



在本章中,我们将简要介绍读、写、导入和导出数据的各种方法。读取器摄取单个数据集,而导入器创建整个场景,其中可能包括一个或多个数据集、演员、灯光、相机等。编写者将单个数据集输出到磁盘(或流),而导出者输出整个场景。在某些情况下,您可能希望接口的数据不是在标准的VTK格式,或在VTK支持的任何其他常见格式。在这种情况下,您可能希望将数据视为字段数据,并在可视化管道中将其转换为数据集。
12.1读者
我们在第44页的“阅读器源对象”中看到了如何使用阅读器将数据导入可视化管道。使用类似的方法,我们可以读取许多其他类型的数据。使用读取器需要实例化读取器,提供文件名,并在管道的某个地方调用Update()。
VTK库中有许多不同的阅读器,它们都是用来读取文件和生成数据结构的,这些数据结构可以被可视化管道的其余部分处理和可视化。阅读器则是任何vtkAlgorithm,它不需要输入连接,并且知道如何读取文件以生成vtkDataObjects。
在VTK中有许多不同的阅读器,因为有许多重要的科学数据文件格式。存在不同的文件格式是为了永久保存不同类型的数据,如结构化、非结构化、多边形、表格或图形。作为VTK的用户,一个重要的任务是确定哪些VTK数据结构与您感兴趣的数据相对应,然后找到一个读取您使用的文件以产生该结构的阅读器。本节介绍一些可用的阅读器。
在进入读者名单之前,有一些要点需要注意。对于所有VTK数据结构类型,存在一个或两个VTK本地阅读器类。这些类是在开发或扩展相应数据类型的同时编写的。旧的本机阅读器类读取文件。扩展名为“。vt?”,而较新的扩展名为“。vt?”读取基于XML的文件(其中?描述类型)。新旧格式都支持以文本或二进制格式写入数据。较新的格式更复杂,但它完全支持最新的vtk功能,包括命名数组,32位/ 64位编码,流处理和所有最新的数据结构。这两种格式都有并行处理扩展,它们是用元文件实现的,元文件指的是要独立读取的外部串行文件。请参阅第469页的“VTK文件格式”。,以了解本机文件格式的详细信息。
本章列出了每种数据类型的VTK本机读取器,以及与更知名的第三方文件格式接口并产生该类型的读取器的选择。
最后请注意,如果没有合适的阅读器,可以用c++编写一个,或者使用第249页“使用字段数据”中描述的技术来强制最通用的阅读器vtkprogramabledataobjectsource的输出为适当的数据类型。
数据对象读取器
•vtkProgrammableDataObjectSource -一个算法,执行用户指定的功能,以产生一个vtkDataObject..用户指定的函数可以写入以任何特定的文件格式读取,或者在不读取任何文件的情况下程序地生成数据。
•vtkGenericDataObjectReader -读取一个“。“vtk”文件,所有vtk的数据结构的遗留文件格式,并填充一个vtkDataObject或最具体的子类与文件中定义的结构。例如,如果.vtk文件包含表格数据,则阅读器将生成vtkTable;如果选择的.vtk文件包含非结构化网格,则阅读器将生成vtkUnstructuredGrid。该类读取头信息以找出文件中的数据类型,然后将处理的其余部分委托给下面描述的更具体的类之一。
•vtkDataObjectReader -读取一个“。并使用与Field相关的数组填充DataObject。这与vtkGenericDataObjectReader的不同之处在于,它不会生成最适合文件内容的特定数据结构,而总是生成最通用的数据结构,vtkDataObject。
数据集阅读器
这些读取器产生通用的vtkDataSet作为输出。通常,阅读器需要Update()调用来确定创建了哪种具体的vtkDataSet子类。
•vtkDataSetReader -像vtkDataObjectReader,但该类仅限于更常见的vtkDataSet子类。
•vtkGenericEnSightReader -像vtkDataSetReader,但读取并行vtk (.pvtk)格式文件,这是引用几个传统的。
•vtk文件的元文件,这意味着由不同的处理器同时处理。
图像和卷阅读器
•vtkStructuredPointsReader -读取”。vtk“遗留格式文件包含图像数据
•vtkXMLImageDataReader -读取”。“vtkXMLPImageDataReader - reads”是一种更新的基于XML的VTK文件格式。pvti“基于XML的引用单个并行分区文件”。
