






又是好几天没记自己的学习 轨迹。
中间过年啊大扫除啊陪胡馨允去产检啊瞎搞了好几天。
然后都是一些零零碎碎的学习时间,说出来自己都自己惭愧,只写了一个当当网的爬虫。(不过这个是老师网课里没的,第一个自己独立写的T T
而且输出还不整齐,如果有大神能改正,小弟就在此谢过了QAQ
(因为自身的情况,所以爬的是关键词“张宇考研数学”的书的信息
import requests
from bs4 import BeautifulSoup
import bs4
def get_onepage(url,data):
try:
r = requests.get(url,params = data)
r.raise_for_status
r.encoding = r.apparent_encoding
return r.text
except:
return None
def parse_onepage(html,nlist,plist):
soup = BeautifulSoup(html,'html.parser')
for li in soup.find('ul',{'class':"bigimg"}).children:
if isinstance(li,bs4.element.Tag):
names = li.find_all('a',attrs = {'dd_name' : "单品标题"})
prices = li.find_all('span',attrs = {'class': "search_now_price"})
for k in prices:
plist.append(k.string)
for i in names:
nlist.append(i.attrs['title'])
def print_page(num,nlist,plist):
tplt = "{0:98}\t{1:8}"
print("{0:^98}\t{1:8}".format("书名","价格",chr(12288)))
for j in range(num):
n = nlist[j]
p = plist[j]
print(tplt.format(n,p,chr(12288)))
with open('当当网.txt','a',encoding = 'utf-8') as f:
f.write(tplt.format(n,p,chr(12288)))
f.close()
def main():
for m in range(1,2):
data = {
'key': '张宇考研数学',
'act': 'input',
'page_index': m
}
start_url = 'http://search.dangdang.com/'
html = get_onepage(start_url,data)
listone = []
listtwo = []
parse_onepage(html,listone,listtwo)
print_page(60,listone,listtwo)
if __name__ == '__main__':
main()
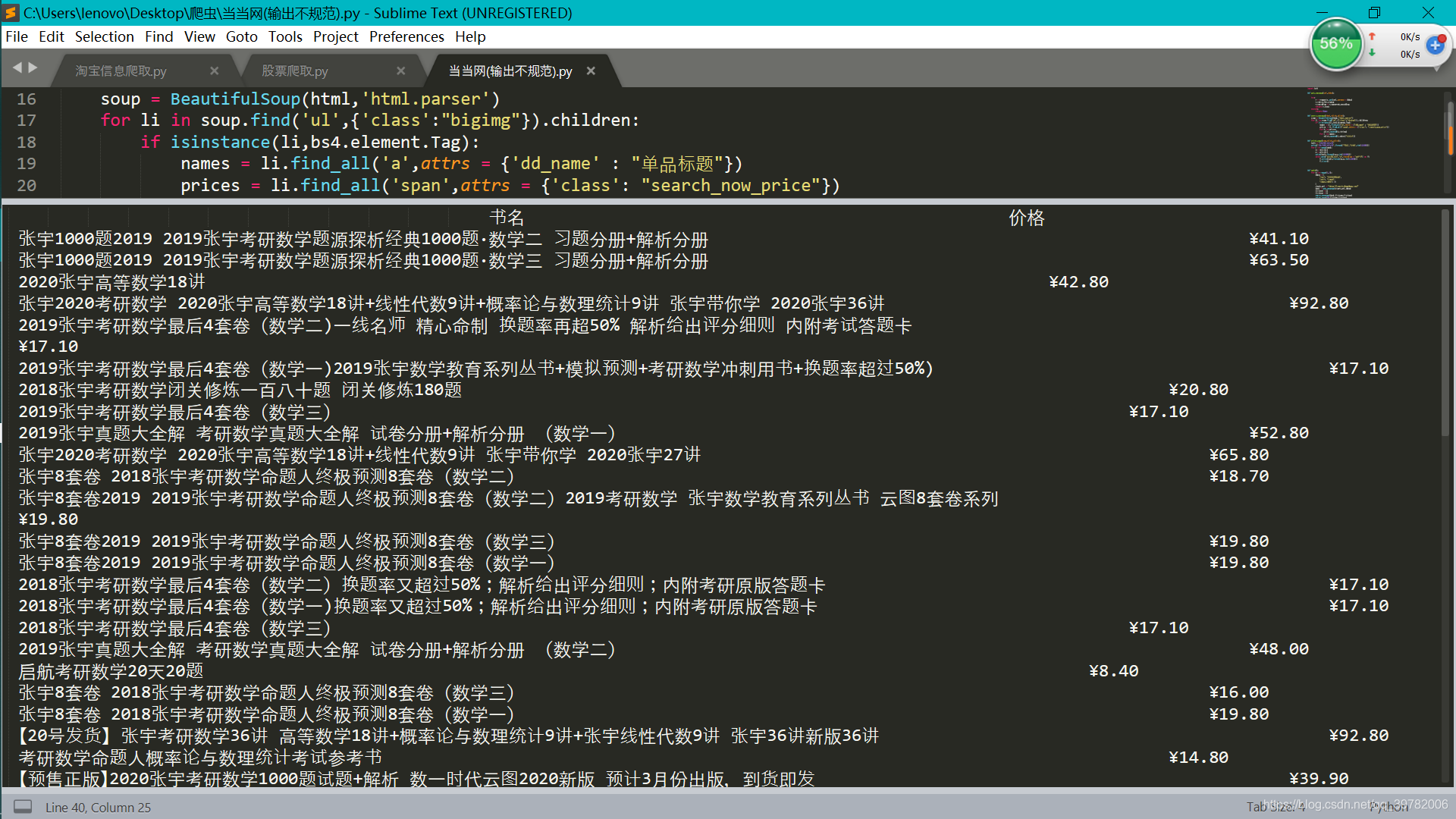
大家看 输出真的很丑。QAQ 但是小弟真的不晓得怎么改


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









