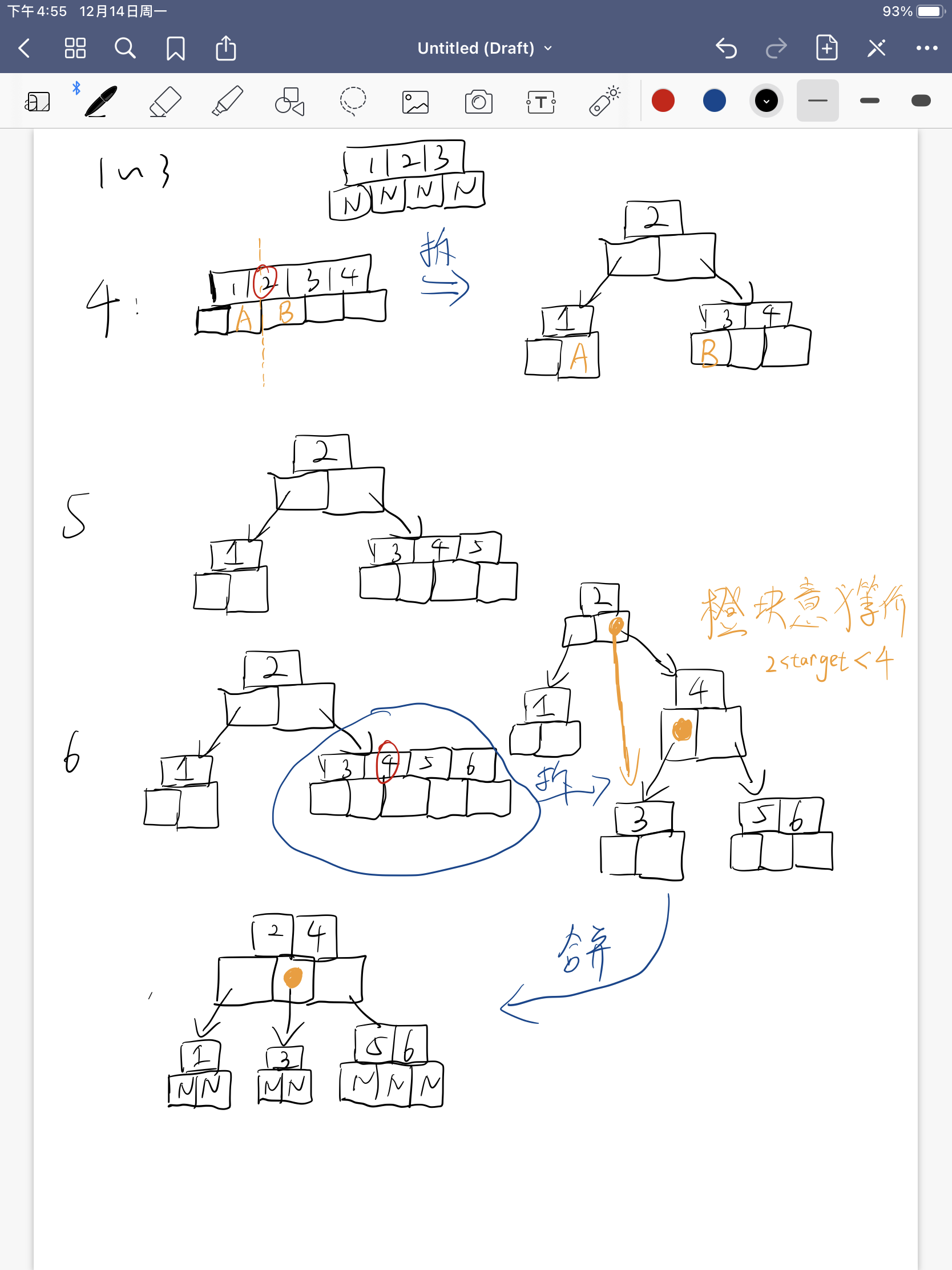
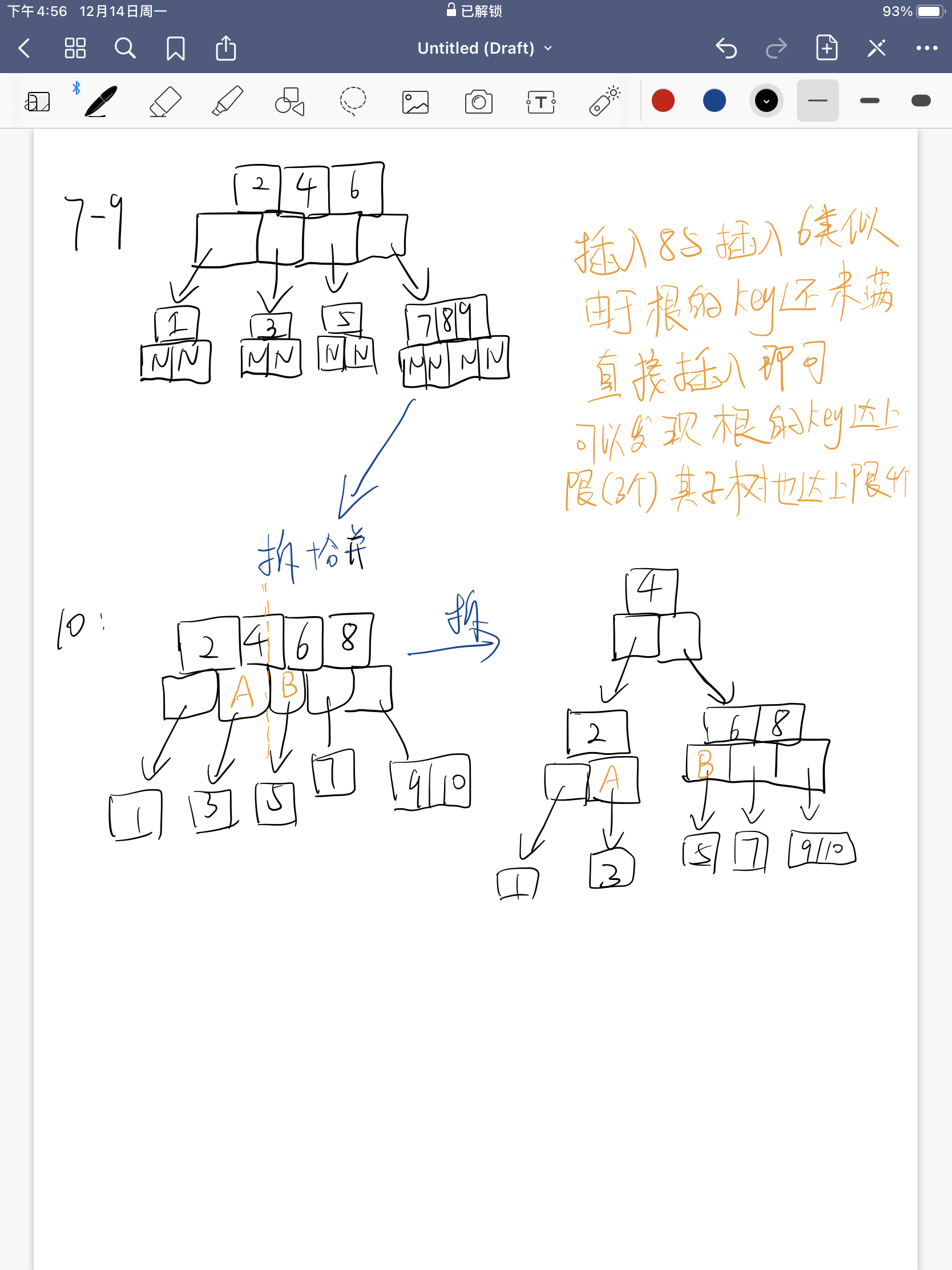
- 注意叶子节点底下的框中的指针都是空的,没有别的信息。图片中有些时候用
N标注 - 由此可以发现,子树的拆分都是源于当前节点key数目超过了最大值达到了m,那么自然所形成子树的key数目的最小值为ceil(m/2)-1,或者写作[(m-1)/2]。对应特点3,4的叙述。
- 插入节点时都是。优先从叶子节点插入。
删除操作
由于每个结点至少要有ceil(m/2)-1个关键字,首先计算出节点所需要的最小关键字数目,记做mink。
- 如果需要删除的key位于非叶子结点上,则用后继key(顺序的下一个大的key,后继key一定在叶子节点上。比如在插入的图片中删除4,后继key是5)覆盖要删除的key,然后在后继key所在的子支中删除该后继key。
- 如果此时原后继key所在节点的个数仍大于mink,删除结束。否则第三步
- 如果该节点兄弟节点(左右兄弟节点均可,必须相邻)个数大于mink,则父节点的key下移到这个节点(被删掉后继key的接地那)然后将兄弟节点的一个key向上移到父节点。删除操作结束,否则第四步
- 将父节点的key下移与当前节点(至多有mink-1个key)和他的兄弟节点(至多有mink个key)中的key合并(所以一定不会超过m-1个key),形成一个新的节点。则原父节点中的key的两个孩子指针就变成了一个新的孩子指针,指向新节点,随后重复第二步。
树的高度
**问题1:**已知n>=1,则任意一棵包含n个关键字高度为h、最小度数t>=2的B树T可以得到 h < = log t ( N + 1 ) / 2 h <= \log_t{(N+1)/2} h<=logt(N+1)/2
如果一棵B树的高度为h,其根节点至少包含一个关键字,而其他节点至少包含t-1个关键字(出度为t),这样可以得到逐层的节点数量。
第0层 节点数1