•vtkImageReader -读取原始图像数据。由于文件格式是原始转储,您必须指定图像范围,字节顺序,标量类型等,以便从文件中获得正确的结果。
•vtkDICOMImageReader -读取DICOM(医学数字成像和通信)图像
•vtkgesignereader -读取GE信号成像文件
•vtkMINCImageReader -基于netCDF的阅读器MINC(蒙特利尔神经学研究所中心)文件
•vtkSTLReader -读取立体光刻文件
•vtkJPEGReader -读取JPEG文件
•vtkPNMReader -读取PNM文件
•vtkTIFFReader -读取TIFF文件
直线网格阅读器
•vtkreclineargridreader -读取”。vtk“包含直线网格数据的旧格式文件”。vtr“基于XML的VTK文件
•vtkXMLPRectilinearGridDataReader - reads”。pvtr“引用个体的基于XML的并行分区文件”。
•vtkSESAMEReader -读取洛斯阿拉莫斯国家实验室状态数据库方程文件(http:// t1web.lanl.gov/doc/SESAME_3Ddatabase_1992.html)
结构化网格阅读器
•vtkStructuredGridReader -读取”。vtk“包含结构化网格数据的旧格式文件
•vtkXMLStructuredGridReader - reads”“基于XML的VTK文件•vtkXMLPStructuredGridReader -读取”。“基于XML的并行分区文件引用个体”。
•vtkPLOT3DReader -读取NASA PLOT3D结构化CFD计算数据集(http://people.nas.nasa.gov/~rogers/plot3d/intro.html)
多边形数据阅读器
•vtkPolyDataReader -读取”。vtk“包含多边形数据的旧格式文件
•vtkXMLPolyDataReader - reads”。“基于XML的VTK文件
•vtkXMLPPolyDataReader - reads”。“基于XML的并行分区文件,单独引用”。
•vtkOBJReader -读取Wavefront .obj文件
•vtkPLYReader -读取斯坦福大学.ply文件
•vtkparticlerreader -读取粒子与标量数据x,y,z,值在ascii或二进制格式
•vtkSimplePointsReader -示例阅读器读取以X Y Z浮点形式写入的点,并在vtkPolyData (PD)中生成边缘和vtk_vertex单元格
•vtkSLACParticleReader -读取与斯坦福线性加速器中心处理工具约定编写的netCDF文件。输出对应于空间中的粒子。这与vtkNetCDFReader的不同之处在于,尽管两者都理解NetCDF格式,但该阅读器添加了适合特定科学研究领域的约定。
非结构化网格阅读器
•vtkUnstructuredGridReader -读取”。
•vtkXMLUnstructuredGridReader - reads”。“基于XML的VTK文件
•vtkXMLPUnstructuredGridReader - reads”。引用个体的基于XML的并行分区文件。vtu“文件
•vtkCosmoReader读洛斯阿拉莫斯国家实验室宇宙学二进制数据格式文件•vtkExodusReader——读桑迪亚国家实验室《出埃及记》格式文件
•vtkPExodusReader并行处理专业化的vtkExodusReader每个处理器从文件中读取自己的部分街区同时
•vtkChacoReader——读取桑迪亚查科图包格式文件和生产UnstructuredGrid数据
•vtkPChacoReader——读取桑迪亚查科图格式包在一个处理器上并在内部分配部分数据到其他并行处理器
图形阅读器
•vtkGraphReader - read”。vtk“遗留格式文件包含一般图形数据
•vtkTreeReader - read”。
•vtkXMLTreeReader -读取基于XML的vtk文件
•vtkChacoGraphReader -读取以桑迪亚查科图形包格式编写的文件。这与vtkChacoReader的不同之处在于,它产生一个vtkUndirectedGraph,而不是更面向空间的vtkUnstructuredGrid。
•vtkPBGLGraphSQLReader -从并行Boost图形库SQL数据库中读取顶点和边表
