







文章目录
Zookeeper数据同步
zk通过三种不同的 集群角色来组成整个高性能集群,在zk中,客户端会随机连接到zk集群中的一个节点,如果是读请求,就直接从当前节点中读取数据,如果是写请求,那么请求会被转发给leader提交事务,然后leader会广播事务,只要超过半数节点写入成功,那么写请求就会被提交(类2PC事务,2PC是全数节点ok)
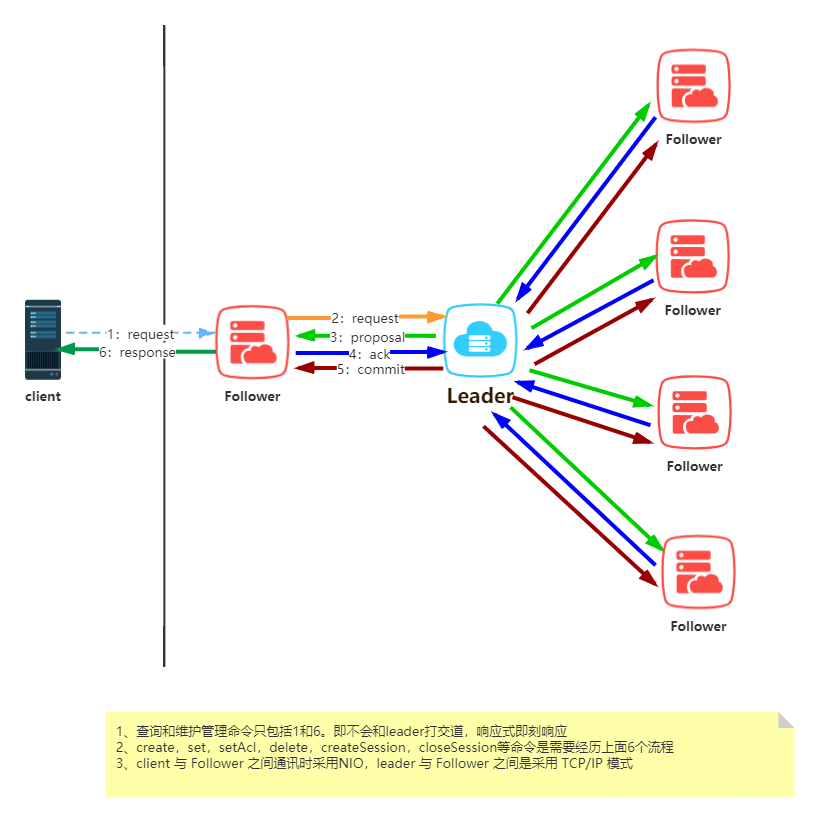
- 问题:
- 集群的leader节点如何选举出来?
- leader节点崩溃以后,整个集群无法处理写请求,如何快速从其他节点里面选出出新的leader呢?
- 原leader节点临时网络故障,恢复后脑裂怎么解决?
- leader节点和各个follower节点的数据一致性如何保证?
一、ZAB协议
Zookeeper Atomic Broadcast,协议是为分布式协调服务 Zookeeper 专门设计的一种支持崩溃恢复的原子广播协议。在 Zookeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,Zookeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
1、介绍
包含两种基本模式,分别是 崩溃恢复、原子广播
当整个集群在启动时,或者当leader 节点出现网络中断、崩溃等情况时,ZAB协议就会进入恢复模式并选举产生新的leader,当leader服务器选举出来后,并且集群中有过半机器和该leader节点完成数据同步后(同步指得是数据同步,用来保证集群中过半的机器能够和leader服务器的数据状态保持一致)。ZAB协议就会退出恢复模式。
当集群中已经有过半的Follower 节点完成了和Leader 状态同步以后,那么整个集群就会进入消息广播模式。整个时候,在Leader 节点正常工作时,启动一台新的服务器加入到集群,那么这个服务器就会直接进入数据恢复模式,和L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