第1层 节点数2
第2层 节点数2t
第h层 节点数2*th-1
所以可以得到不等式 n > = 2 t h − 1 n>= 2t^h-1 n>=2th−1(其中h从0开始计算)
思考问题2: 一个含有N个总关键字数的m阶B树的最大高度是多少。(高度从1开始算起)
类似上一题的思考过程,只需要把出度t换为用m表达即可。t=ceil(m/2)所以可以得到
l = l o g c e i l ( m / 2 ) ( ( N + 1 ) / 2 ) + 1 l = log_{ceil(m/2)} ((N+1)/2) +1 l=logceil(m/2)((N+1)/2)+1其中l是包含了叶节点所在层的(如果不算就-1)
部分实现细节
B树的结构定义如下: 完整实现
#define MAXM 10 //B树的最大阶数
//数据结构定义
const int m = 4; //B树的阶数
typedef int KeyType; //KeyType为`关键字`类型 不是储存数据
const KeyType MaxK = m - 1; //节点关键字最大数量
const KeyType MinK = (m - 1) / 2; //节点关键字最小数量
struct BTNode {//B树节点类型
int keynum; //节点关键字个数
KeyType key[MaxK]; //关键字数组 key[0]不使用
BTNode* parent; //父节点指针
BTNode* ptr[MAXM]; //孩子结点指针数组
};
typedef struct { //B树查找结果类型
BTNode* ptr; //指向找到的结点
int i; //在结点中的关键字位置;
int tag; //查找成功与否标志
}Result;
B+树
概念
B+树时B树的一种升级版本,B+树查找的效率要比B树更高、更稳定。B+树是应文件系统所需而产生的一种B树的变形树(类似文件的目录一级一级索引,只有最底层的叶子节点(文件)保存数据.)
