




 本文探讨了GAN在超分辨率图像处理中的创新应用,尤其是针对人脸图像。研究者首次尝试了从高分辨率到低分辨率的图像转换,并利用不匹配的高、低分辨率图像训练GAN。提出了新的损失函数,有效提升了图像的去噪能力和细节还原,实验结果显示其性能远超传统方法。
本文探讨了GAN在超分辨率图像处理中的创新应用,尤其是针对人脸图像。研究者首次尝试了从高分辨率到低分辨率的图像转换,并利用不匹配的高、低分辨率图像训练GAN。提出了新的损失函数,有效提升了图像的去噪能力和细节还原,实验结果显示其性能远超传统方法。
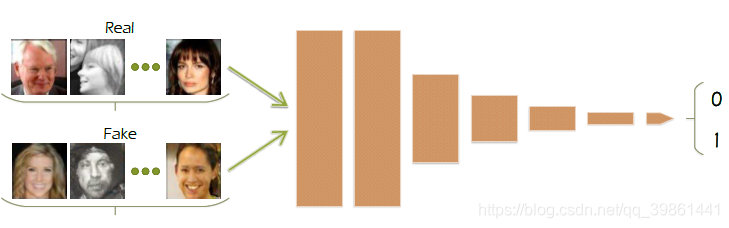
To learn image super-resolution, use a GAN to learn how to do image degradation first
(超分辨率人脸)
作者提出的问题是现在获得的样本图片都是通过简单的线性降采样,或者模糊得到的图片,这和现实的模糊图片是不符合的。因为现实世界中的低分辨率图片通常要考虑这些因素(模糊(例如运动或散焦),压缩伪影,颜色和传感器噪声)有时很难有效地建模(例如多次降级的情况)。如果真实的形象退化模型不同于假设和建模的模型,不可避免地,这会导致测试期间性能不佳。为了缓解这种情况,本文采用深度学习,而不是试图模拟图像降级过程它使用从高到低的生成对抗网络(GAN)。


上面是作者在该文中的创新点
1.首次尝试从高分辨率到低分辨率图转变
2.训练出了一种由高到低的GAN,使用的训练集是不匹配的高分辨率图和低分辨率图。通过这个网络产生的是对应的高分率和低分辨率图片。这些图将用于训练产生下一个GAN(从低分辨率图产生高分辨率图)
3.提出了一种新的损失函数,以GAN为中心,能帮助由低到高的GAN去噪,帮由高到低的GAN污染模糊原图,产生低分辨率的图像。
4.据说效果远远好于以前的东西
总结以前的工作
1.从前使用CNN无非就是输入一个低分辨率的图像,然后输出一个高分辨率的图像,然后与原图像进行对比作为损失函数。
2.有的论文使用VGG来做L2损失函数,有的论文用GAN的分辨器来做损失函数。
网络结构
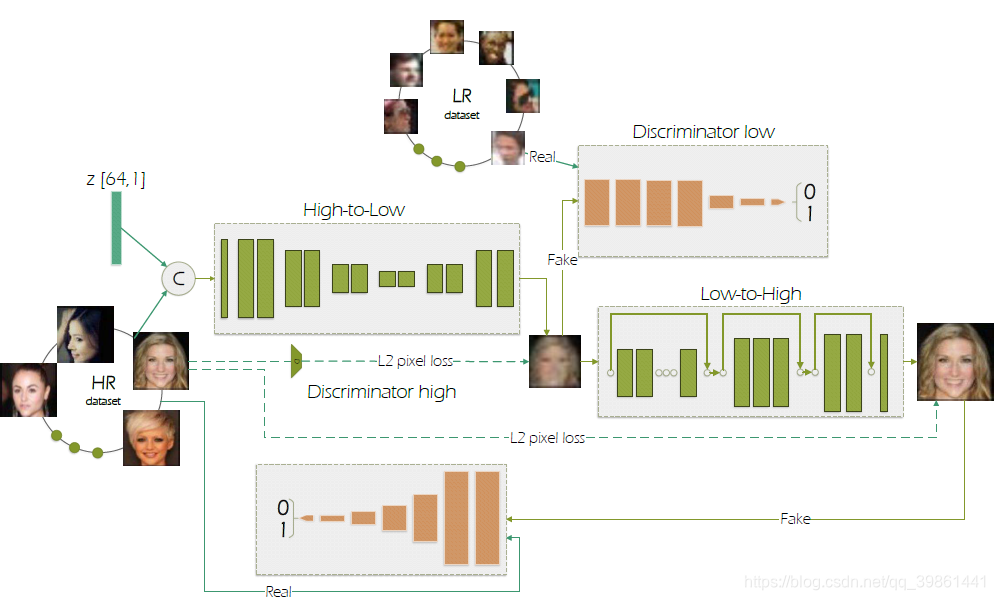
网络结构解释