•vtkSQLGraphReader -从SQL数据库中读取顶点和边表
•vtkRISReader -读取RIS格式的书目引文文件并生成vtkTable (TA)
表格阅读器
•vtkTableReader - - read”。
•vtkDelimitedTextReader -读取文本文件,其中换行分隔每一行和单个用户指定的分隔符字符,例如,逗号,制表符或空格,分隔列
•vtkFixedWidthTextReader -读取文本文件中,换行分隔每一行,其中每列有一个固定的宽度
•vtkISIReader -阅读书目引用记录在ISI格式
复合数据阅读器
vtkCompositeDataSet的具体子类vtkMultiPieceDataSet, vtkHierarchicalBoxDataSet,和vtkMultiBlockDataSet是VTK的方式表示复合数据对象,或数据对象包含其他数据对象。这些结构在并行处理、自适应细化模拟和表示相关部分之间的层次关系方面非常有用。几个读取器导入复杂数据并产生复合数据输出。复合数据的内容可以是上述原子类型中的任何一种或全部,和/或其他复合数据对象。
•vtkXMLCompositeDataReader -及其子类读取基于XML的VTK文件。这些文件的标准扩展名包括“。vtm”、“。“Vth”和“。vtb”。
•vtkExodusIIReader -读取Sandia Exodus2格式文件并直接生成MultiBlock数据集。这与vtkExodusReader的不同之处在于,输出不转换为单个vtkUnstructuredGrid,当数据是常规的时,这可能会节省内存。
•vtkexodusiireader -并行处理专业化的前面每个处理器独立,并同时读取自己的子集块
•vtkOpenFOAMReader -读取文件写在OpenFOAM(计算流体动力学)格式
12.2 写入器
写入器输出vtkDataObjects到文件系统。写入器是任何vtkAlgorithm,它接受vtkDataObject,通常由连接到写入器输入的vtkAlgorithm产生,并以某种标准格式将其写入文件系统。有许多不同的作家在VTK,因为有许多重要的文件格式。
通常,使用写入器涉及设置输入并指定和输出文件名(有时是文件名),如下所示。
vtkPolyDataWriter writer
writer SetInput [aFilter GetOutput]
writer SetFileName “outFile.vtk”
writer SetFileTypeToBinary
writer Write
传统的VTK编写器为您提供了编写二进制(SetFileTypeToBinary())或ASCII(SetFileTypeToASCII())文件的选项。(注意:二进制文件可能无法在计算机之间传输。VTK负责字节交换,但不处理64位和32位计算机之间的传输。)
VTK XML编写器还允许您以二进制(SetDataModeToBinary())或ASCII (SetDataModeToAscii())编写;和附加二进制模式也可用(SetDataModeToAppended())。VTK XML阅读器和写入器除了处理字节交换之外,还处理32位和64位计算机之间的数据传输。
以下是可用的编写器列表。
数据对象写入器
•vtkgenericdataobjectwwriter -写入任何类型的vtkDataObject到文件中的遗留”。Vtk”文件格式。
•vtkdataobjectwwriter—只写vtkDataObject的字段数据在遗产”。Vtk”文件格式。
数据集作家
•vtkdatasetwwriter -写入任何类型的vtkDataSet的文件在遗产”。
•vtkpdatasetwwriter -写入任何类型的vtkDataSet文件的遗产”。
•vtkXMLDataSetWriters -写入任何类型的vtkDataSet到文件在较新的基于XML的“。vt?”格式。
图像和卷作家
•vtkStructuredPointsWriter -写图像数据的遗产”。
•vtkXMLImageDataWriter -写入基于XML的图像数据”。vtkMINCImageWriter -一个基于netCDF的作家为MINC(蒙特利尔神经学研究所中心)的文件
•vtkpostscriptwwriter -写入后脚本格式的图像