非叶子节点只保存索引,不保存实际的数据,数据全部都保存在叶子节点中。
特点
B+树存在两种定义方式,一种定义方式是关键字个数和孩子结点个数相同。这里采取维基百科上所定义的方式,即关键字个数比孩子结点个数小1,这种方式是和B树基本等价的。下图就是一颗阶数为4的B+树。
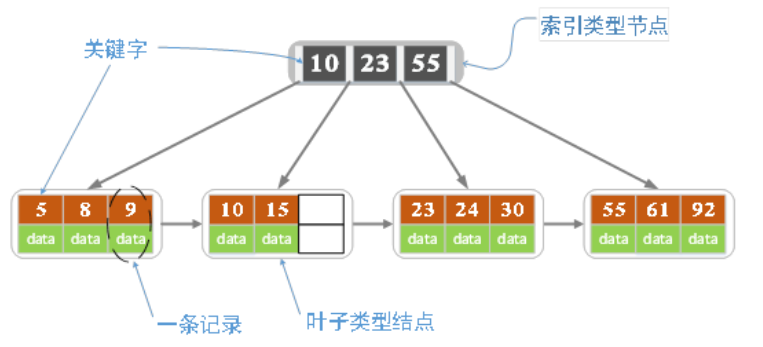
- B+树每个节点的子树个数比关键字个数多1。(存在争议)
- B+树有两类节点,内部节点和叶子节点。根节点本身既可以是内部节点也可以是叶子节点。
- 所有叶子节节点都包含了全部关键字信息,以及指向含有这些关键字记录的指针。叶子节点本身依关键字由小到大顺序连接,每隔叶子节点存有仙林叶子节点的指针。(B树的叶子节点是没有包含全部要找的信息的)
- 所有非叶子节点(内部节点)都可以看做是索引的一部分,各个节点中仅含有其子树根节点中最大(或最小)关键字。(B树非终端节点也要包含部分有效信息)
增删改查过程
过程中注意区分好一些默认情况即可,比如搜索到相等key时,选择对应右子树作为下一节点。(左也行,统一即可)
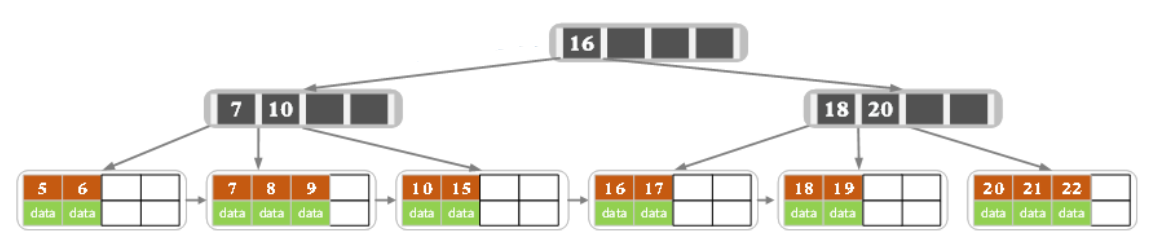
B树和B+树对比
1、B+树的层级更少:相较于B树,B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
2、B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
3、B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
4、B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是
如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
B+树相对于B树的最主要的优点:
- B+树只有叶子节点存放数据,而其他节点只存放索引,而B树每个节点都有Data域。所以相同大小的节点B+树包含的索引比B树的索引更多,(因为B树每个节点还有Data域)搜索索引的时候也会更快(因为Data域不用读到内存里)
- B+树的叶子节点是通过链表连接的,所以找到下限后能很快进行区间查询,比B树中序遍历快
AVL树(平衡二叉搜索树)
AVL树、红黑树均是对二叉搜索树的改进版本。
二叉搜索树的局限在于,如果选择了过大或者过小的关键字节点作为根节点,那么二叉搜索树会退化为链表,搜索时间复杂度退化为O(N)。
平衡二叉树通过引入平衡因子解决这一问题
特点
**平衡因子:**节点左右子树深度之差为当前节点的平衡因子。
在平衡二叉树中,节点的平衡因子只能取0,1,-1。分别对应左右等高,左高,右高。
AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过1,和红黑树相比,它是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过1)。
不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转是非常耗时的,由此可以知道AVL树适合用于插入删除次数比较少,但查找多的情况。
增删改查过程
增删改查的操作和二分搜索树相同,但是需要考虑对节点的平衡。例如一串单调递增的数据持续插入一棵树,就会导致树结构退化成链表。这是AVL就会对这个树进行旋转操作达到平衡。
增加删除修改均有可能触发旋转操作。分为以下4种情况。