给一个低分辨率16*16的图片,然后用由低到高的GAN生成一幅64*64像素的高分辨率图片。这个由低到高的网络使用成对的低分辨率和高分率图片进行训练的。

然后对由低到高GAN和训练图片是一个由高到低的GAN生成的高分辨率的图像来自于alignment数据集,低分辨率的图像则来自于widerface数据集。

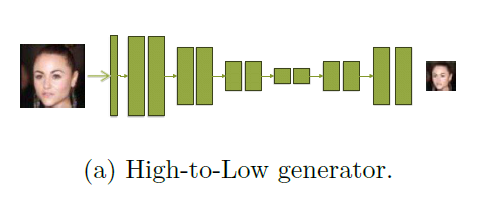
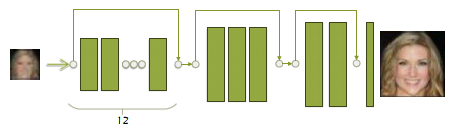
首先介绍由高到低GAN的网络结构,将一张高清图片和噪声连接,然后变化成输入的形状。要加入噪声主要是因为最后生成的低分辨率图应该是有多种可能性的(毕竟产生低分辨率图的原因也是多种多样的)如下面右图所示。网络具有编码和解码的结构,由12个残差模块组成,分成六组。图像输入的分辨率先用池化层下降4倍,这样像素就有64*64变成4*4像素的图片了。后面再增加2倍,变成16*16的图片。网络结构如下面左图所示。

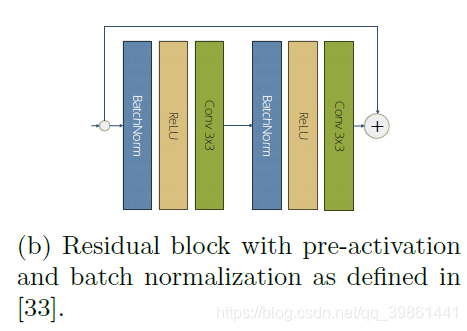
生成器中的残差模块如下图所示

分别器:由高到低的分别器如下下图所示,由六个残差模块(如下图所示)组成(无norm),之后接一个全连接层。
损失函数:生成器和判别器都是用GAN loss 和L2像素损失的结合来搞的。详见后面损失函数定义部分。

由低到高生成器:然后是由低到高GAN了。这个网络由17个残差模块组成,分布在三组中,2,3,12.每一组跳跃连接,在同一组中,第一个模块和最后一个模块连接,见下图。由于前面由高到低加入噪声已经产生了多样性,所以这里这一部分就不在加入噪声了。
由低到高判别器:和前面的由高到低分别器类似,不同的是,前面加了两个最大池化层来减小分辨率。
损失函数:L2损失或让图像变得模糊,因为L2损失小,一些尖锐的地方才能体现出来。然后这里又提出来一种中心GAN损失。L2损失函数用来保证图像的一些特征,GAN中心损失对于由低到高,用来去噪。对于由高到低则用来污染前面的高清图像。
![]()
上式是总的损失函数。

上式是GAN中心损失函数的定义。
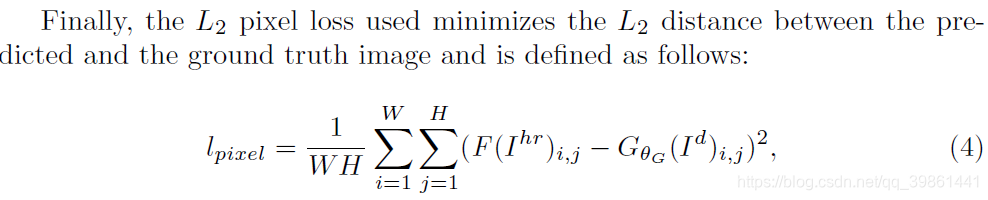

这是L2损失的定义,F是将原像素图变成和生成器输出图片像素一样的图。这样才能进行相同大小矩阵的差运算。对于由高到低网络,这个F函数就是平均池化层,对于由低到高网络,这就是一个简单的identity function(就是直接把匹配的高清图像直接输出)。这个函数的功能也是相当好理解,就是希望减少两幅图像像素上的差距,来保留原图像的特征。
训练方法:

裁剪各种脸部图片用相同的方法。为了增加图片的多样性,对图片进行随机反转,旋转等,由高到低和由低到高网络都训练200epoches(一个epoch大概有2800张图片吧),学习率全程维持在1e-4,用的是ADAM优化器。
最后文中宣布:不成功复原的概率大概10%

















 8358
8358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