•vtkJPEGWriter -写入JPEG格式
•vtkPNMWriter -写入PNM格式
•vtkTIFFWriter -写入TIFF格式
直线型网格书写器
•vtkreclinimagewriter -写入传统的直线网格”。vtk“format
•vtkxmlreclineargridwriter -写基于XML的直线网格”。
•vtkXMLPRectilinearGridWriter -一个并行处理专业化的前面
结构化网格编写器
•vtkStructuredGridWriter -写结构化网格的遗留”。vtk“format
•vtkXMLStructuredGridWriter -基于XML编写结构化网格”。
•vtkXMLPStructuredGridWriter -前面的多边形数据写入器的并行处理专业化
多边形数据写入器
•vtkPolyDataWriter -写多边形数据的遗留”。vtk“格式
•vtkXMLPolyDataWriter -写多边形数据在XML的基础上”。
•vtkXMLPPolyDataWriter -一个并行处理专业化的前面
•vtkSTLWriter -写立体光刻文件
•vtkIVWriter -写入OpenInventor 2.0格式
•vtkPLYWriter -作家斯坦福大学”。vtkUnstructuredGridWriter -在遗留文件中写入。vtk“format
非结构化网格编写器
•vtkXMLUnstructuredGridWriter -写基于XML的非结构化数据”。
•vtkXMLPUnstructuredGridWriter -一个并行处理专业化的前面
•vtkensightwwriter -写vtk非结构化网格数据作为一个EnSight文件
图形写入器
•vtkGraphWriter -写vtkGraph数据到一个文件的遗产”。vtk" format
•vtkTreeWriter -写入vtkTree数据到一个文件在legacy "。vtk" format
表格写入器
•vtkTableWriter -写入vtkTable数据到文件在legacy "。
复合数据编写器
•vtkXMLCompositeDataWriter(及其子类)-复合数据结构的编写器,包括分层框(多分辨率图像数据)和多块(相关数据集)数据类型
•vtkExodusIIWriter -以ExodusII格式编写复合数据
12.3 导入器
导入器接受包含多个数据集和/或组成场景的对象的数据文件(即,灯光,相机,演员,属性,变换矩阵等)。导入器将生成vtkRenderWindow和/或vtkRenderer的实例,或者您可以指定它们。如果指定了,导入器将创建灯光、摄像机、演员等,并将它们放置到指定的实例中。否则,它将根据需要创建vtkRenderer和vtkRenderWindow的实例。下面的例子展示了如何使用vtkImporter的实例(在这种情况下是vtk3dsimporter - import 3D Studio文件)。这个Tcl脚本取自VTK/Examples/IO/Tcl/flamingo。如图12-1所示。
vtk3DSImporter importer
importer ComputeNormalsOn
importer SetFileName \
"$VTK_DATA_ROOT/Data/iflamigm.3ds"
importer Read
set renWin [importer GetRenderWindow]
vtkRenderWindowInteractor iren
iren SetRenderWindow $renWin
可视化工具包支持以下导入器。(注意,超类vtkImporter可用于开发新的子类。)
•vtk3DSImporter -导入3D Studio文件
•vtkVRMLImporter -导入VRML 2.0版本文件
12.4 导出器
导出器以各种格式输出场景。vtkexporters的实例接受vtkRenderWindow的实例,并写出导出格式支持的图形对象
vtkRIBExporter exporter
exporter SetRenderWindow renWin
exporter SetFilePrefix “anExportedFile”
exporter Write
上面显示的vtkRIBExporter以RenderMan格式写入多个文件。FilePrefix实例变量用于写入一个或多个文件(几何和纹理映射,如果有的话)。