下文引用自链接
1. LL右单旋转
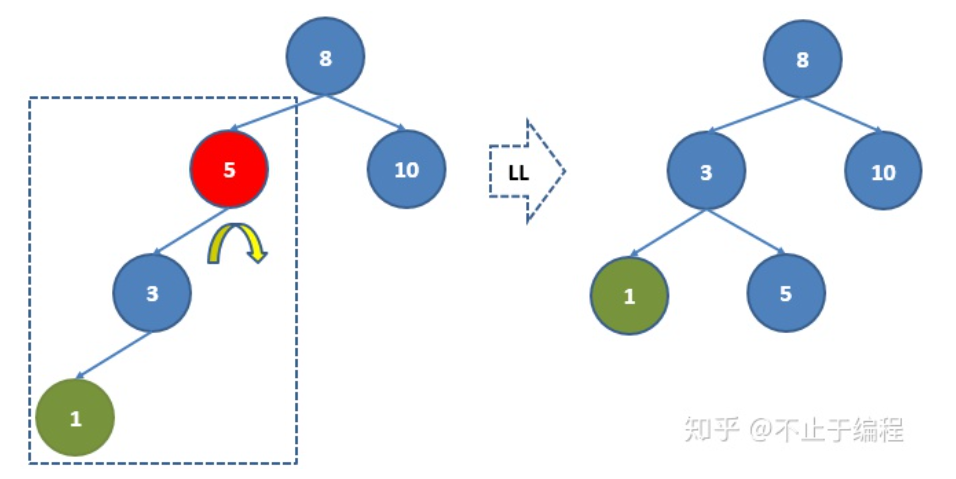
如图,8的左子树已经退化为链表,并且5,8这两个节点不再平衡,这时我们先找到深度最深的不平衡节点5,对节点5进行LL旋转操作,在如图的这种情况下,得到右图的结构
2. RR左单旋转
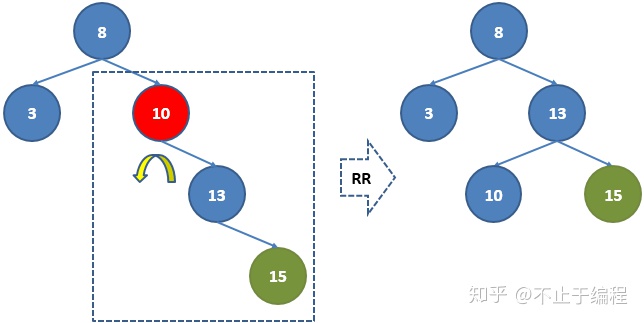
如图,当插入顺序为当插入顺序为8,3,10,13,15的时候,树的结构变成左边的样子,这时10节点和8节点已经不平衡,为了保持AVL的平衡,我们要对10节点进行RR旋转,如右图所示
3. LR先左后右
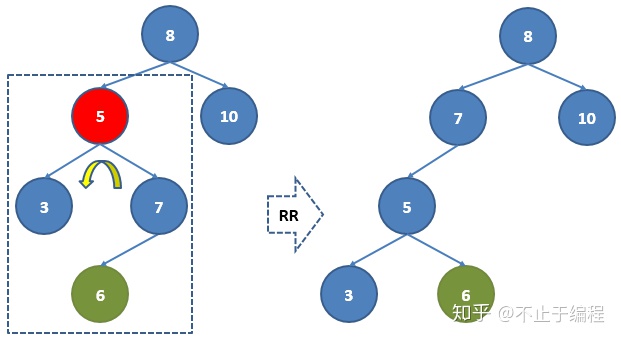
如图。5,8节点已经不平衡,这时要对5节点做平衡处理,首先将5进行RR左旋转,7的左节点也变为5的右节点。
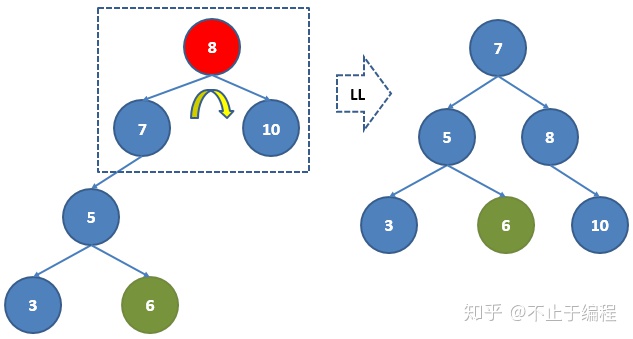
这时7,8还是不平衡的,对8进行右旋转,8的右节点也变为8的左节点,如图。
4. RL先右后左
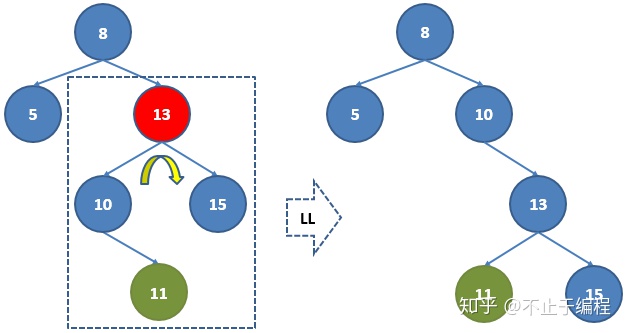
如左图,8,13节点不平衡,对13节点进行LL右旋转,得到右图
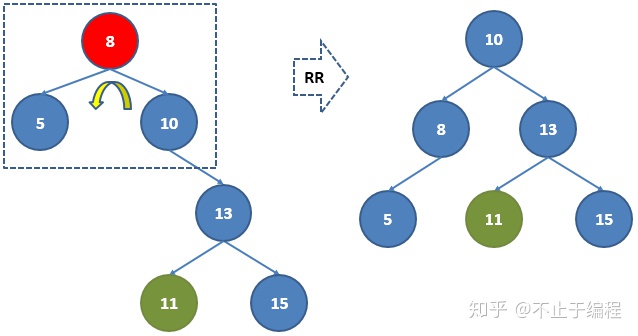
这时8,10是不平衡的,对8节点进行RR左旋转,得到右图。
AVL树局限性
由于维护高度平衡所付出的代价从中获得的效率收益还大,故而实际的应用不多。
如果仅仅是不频繁的插入与删除操作,对查找的要求较高,可以使用AVL树。
然而更多的地方是用追求局部而不是非常严格整体平衡的红黑树.。
红黑树
AVL树、红黑树均是对二叉搜索树的改进版本。
概念
一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是red或black(非红即黑)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍。它是一种弱平衡二叉树(由于是弱平衡,可以推出,相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索、插入、删除操作较多的情况下,使用红黑树效率更高。
特点
- 每个节点非红即黑
- 根节点是黑的
- 每个叶节点都是黑色的空节点(null),叶子节点不会存储数据
- 如果一个节点是红的, 那么他的两个子节点都是黑的(任何相邻节点不会同时为红色,红色节点会被黑色节点隔开)
- 对于任意节点而言,从该节点到达其可达叶子节点(null节点)的所有路径,都包含相同数目的黑色节点。
红黑树的高度始终保持在h=log(n)的高度
红黑树的增删改查的时间复杂度最坏为O(logN)
增删改查具体过程
在增删改的过程中,有可能会破坏红黑树的平衡(主要是特点4和5),为了保持红黑树平衡需要对红黑树进行旋转和变色操作。
左旋与右旋
这是红黑树平衡的两个基本操作。下图为示意图,a、b、r表示子树可以为空。
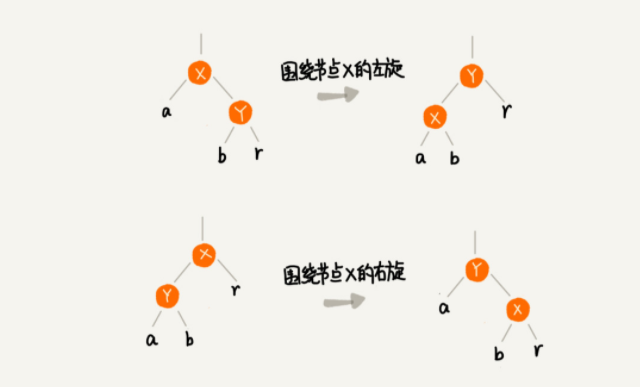
- 左旋操作即,选定某个节点作为中心点。将其右子树节点作为新父节点。原中心点的右子树调整为原右子树的左子树,原中心点的左子树和原右子树的右子树不变。
- 右旋操作。选定一个中心点。中心点左子树调整为新的父节点。原中心点左子树的右子树调整为中心点的左节点,原中心点右子树和原左子树的左节点不变。
插入操作的平衡操作
