







【ML】用遗传规划进行因子挖掘
原创 Yud. 2AMquant 2024-04-02 07:30 广东
本文使用deap pkg进行基于遗传算法的因子挖掘。并对代码进行部分修改。
自定义了多个算子如下,同样包括时间序列相关的算子:
|
winsorize(x) |
kurtdev(df,window) |
|
if_then_else(condition, out1, out2) |
ts_zscore(df,window) |
|
ts_sum(df, window=10) |
ts_mad(df,window) |
|
sma(df, window=10) |
max_item(x,y) |
|
stddev(df, window=10) |
min_item(x,y) |
|
correlation(x, y, window=10) |
negative(x) |
|
add(x,y) |
minmaxscale(df,window) |
|
sub(x,y) |
normscale(df,window) |
|
mul(x,y) |
decay_linear(x,window) |
|
div(x,y) |
covariance(x, y, window=10) |
|
power(x,constant = 2) |
ts_rank(x, window=10) |
|
log(x) |
ts_min(df, window=10) |
|
abs(x) |
ts_max(df, window=10) |
|
sign_(x) |
delta(df, window=1) |
|
inv_(x) |
ts_argmax(x, window=10) |
|
sqrt(x) |
ts_argmin(x, window=10) |
|
sigmiod_(x) |
ts_coef(x,window) |
|
ts_prod(x,window = 10) |
ts_intercept(x,window) |
|
ts_range(df,window =10) |
ema(x,window) |
|
ts_median(x0,window = 10) |
sin(x) |
|
delay(df,window = 10) |
cos(x) |
|
ts_percent(df,window = 10) |
tan(x) |
|
ts_pct(df,window) |
ts_r_avg(df,window) |
| skewdev(df,window) |
signpower(x,constant) |
根据所需因子的结果预期,定义编码方式、变异规则、适应度需求。使用表达式树PrimitiveTree定义(编码)个体,在集合PrimitiveSet中定义个体所涉及的上述算子。在变异规则上限制复杂度/树的深度。
对于时间序列算子,为了使因子更具备解释意义,移动窗口的选择范围是(5,10,22),分别代表的时间区间是周,两周,一月。
为保证量纲一致,每个挖掘出的因子都会先进行zscore处理,随后根据优化目标进行遗传优化。(优化问题中其实也可以使用多目标优化,但想到各优化目标之间的配比权重其实也是个优化目标。综合考虑后暂时采用单一目标。)
实验过程结果展示如下:
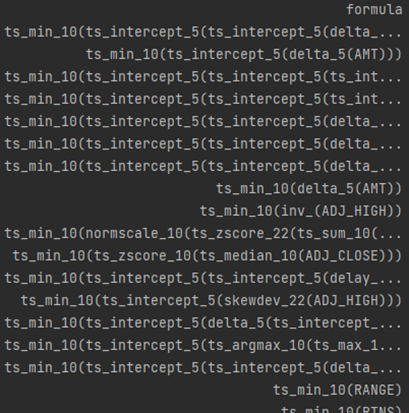
(以夏普为优化目标)
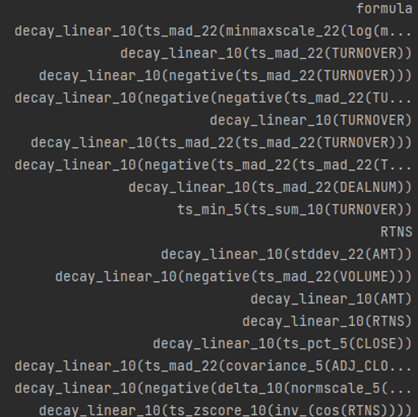
(以IC为优化目标)
将上述因子进行因子检测,筛选出alpha因子。使用最高分组收益率作为因子收益计算绩效指标,并使用换手率评估交易成本。
以IC为优化目标的结果之一:
decay_linear_10(ts_mad_22(TURNOVER))
|
样本内 |
样本外(半年) | |
|
年化收益 |
19.58% |
15.61% |
|
年化波动率 |
17.05% |
11.43% |
|
夏普 |
1.1486 |
1.3652 |
|
IC |
0.0419 |
0.0432 |
|
IR |
0.2730 |
0.2833 |
|
换手率 |
0.1409 |
0.1496 |
|
走势 |
| |
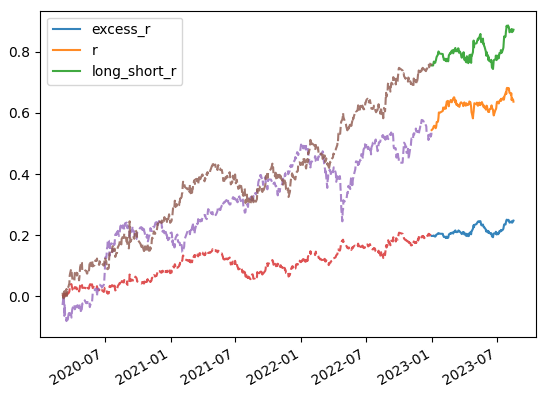
综上,使用GP挖掘因子可以拓展思维,引入非线性运算,实现归纳演绎。
经过观察挖掘出来的因子,大多跟股票的成交情况有关,而差分、截距、斜率时间序列相关的算子被应用的较多,或者进行了类似2/3阶导的操作,捕捉成交(高维度)变化的信号。
可为人工挖掘因子提供灵感,或者定义新的算子。

















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