可视化工具包支持以下导出器。
•vtkGL2PSExporter -导出一个场景作为PostScript文件使用GL2PS
•vtkivexport -导出发明人场景图
•vtkobjexport -导出Wavefront .obj文件
•vtkoogleexporter -导出场景到GeomView OOGL格式
•vtkRIBExporter -导出RenderMan文件
•vtkVRMLExporter -导出VRML 2.0版本文件
•vtkpovexporters -导出到文件格式的持久性视觉光线追踪器
(www.povray.org)
•vtkX3DExporter -导出为X3D格式(基于XML的3d场景格式类似于VRML)
12.5创建硬拷贝
创建信息图像是VTK的主要目标,并记录你所做的事情,保存图像和一系列图像(即动画)是重要的。本节描述创建图形输出的各种方法。
保存图像
保存图像的最简单方法是使用vtkWindowToImageFilter,它获取渲染窗口的输出缓冲区并将其转换为vtkImageData。然后可以使用其中一个映像写入器保存该映像(有关更多信息,请参阅第164页的“写入器”)。这里有一个例子
vtkWindowToImageFilter w2i
w2i SetInput renWin
vtkJPEGWriter writer
writer SetInput [w2i GetOutput]
writer SetFileName "DelMesh.jpg"
writer Write
请注意,在保存图像时可以使用渲染窗口的离屏模式。离屏模式可以通过设置OffScreenRenderingOn()来打开。
保存大型(高分辨率)图像
通过屏幕捕获或保存渲染窗口保存的图像在质量上有很大差异,这取决于计算机上支持的图形硬件和屏幕分辨率。为了提高图像质量,您可以尝试两种方法。第一种方法允许您使用成像管道来渲染图像的各个部分,然后将它们组合成非常高分辨率的最终图像。我们将其称为平铺成像。第二种方法需要外部软件来执行高分辨率渲染。我们将其称为RenderMan解决方案。
平铺的呈现。通常我们希望保存的图像的分辨率大于计算机硬件的分辨率。例如,在1280 × 1024的计算机显示器上生成4000 × 4000像素的图像并不容易。可视化工具包通过类vtkRenderLargeImage使这一点变得微不足道。这个类将渲染过程分解为单独的部分,每个部分只包含最终图像的一部分。这些碎片被组装成最终的图像,可以使用VTK图像编写器之一保存到文件中。下面是它是如何工作的(Tcl脚本取自VTK/ Examples/Rendering/Tcl/RenderLargeImage.tcl)。
vtkRenderLargeImage renderLarge
renderLarge SetInput ren
renderLarge SetMagnification 4
vtkTIFFWriter writer
writer SetInputConnection [renderLarge GetOutputPort]
writer SetFileName largeImage.tif
writer Write
Magnification实例变量(一个整数值)控制放大输入渲染器当前图像的程度。如果渲染器的图像大小为(400,400),放大系数为5,则最终图像的分辨率为(2000,2000)。在本例中,生成的图像被写入到具有vtkTIFFWriter实例的文件中。当然,也可以使用其他写入器类型。
RenderMan。RenderMan是一款高质量的软件渲染系统,目前由制作了著名电影《玩具总动员》的图形动画公司皮克斯(Pixar)销售。RenderMan是一个商业软件包。在撰写本文时,单个计算机RenderMan Maya渲染插件的许可费用为995美元。幸运的是,至少有一个价格适中的(或者免费的,如果你是非商业的)RenderMan兼容系统,你可以下载和使用:Pixie (Blue Moon Ray Tracer)。Pixie比RenderMan慢,但它也提供了RenderMan没有的几个功能。
在前面的章节(第166页的“出口商”)中,我们看到了如何导出RenderMan .rib文件(以及相关的纹理)。你可以使用vtkRIBExporter中的SetSize()方法来调整RenderMan生成的图像的大小。此方法向肋骨文件添加一行,使RenderMan(或RenderMan兼容系统,如Pixie)创建大小为(xres, yres)像素的输出TIFF图像。