红黑树中插入节点必须是红色的。二叉查找树中新插入的节点都是放在叶子节点上的。
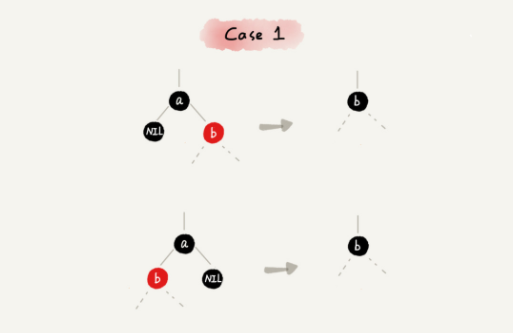
不需要进行操作的情况
- 插入节点的父节点是黑色的,什么都不用做,仍满足红黑树的定义。
- 如果插入的节点是根节点,那么直接改变颜色,变成黑色即可。
其余情况均需要进行调整,调整操作包括:左右旋转和改变颜色。
新节点插入之后,如果红黑树的平衡被打破,那么会有3种情况,分别按照情况进行调整即可。
以下将正在处理的节点叫做关注节点,关注节点会不断的发生变化,最开始的关注节点就是新插入的节点。父节点的兄弟称为叔叔节点,父节点的父节点称为祖父节点。
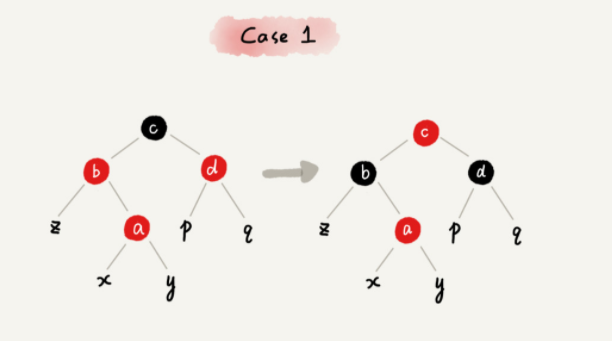
CASE1: 如果关注节点是a,叔叔节点d是红色(父节点也会是红色),依次执行下列操作。
-
将关注节点 a 的父节点 b、叔叔节点 d 的颜色都设置成黑色;
-
将关注节点 a 的祖父节点 c 的颜色设置成红色;
-
关注节点变成 a 的祖父节点 c;
-
跳到 CASE 2 或者 CASE 3。
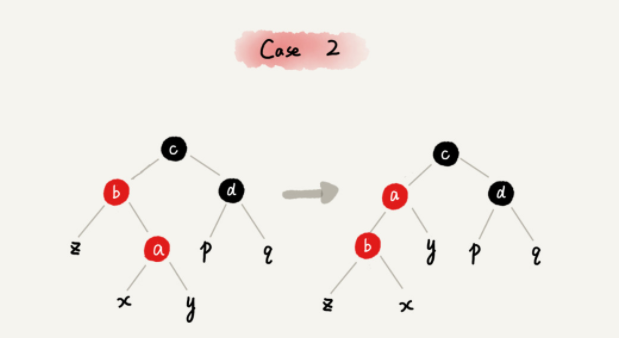
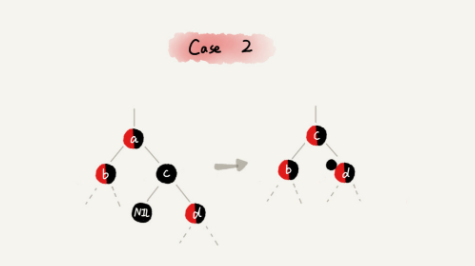
CASE2: 如果关注节点是a,叔叔节点d是黑色(父节点也会是黑色),关注节点 a 是其父节点 b 的右子节点。
-
关注节点变成节点 a 的父节点 b;
-
围绕新的关注节点b 左旋;
-
跳到 CASE 3
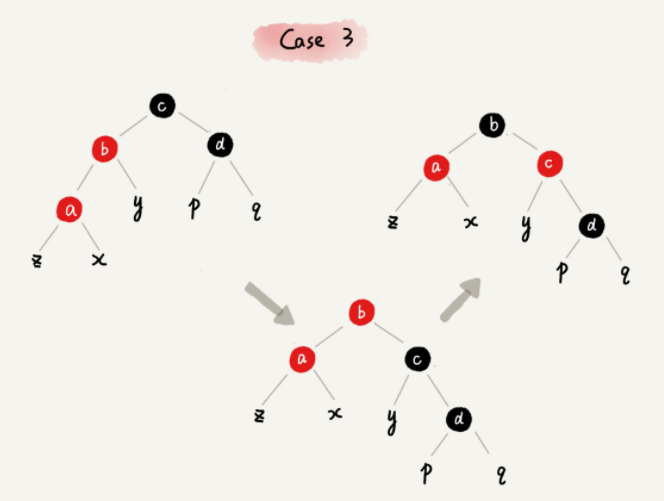
**CASE 3:**如果关注节点是 a,它的叔叔节点 d 是黑色,关注节点 a 是其父节点 b 的左子节点
-
围绕关注节点 a 的祖父节点 c 右旋;
-
将关注节点 a 的父节点 b、兄弟节点 c 的颜色互换。
-
调整结束
删除操作的平衡调整
红黑树的删除操作的平衡调整相对就要难多了。不过原理都是类似的,按照一定的规则去调整就行了。
删除操作的平衡调整分为两步,
- 第一步是针对删除节点初步调整。初步调整只是保证整棵红黑树在一个节点删除之后,仍然满足最后一条定义的要求,也就是说,每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点;
- 第二步是针对关注节点进行二次调整,让它满足红黑树的第三条定义,即不存在相邻的两个红色节点。
1. 针对删除节点初步调整
这里需要注意一下,红黑树的定义中“只包含红色节点和黑色节点”,经过初步调整之后,为了保证满足红黑树定义的最后一条要求,有些节点会被标记成两种颜色,“红 - 黑”或者“黑 - 黑”。如果一个节点被标记为了“黑 - 黑”,那在计算黑色节点个数的时候,要算成两个黑色节点。
**CASE 1:**如果要删除的节点是 a,它只有一个子节点 b,那我们就依次进行下面的操作:
- 删除节点 a,并且把节点 b 替换到节点 a 的位置,这一部分操作跟普通的二叉查找树的删除操作一样;
- 节点 a 只能是黑色,节点 b 也只能是红色,其他情况均不符合红黑树的定义。这种情况下,我们把节点 b 改为黑色;
- 调整结束,不需要进行二次调整。
**CASE 2:**如果要删除的节点 a 有两个非空子节点,并且它的后继节点就是节点 a 的右子节点 c。我们就依次进行下面的操作:
-
如果节点 a 的后继节点就是右子节点 c,那右子节点 c 肯定没有左子树。我们把节点 a 删除,并且将节点 c 替换到节点 a 的位置。这一部分操作跟普通的二叉查找树的删除操作无异;
