







摘要
视觉-语言预训练(Vision-Language Pre-training, VLP)显著提升了多模态任务的性能。然而,现有预训练模型大多仅擅长基于理解的任务或基于生成的任务,且性能提升主要依赖从网络爬取的大规模噪声图像-文本对数据集,这种监督信号的质量存在局限。本文提出BLIP——一种可灵活迁移至视觉-语言理解与生成任务的新型VLP框架。该框架通过自举标注策略高效利用噪声网络数据:首先由标注生成器合成描述文本,再通过过滤器去除低质量样本。我们在广泛的多模态任务上实现了最先进的性能,包括图像-文本检索(平均召回率@1提升2.7%)、图像描述生成(CIDEr指标提升2.8%)和视觉问答(VQA分数提升1.6%)。BLIP在以零样本方式直接迁移至视频-语言任务时亦展现出强大的泛化能力。相关代码、模型及数据集均已开源。
1. 引言
视觉-语言预训练技术近年来在多模态下游任务中取得了显著成功,但现有方法存在两大局限性:
(1)模型架构层面:现有方法要么采用基于编码器的模型(如Radford等人2021年提出的CLIP、Li等人2021a年提出的ALBEF),要么采用编码器-解码器架构(如Cho等人2021年、Wang等人2021年的工作)。然而,基于编码器的模型难以直接迁移至文本生成任务(如图像描述生成),而编码器-解码器模型尚未在图像-文本检索任务中取得理想效果。
(2)数据层面:当前最先进的方法(如CLIP、ALBEF、SimVLM等)均使用从网络爬取的图像-文本对进行预训练。尽管扩大数据集规模带来了性能提升,但本文证明这些含噪声的网络文本并非视觉-语言学习的最佳选择。
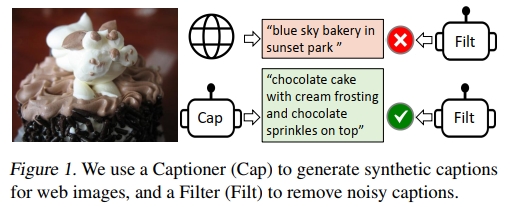
为此,我们提出BLIP(自举式语言-图像预训练框架),用于统一的视觉-语言理解与生成任务。相较于现有方法,BLIP这一新型VLP框架能够支持更广泛的下游任务。该框架从模型架构和数据层面分别做出了以下创新:
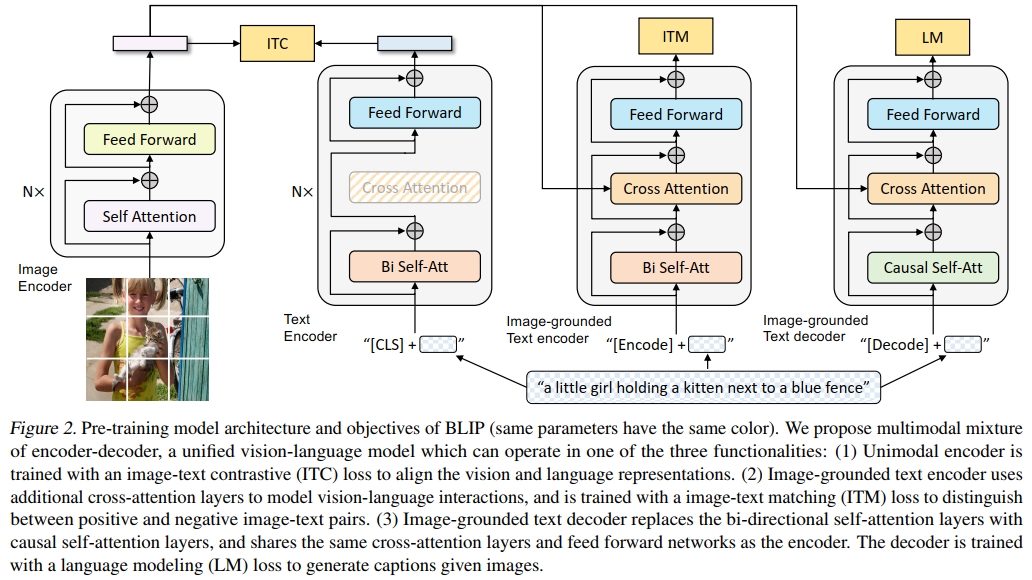
(a) 多模态混合编解码器(MED):一种支持高效多任务预训练与灵活迁移学习的新架构。MED可切换为三种工作模式:单模态编码器、基于图像的文本编码器或基于图像的文本解码器。该模型通过三个视觉-语言目标进行联合预训练:图像-文本对比学习、图像-文本匹配以及基于图像条件的语言建模。
(b) 描述生成与过滤(CapFilt):一种从噪声图像-文本对中学习的新型数据集自举方法。我们将预训练的MED微调为两个功能模块:描述生成器(为网络图像生成合成描述)和噪声过滤器(从原始网络文本和合成文本中清除低质量描述)。
通过大量实验与分析,我们获得以下重要发现:
• 研究表明,描述生成器与过滤器通过自举标注协同工作,能在各类下游任务上实现显著性能提升。同时发现描述文本多样性越高,性能增益越大。
• BLIP在图像-文本检索、图像描述生成、视觉问答、视觉推理及视觉对话等广泛任务中达到最先进水平。当直接迁移至文本-视频检索和视频问答两个视频-语言任务时,我们的模型同样实现了零样本状态下的最优性能。
2. 相关工作
2.1 视觉-语言预训练
视觉-语言预训练(VLP)旨在通过大规模图像-文本对的预训练提升下游视觉与语言任务性能。由于人工标注文本获取成本高昂,现有方法(Chen等,2020;Li等,2020,2021a;Wang等,2021;Radford等,2021)普遍采用网络爬取的图像-替代文本对(Sharma等,2018;Changpinyo等,2021;Jia等,2021)。尽管使用了基于规则的简单过滤器,网络文本仍存在普遍噪声。然而在数据集规模扩大带来的性能提升掩盖下,这些噪声的负面影响长期被忽视。本文首次证明噪声网络文本并非视觉-语言学习的最佳选择,并提出更高效利用网络数据的CapFilt方法。
在统一多任务框架方面,已有诸多尝试(Zhou等,2020;Cho等,2021;Wang等,2021)。核心挑战在于设计能同时胜任理解型任务(如图像-文本检索)和生成型任务(如图像描述)的模型架构。现有基于编码器的模型(Li等,2021a,b;Radford等,2021)和编码器-解码器模型(Cho等,2021;Wang等,2021)均无法兼顾两类任务,而单一的统一编码器-解码器架构(Zhou等,2020)也会限制模型能力。我们提出的多模态混合编解码器(MED)在保持预训练简洁高效的同时,为下游任务提供了更灵活的架构和更优的性能。