12.6创建影片文件
除了写一系列的图像,VTK也有三个类,让你直接写电影文件:vtkAVIWriter, vtkFFMPEGWriter和vtkMPEG2Writer。两者都是vtkGenericMovieWriter的子类。vtkAVIWriter使用微软的多媒体API来创建电影文件,因此只能在Windows机器上使用。FFMPEG和MPEG2媒体格式在所有平台上都可用,但由于许可证不兼容,仅以源代码格式提供,而不是在VTK库本身。要使用这些接口类中的任何一个,您必须手动下载并在您的机器上编译库,然后配置和构建VTK以链接到它们。在http://www.vtk.org/VTK/resources/software.html#addons上可以找到这样做的说明和库源代码。这两个类都采用2D vtkImageData作为输入-通常是vtkWindowToImageFilter的输出。这些类中的重要方法如下。
•Start -调用这个方法一次开始写一个电影文件。
•写入——每添加一帧到电影文件中调用这个方法一次。
•End -调用此方法一次以结束写入过程。
与其他编写器类似,电影编写器也有SetInput和SetFileName方法。下面是编写100帧电影文件的示例Tcl代码。
vtkMPEG2Writer writer
writer SetInput [aFilter GetOutput]
writer SetFileName "movie.mpg"
writer Start
for {set i 0} {$i < 100} {incr i} {
writer Write
# modify input to create next frame of movie
…
}
writer End
12.7处理现场数据
很多时候数据的组织形式不同于在VTK中发现的形式。例如,您的数据可能是表格的,甚至可能是更高维度的。有时你希望能够重新排列你的数据,将一些数据赋值为标量,一些赋值为点坐标,一些赋值为其他属性数据。在这种情况下,VTK的字段数据和允许您操作字段数据的过滤器是必不可少的。
要介绍这个主题,一个具体的例子是有用的。在上一章(第156页的“高斯溅刻”)中,我们看到了一个示例,该示例需要编写自定义代码来读取表格数据文件,然后提取指定的数据以形成点和标量(查看VTK/Examples/ modeling /Cxx/finance.cxx中的ReadFinancialData()函数)。虽然这在本例中工作得很好,但它确实需要大量的工作并且不是很灵活。
在下面的示例中,我们将使用字段数据做同样的事情。数据采用以下表格格式。
NUMBER_POINTS 3188
TIME_LATE
29.14 0.00 0.00 11.71 0.00 0.00 0.00 0.00
0.00 29.14 0.00 0.00 0.00 0.00 0.00 0.00
....
MONTHLY_PAYMENT
7.26 5.27 8.01 16.84 8.21 15.75 10.62 15.47
5.63 9.50 15.29 15.65 11.51 11.21 10.33 10.78
此格式对以下每个字段重复:支付贷款的延迟时间(TIME_LATE);贷款的月供(MONTHLY_PAYMENT);贷款剩余本金(UNPAID_PRINCIPAL);贷款的原始金额(LOAN_AMOUNT);贷款利率(INTEREST_RATE);借款人的月收入(MONTHLY_INCOME)。这6个字段组成了一个3188行6列的矩阵。
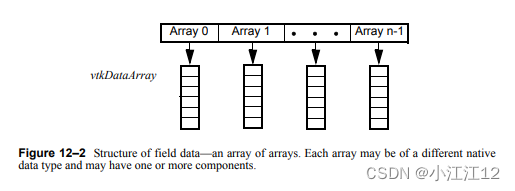
我们从解析数据文件开始。类vtkProgrammableDataObjectSource对于定义特殊的输入方法很有用,而不必修改VTK。我们所需要做的就是定义一个函数来解析文件并将结果放入VTK数据对象中。(回想一下,vtkDataObject是vtkDataArray Array 0 Array 1 Array n-1图12-2字段数据的结构——数组的数组。每个数组可以具有不同的本机数据类型,并且可以具有一个或多个组件。读写数据(数据表示的最一般形式)读取数据是这个例子中最具挑战性的部分,在VTK/Examples/ datamanmanipulation /Tcl/FinancialField.tcl中找到。