-
然后把节点 c 的颜色设置为跟节点 a 相同的颜色;
-
如果节点 c 是黑色,为了不违反红黑树的最后一条定义,我们给节点 c 的右子节点 d 多加一个黑色,这个时候节点 d 就成了“红 - 黑”或者“黑 - 黑”;
-
这个时候,关注节点变成了节点 d,第二步的调整操作就会针对关注节点来做。
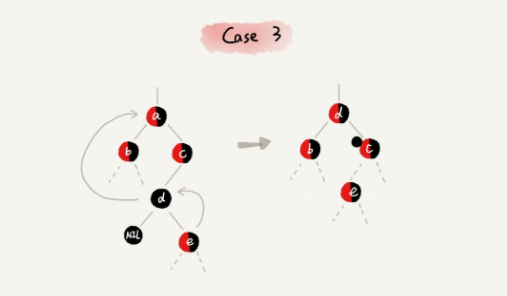
**CASE 3:**如果要删除的是节点 a,它有两个非空子节点,并且节点 a 的后继节点不是右子节点,我们就依次进行下面的操作:
- 找到后继节点 d,并将它删除,删除后继节点 d 的过程参照 CASE 1;
- 将节点 a 替换成后继节点 d;把节点 d 的颜色设置为跟节点 a 相同的颜色;
- 如果节点 d 是黑色,为了不违反红黑树的最后一条定义,我们给节点 d 的右子节点 c 多加一个黑色,这个时候节点 c 就成了“红 - 黑”或者“黑 - 黑”;
- 这个时候,关注节点变成了节点 c,第二步的调整操作就会针对关注节点来做。
2. 针对关注节点进行二次调整
经过初步调整之后,关注节点变成了“红 - 黑”或者“黑 - 黑”节点。针对这个关注节点,我们再分四种情况来进行二次调整。二次调整是为了让红黑树中不存在相邻的红色节点。
**CASE 1:**如果关注节点是 a,它的兄弟节点 c 是红色的,我们就依次进行下面的操作:
- 围绕关注节点 a 的父节点 b 左旋;
- 关注节点 a 的父节点 b 和祖父节点 c 交换颜色;
- 关注节点不变;
- 继续从四种情况中选择适合的规则来调整。
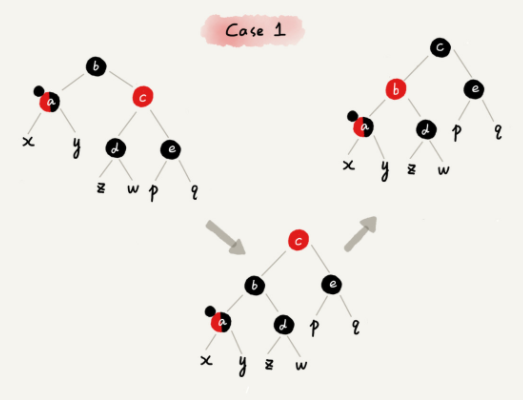
**CASE 2:**如果关注节点是 a,它的兄弟节点 c 是黑色的,并且节点 c 的左右子节点 d、e 都是黑色的,我们就依次进行下面的操作:
- 将关注节点 a 的兄弟节点 c 的颜色变成红色
- 从关注节点 a 中去掉一个黑色,这个时候节点 a 就是单纯的红色或者黑色;
- 给关注节点 a 的父节点 b 添加一个黑色,这个时候节点 b 就变成了“红 - 黑”或者“黑 - 黑”;
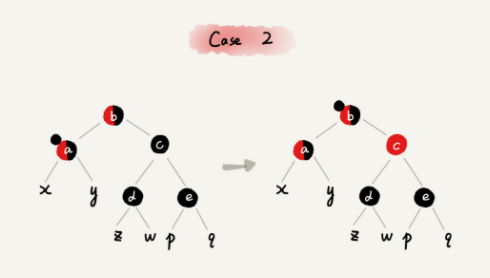
- 关注节点从 a 变成其父节点 b;继续从四种情况中选择符合的规则来调整。
**CASE 3:**如果关注节点是 a,它的兄弟节点 c 是黑色,c 的左子节点 d 是红色,c 的右子节点 e 是黑色,我们就依次进行下面的操作:
- 围绕关注节点 a 的兄弟节点 c 右旋;
- 节点 c 和节点 d 交换颜色;
- 关注节点不变;
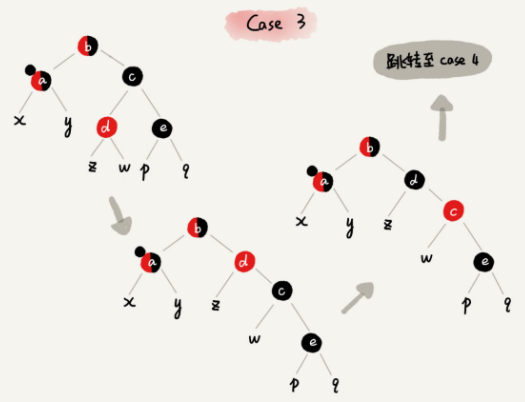
- 跳转到 CASE 4,继续调整。
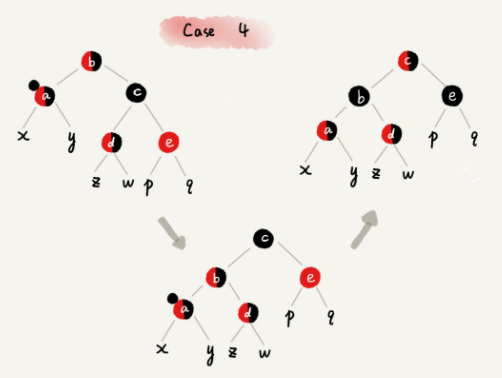
**CASE 4:**如果关注节点 a 的兄弟节点 c 是黑色的,并且 c 的右子节点是红色的,我们就依次进行下面的操作:
- 围绕关注节点 a 的父节点 b 左旋;
- 将关注节点 a 的兄弟节点 c 的颜色,跟关注节点 a 的父节点 b 设置成相同的颜色;
- 将关注节点 a 的父节点 b 的颜色设置为黑色;
- 从关注节点 a 中去掉一个黑色,节点 a 就变成了单纯的红色或者黑色;
- 将关注节点 a 的叔叔节点 e 设置为黑色;
- 调整结束。
为什么红黑树的定义中,要求叶子节点是黑色的空节点?