2.2 知识蒸馏
知识蒸馏(KD)(Hinton等,2015)通过从教师模型提取知识来提升学生模型性能。自蒸馏作为KD的特例,其教师模型与学生模型规模相同,已在图像分类(Xie等,2020)和近期VLP研究(Li等,2021a)中验证有效性。与现有KD方法仅强制学生模型复现教师模型的类别预测不同,本文提出的CapFilt在VLP语境下实现了更有效的知识蒸馏:描述生成器通过生成语义丰富的合成描述来蒸馏知识,而噪声过滤器则通过清除低质量文本来实现知识提炼。
2.3 数据增强
虽然数据增强(DA)技术已在计算机视觉领域广泛应用(Shorten & Khoshgoftaar,2019),但在语言任务中的应用则更具挑战。近期,生成式语言模型已被用于合成各类NLP任务的训练样本(Kumar等,2020;Anaby-Tavor等,2020;Puri等,2020;Yang等,2020)。与这些专注于低资源纯语言任务的方法不同,我们的研究揭示了合成描述在大规模视觉-语言预训练中的独特优势。
3. 方法
我们提出BLIP框架,这是一个从噪声图像-文本对中学习的统一VLP框架。本节首先介绍新型模型架构MED及其预训练目标,随后阐述用于数据集自举的CapFilt方法。
3.1 模型架构
我们采用视觉Transformer(Dosovitskiy等,2021)作为图像编码器,该架构将输入图像分割为图块并编码为嵌入序列,同时添加[CLS]token表征全局图像特征。相比使用预训练目标检测器提取视觉特征的方法(Chen等,2020),ViT架构计算效率更高,已被近期研究广泛采用(Li等,2021a;Kim等,2021)。
为预训练兼具理解与生成能力的统一模型,我们提出多模态混合编解码器(MED)。该多任务模型可切换三种工作模式:
(1)单模态编码器:分别编码图像和文本。文本编码器采用BERT架构(Devlin等,2019),通过在文本开头添加[CLS]token来生成句子表征。
(2)基于图像的文本编码器:在文本编码器的每个Transformer模块中,于自注意力层(SA)与前馈网络(FFN)之间插入交叉注意力层(CA)注入视觉信息。通过添加任务特定的[Encode]token,其输出嵌入作为图文对的多模态表征。
(3)基于图像的文本解码器:将基于图像文本编码器中的双向自注意力层替换为因果自注意力层。使用[Decode]token标记序列起始,序列结束token标记终止。
3.2 预训练目标
我们联合优化三个预训练目标,包含两个理解型目标和一个生成型目标。每个图文对只需一次计算量较大的视觉Transformer前向传播,以及三次文本Transformer前向传播(分别激活不同功能模块计算下述损失):
-
图文对比损失(ITC)
激活单模态编码器,通过拉近正样本图文对的表征距离、推远负样本对,实现视觉与文本特征空间的对齐。该目标已被证明能有效提升视觉语言理解能力(Radford等,2021;Li等,2021a)。我们采用Li等(2021a)提出的改进方案:引入动量编码器生成特征,并基于动量编码器创建软标签作为训练目标,以处理负样本中潜在的正面样本。 -
图文匹配损失(ITM)
激活基于图像的文本编码器,学习捕捉视觉与语言细粒度对齐的多模态表征。ITM作为二分类任务,模型通过线性分类头(ITM head)预测图文对是否匹配。为提升负样本信息量,我们采用Li等(2021a)的难负样本挖掘策略:优先选择批次中对比相似度较高的负样本参与损失计算。 -
语言建模损失(LM)
激活基于图像的文本解码器,实现给定图像的文本描述生成。通过自回归方式优化交叉熵损失,最大化文本序列似然概率。计算损失时采用0.1的标签平滑系数。相比VLP中广泛使用的MLM损失,LM使模型具备将视觉信息转化为连贯描述的泛化能力。
为实现高效的多任务预训练,文本编码器与解码器共享除SA层外的所有参数。这是因为编码任务(双向自注意力构建当前token表征)与解码任务&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