set xAxis INTEREST_RATE
set yAxis MONTHLY_PAYMENT
set zAxis MONTHLY_INCOME
set scalar TIME_LATE
# Parse an ascii file and manually create a field. Then construct a
# dataset from the field.
vtkProgrammableDataObjectSource dos
dos SetExecuteMethod parseFile
proc parseFile {} {
global VTK_DATA_ROOT
# Use Tcl to read an ascii file
set file [open "$VTK_DATA_ROOT/Data/financial.txt" r]
set line [gets $file]
scan $line "%*s %d" numPts
set numLines [expr (($numPts - 1) / 8) + 1 ]
# Get the data object's field data and allocate
# room for 4 fields
set fieldData [[dos GetOutput] GetFieldData]
$fieldData AllocateArrays 4
# read TIME_LATE - dependent variable
# search the file until an array called TIME_LATE is found
while { [gets $file arrayName] == 0 } {}
# Create the corresponding float array
vtkFloatArray timeLate
timeLate SetName TIME_LATE
# Read the values
for {set i 0} {$i < $numLines} {incr i} {
set line [gets $file]
set m [scan $line "%f %f %f %f %f %f %f %f" \
v(0) v(1) v(2) v(3) v(4) v(5) v(6) v(7)]
for {set j 0} {$j < $m} {incr j} {timeLate InsertNextValue $v($j)}
}
# Add the array
$fieldData AddArray timeLate
# MONTHLY_PAYMENT - independent variable
while { [gets $file arrayName] == 0 } {}
vtkFloatArray monthlyPayment
monthlyPayment SetName MONTHLY_PAYMENT
for {set i 0} {$i < $numLines} {incr i} {
set line [gets $file]
set m [scan $line "%f %f %f %f %f %f %f %f" \
v(0) v(1) v(2) v(3) v(4) v(5) v(6) v(7)]
for {set j 0} {$j < $m} {incr j} {monthlyPayment InsertNextValue
$v($j)}
}
$fieldData AddArray monthlyPayment
# UNPAID_PRINCIPLE - skip
while { [gets $file arrayName] == 0 } {}
for {set i 0} {$i < $numLines} {incr i} {
set line [gets $file]
}
# LOAN_AMOUNT - skip
while { [gets $file arrayName] == 0 } {}
for {set i 0} {$i < $numLines} {incr i} {
set line [gets $file]
}
# INTEREST_RATE - independent variable
while { [gets $file arrayName] == 0 } {}
vtkFloatArray interestRate
interestRate SetName INTEREST_RATE
for {set i 0} {$i < $numLines} {incr i} {
set line [gets $file]
set m [scan $line "%f %f %f %f %f %f %f %f" \
v(0) v(1) v(2) v(3) v(4) v(5) v(6) v(7)]
for {set j 0} {$j < $m} {incr j} {interestRate InsertNextValue $v($j)}
}
$fieldData AddArray interestRate
# MONTHLY_INCOME - independent variable
while { [gets $file arrayName] == 0 } {}
vtkIntArray monthlyIncome
monthlyIncome SetName MONTHLY_INCOME