之所以有这么奇怪的要求,其实就是为了实现起来方便。只要满足这一条要求,那在任何时刻,红黑树的平衡操作都可以归结为我们刚刚讲的那几种情况。
通过一个例子来解释一下。假设红黑树的定义中不包含刚刚提到的那一条“叶子节点必须是黑色的空节点”,我们往一棵红黑树中插入一个数据,新插入节点的父节点也是红色的,两个红色的节点相邻,这个时候,红黑树的定义就被破坏了。那我们应该如何调整呢?
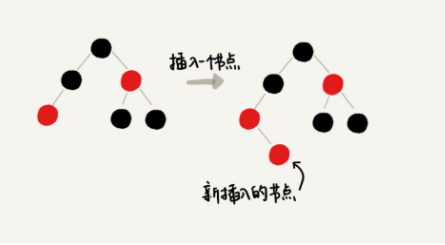
会发现,这个时候,我们前面在讲插入时,三种情况下的平衡调整规则,没有一种是适用的。但是,如果我们把黑色的空节点都给它加上,变成下面这样,你会发现,它满足 CASE 2 了。
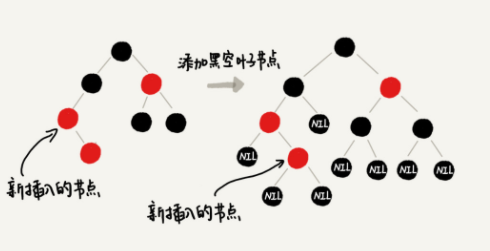
如果为了适配各种情况而修改规则,当然可以解决,但是规则没有原来简介了。
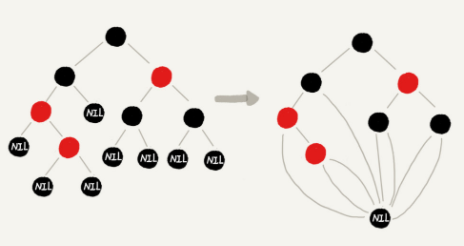
而且虽然我们在讲解或者画图的时候,每个黑色的、空的叶子节点都是独立画出来的。实际上,在具体实现的时候,我们只需要像下面这样,共用一个黑色的、空的叶子节点就行了。
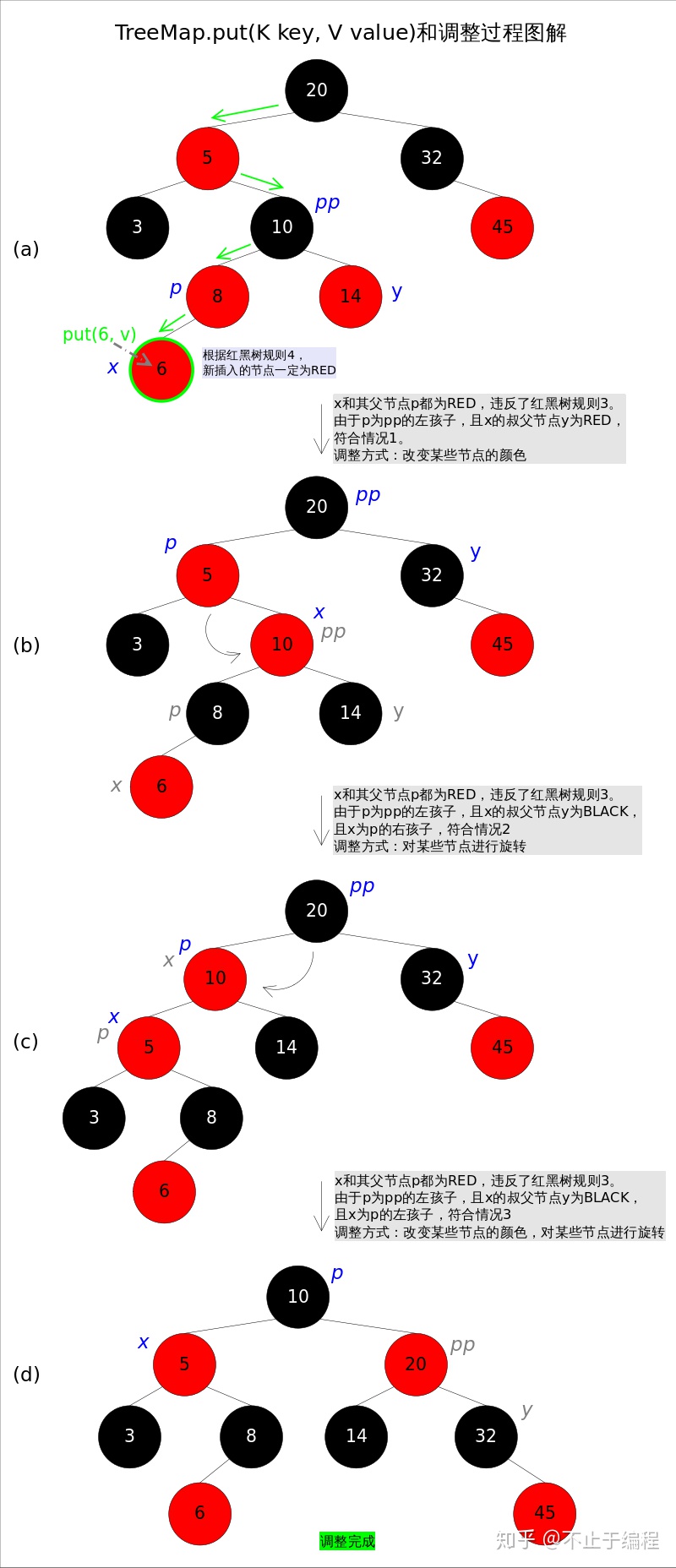
自平衡案例
红黑树总结
红黑树确实难学,但其实不必去记忆它的平衡调整策略。看懂过程,没有知识盲点,就算是掌握了这部分内容了。毕竟实际的软件开发并不是闭卷考试,当真的需要实现一个红黑树的时候,可以对照步骤,一点一点去实现。
红黑树的操作过程。
第一点,把红黑树的平衡调整的过程比作魔方复原,不要过于深究这个算法的正确性。只需要明白,只要按照固定的操作步骤,保持插入、删除的过程,不破坏平衡树的定义就行了。
第二点,找准关注节点,不要搞丢、搞错关注节点。因为每种操作规则,都是基于关注节点来做的,只有弄对了关注节点,才能对应到正确的操作规则中。在迭代的调整过程中,关注节点在不停地改变,所以,这个过程一定要注意,不要弄丢了关注节点。
第三点,插入操作的平衡调整比较简单,但是删除操作就比较复杂。针对删除操作,我们有两次调整,第一次是针对要删除的节点做初步调整,让调整后的红黑树继续满足第四条定义,“每个节点到可达叶子节点的路径都包含相同个数的黑色节点”。但是这个时候,第三条定义就不满足了,有可能会存在两个红色节点相邻的情况。第二次调整就是解决这个问题,让红黑树不存在相邻的红色节点。
常见面试问题
以下全引用自万字大总结,一文搞懂二叉搜索树、B树、B+树、AVL树、红黑树
二叉搜索树、B树、B+树、AVL树、红黑树的常见面试题
1)为什么设计红黑树
红黑树通过它规则的设定,确保了插入和删除的最坏的时间复杂度是O(log N) 。
红黑树解决了AVL平衡二叉树的维护起来比较麻烦的问题,红黑树,读取略逊于AVL,维护强于AVL,每次插入和删除的平均旋转次数应该是远小于平衡树。
因此:
相对于要求严格的AVL树来说,红黑树的旋转次数少,所以对于插入、删除操作较多的情况下,我们就用红黑树。但是,只是对查找要求较高,那么AVL还是较优于红黑树.
2)B树的作用
B树大多用在磁盘上用于查找磁盘的地址。因为磁盘会有大量的数据,有可能没有办法一次将需要的所有数据加入到内存中,所以只能逐一加载磁盘页,每个磁盘页就对应一个节点,而对于B树来说,B树很好的将树的高度降低了,这样就会减少IO查询次数,虽然一次加载到内存的数据变多了,但速度绝对快于AVL或是红黑树的。
3)B树和 B+树的区别
B/B+树用在磁盘文件组织、数据索引和数据库索引中。其中B+树比B 树更适合实际应用中操作系统的文件索引和数据库索引,因为: 1、B+树的磁盘读写代价更低 B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2、B±tree的查询效率更加稳定 由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3、B树在元素遍历的时候效率较低
由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库**,只需要扫一遍叶子结点即可**,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。在数据库中基于范围的查询相对频繁,所以此时B+树优于B树。
4)B树和红黑树的区别
最大的区别就是树的深度较高,在磁盘I/O方面的表现不如B树。
要获取磁盘上数据,必须先通过磁盘移动臂移动到数据所在的柱面,然后找到指定盘面,接着旋转盘面找到数据所在的磁道,最后对数据进行读写。磁盘IO代价主要花费在查找所需的柱面上,树的深度过大会造成磁盘IO频繁读写。根据磁盘查找存取的次数往往由树的高度所决定。
所以,在大规模数据存储的时候,红黑树往往出现由于树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下。在这方面,B树表现相对优异,B树可以有多个子女,从几十到上千,可以降低树的高度。
5)AVL树和红黑树的区别
红黑树的算法时间复杂度和AVL相同,但统计性能比AVL树更高。
1、红黑树和AVL树都能够以O(log2 n)的时间复杂度进行搜索、插入、删除操作。 2、由于设计,红黑树的任何不平衡都会在三次旋转之内解决。AVL树增加和删除可能需要通过一次或多次树旋转来重新平衡这个树。
在查找方面: 红黑树的性质(最长路径长度不超过最短路径长度的2倍),其查找代价基本维持在O(logN)左右,但在最差情况下(最长路径是最短路径的2倍少1),比AVL要略逊色一点。 AVL是严格平衡的二叉查找树(平衡因子不超过1)。查找过程中不会出现最差情况的单支树。因此查找效率最好,最坏情况都是O(logN)数量级的。
所以,综上: AVL比RBtree更加平衡,但是AVL的插入和删除会带来大量的旋转。 所以如果插入和删除比较多的情况,应该使用RBtree, 如果查询操作比较多,应该使用AVL。
AVL是一种高度平衡的二叉树,维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树。当然,如果场景中对插入删除不频繁,只是对查找特别有要求,AVL还是优于红黑的。
6)数据库为什么使用B树,而不使用AVL或者红黑树
我们假设B+树一个节点可以有100个关键字,那么3层的B树可以容纳大概1000000多个关键字(100+101100+101101*100)。而红黑树要存储这么多至少要20层。所以使用B树相对于红黑树和AVL可以减少IO操作
7)mysql的Innodb引擎为什么采用的是B+树的索引方式
B+树只有叶子节点存放数据,而其他节点只存放索引,而B树每个节点都有Data域。所以相同大小的节点B+树包含的索引比B树的索引更多(因为B树每个节点还有Data域)
还有就是B+树的叶子节点是通过链表连接的,所以找到下限后能很快进行区间查询,比B树中序遍历快
8)红黑树 和 b+树的用途有什么区别?
- 红黑树多用在内部排序,即全放在内存中的,STL的map和set的内部实现就是红黑树。
- B+树多用于外存上时,B+也被成为一个磁盘友好的数据结构。
9)为什么B+树比B树更为友好
- 磁盘读写代价更低 树的非叶子结点里面没有数据,这样索引比较小,可以放在一个blcok(或者尽可能少的blcok)里面。避免了树形结构不断的向下查找,然后磁盘不停的寻道,读数据。这样的设计,可以降低io的次数。
- 查询效率更加稳定 非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
- 遍历所有的数据更方便 B+树只要遍历叶子节点就可以实现整棵树的遍历,而其他的树形结构 要中序遍历才可以访问所有的数据。
版权说明
文章中所有原文链接汇总如下:
-
极客时间<数据结构与算法之美>
大根堆
小根堆
字典树



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