for {set i 0} {$i < $numLines} {incr i} {
set line [gets $file]
set m [scan $line "%d %d %d %d %d %d %d %d" \
v(0) v(1) v(2) v(3) v(4) v(5) v(6) v(7)]
for {set j 0} {$j < $m} {incr j} {monthlyIncome InsertNextValue $v($j)}
}
$fieldData AddArray monthlyIncome
}
现在我们已经读取了数据,我们必须将输出vtkDataObject中包含的字段数据重新排列成适合可视化管道(即vtkGaussianSplatter)处理的形式。这意味着创建vtkDataSet的子类,因为vtkGaussianSplatter将vtkDataSet的实例作为输入。需要两个步骤。首先,使用过滤器vtkDataObjectToDataSetFilter将vtkDataObject转换为vtkDataSet类型。然后,使用vtkRearrangeFields和vtkAssignAttribute将字段从vtkDataObject移动到新创建的vtkDataSet的vtkPointData,并将其标记为活动标量字段。
vtkDataObjectToDataSetFilter do2ds
do2ds SetInputConnection [dos GetOutputPort]
do2ds SetDataSetTypeToPolyData
do2ds DefaultNormalizeOn
do2ds SetPointComponent 0 $xAxis 0
do2ds SetPointComponent 1 $yAxis 0
do2ds SetPointComponent 2 $zAxis 0
vtkRearrangeFields rf
rf SetInputConnection [do2ds GetOutputPort]
rf AddOperation MOVE $scalar DATA_OBJECT POINT_DATA
vtkAssignAttribute aa
aa SetInputConnection [rf GetOutputPort]
aa Assign $scalar SCALARS POINT_DATA
aa Update
这里使用了几种重要的技术。
1. 除非另有指示(或者除非他们修改vtkDataObject),否则所有过滤器将其输入vtkDataObject传递到其输出。我们将在下游过滤器中利用这一点。
2. 我们设置vtkDataObjectToDataSetFilter来创建vtkPolyData的实例作为其输出,其中字段数据的三个命名数组作为x、y和z坐标。在这种情况下,我们使用vtkPolyData,因为数据是非结构化的,只由点组成。
3. 我们将字段值标准化为(0,1)之间的范围,因为轴的范围足够不同,我们通过用数据填充整个空间来创建更好的可视化效果。
4. 过滤器vtkRearrangeFields复制/移动vtkDataObject, vtkPointData和vtkCellData之间的字段。在本例中,添加了一个操作,将名为$scalar的字段从输入的数据对象移动到输出的点数据。
5. 过滤器vtkAssignAttribute将字段标记为属性。在本例中,名为$scalar的字段(在点数据中)被标记为活动标量字段。
set__component()方法是vtkDataObjectToDataSetFilter的关键方法。这些方法根据名称和组件编号引用字段data中的数据数组。(回想一下,一个数据数组可以有多个组件。)也可以从数据数组中指定(min,max)元组范围,并执行规范化。但是,请确保提取的元组的数量与数据集结构中的项数(例如,点或单元格的数量)相匹配。
有几个相关的类可以执行类似的操作。这些类可用于在字段数据、数据集和属性数据之间任意地重新排列数据。
•vtkDataObjectToDataSetFilter—创建vtkDataSet,从vtkDataObject的字段数据中选择的数组中构建数据集的几何,拓扑和属性数据。
•vtkDataSetToDataObjectFilter -转换vtkDataSet到vtkFieldData包含在vtkDataObject。
•vtkRearrangeFields -在字段数据、点数据和单元格数据之间移动/复制字段。
•vtkAssignAttribute -将字段标记为属性。
•vtkMergeFields -合并多个字段为一个。
•vtkSplitField -将一个字段拆分为多个单一组件字段。
•vtkDataObjectReader -读取VTK格式的字段数据文件。
•vtkdataobjectwwriter—写入VTK格式的字段数据文件。
•vtkprogramabledataobjectsource -定义一个方法来读取任意形式的数据,并将其表示为字段数据(即,将其放在vtkDataObject中)。
本书为英文翻译而来,供学习vtk.js的人参考。

















 1903
1903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









