







摘要
我们重新评估了在最先进的预训练语言模型中共享输入和输出嵌入权重的标准做法。我们发现,解耦嵌入能够提供更大的建模灵活性,使我们能够显著提高多语言模型中输入嵌入的参数分配效率。通过将输入嵌入的参数重新分配到 Transformer 层中,我们在微调阶段保持相同的参数数量的情况下,在标准自然语言理解任务上取得了显著更好的性能。此外,我们还发现,增加输出嵌入的容量即使在微调阶段被丢弃,仍能为模型带来持久的益处。我们的分析表明,较大的输出嵌入可以防止模型的最后几层对预训练任务过度专门化,并鼓励 Transformer 表示更具通用性和可迁移性,从而适用于其他任务和语言。利用这些发现,我们能够在不增加微调阶段参数数量的情况下,训练出在 XTREME 基准测试上表现优异的模型。
1 引言
近年来,自然语言处理(NLP)模型的性能取得了显著提升,这主要得益于从大规模无标注数据进行迁移学习的进展(Howard & Ruder, 2018; Devlin et al., 2019)。最成功的范式是在大规模 Transformer(Vaswani et al., 2017)模型上进行自监督损失的预训练,然后在下游任务的数据上进行微调(Ruder et al., 2019)。尽管这种方法在实践中取得了成功,但仍然存在诸多低效之处,例如训练时间较长(Liu et al., 2019b)、预训练目标的选择(Clark et al., 2020b)以及训练数据的使用(Conneau et al., 2020a)等问题。在本文中,我们重新审视了一项可能对实践产生广泛影响的建模假设:在最先进的预训练语言模型中,输入和输出嵌入的耦合。
最先进的预训练语言模型(Devlin et al., 2019; Liu et al., 2019b)及其多语言版本(Devlin et al., 2019; Conneau et al., 2020a)继承了从传统语言模型(Press & Wolf, 2017; Inan et al., 2017)沿袭下来的嵌入耦合做法。然而,与传统语言模型不同,在 Devlin et al.(2019)等编码器专用的预训练模型中,嵌入耦合仅在预训练期间有用,因为在微调后,输出嵌入通常会被丢弃。此外,考虑到研究人员愿意在预训练期间投入额外的计算资源以换取下游任务的更好表现(Raffel et al., 2020; Brown et al., 2020),以及预训练模型在推理阶段通常会被调用数百万次(Wolf et al., 2019),仅限于预训练阶段的参数节省在整体上并不那么重要。
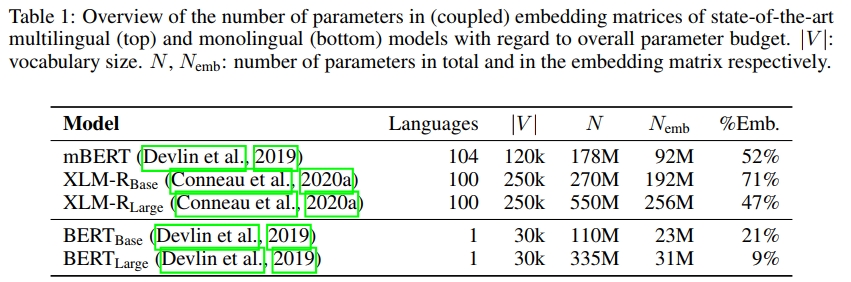
另一方面,绑定输入和输出嵌入会限制模型必须使用相同的嵌入维度。这一限制减少了研究人员在模型参数化方面的灵活性,并可能导致输入嵌入的容量过大,从而造成浪费。这个问题在多语言模型中特别严重,因为它们需要较大的词汇量,并使用高维嵌入,而这些嵌入占据了整个参数预算的 47%–71%(见表 1),表明参数分配存在低效性。
在本文中,我们系统地研究了嵌入耦合对最先进预训练语言模型的影响,重点关注多语言模型。首先,我们观察到,虽然简单地解耦输入和输出嵌入参数不会始终提高下游评估指标,但解耦它们的形状却带来了诸多好处。具体而言,它使我们能够独立调整输入和输出嵌入的维度。我们证明,减少输入嵌入的维度不会影响下游任务的性能。同时,由于输出嵌入在预训练后会被丢弃,我们可以增加其维度,从而提高微调精度,并优于其他容量扩展策略。通过将节省下来的参数重新分配到 Transformer 层的宽度和深度,我们在 XTREME 基准(Hu et al., 2020)的多语言任务上显著超越了强基线 mBERT(Devlin et al., 2019)。最后,我们将这些技术结合到一个名为 Rebalanced mBERT(RemBERT)的模型中,该模型超越了最先进的跨语言模型 XLM-R(Conneau et al., 2020a),同时其预训练语料量减少了 3.5 倍,并覆盖了额外的 10 种语言。
我们深入研究了嵌入解耦带来收益的原因。我们观察到,增加输出嵌入的尺寸可以提高模型在预训练任务上的表现,而这与下游任务的性能高度相关。此外,我们发现这也使 Transformer 更易于在不同任务和语言之间迁移——特别是对于最高层的表示。总体而言,较大的输出嵌入可以防止模型的最后几层对预训练任务过度专门化(Zhang et al., 2020; Tamkin et al., 2020),从而使 Transformer 变得更加通用。
2 相关工作
嵌入耦合 在神经语言模型中共享输入和输出嵌入最早是为改善困惑度(perplexity)而提出的,其理论基础是嵌入的相似性(Press & Wolf, 2017),并证明了在特定情况下,输出概率空间可以被嵌入矩阵约束到一个子空间(Inan et al., 2017)。嵌入耦合在神经机器翻译模型中也很常见,因为它可以降低模型复杂度(Firat et al., 2016)并节省内存(Johnson et al., 2017)。这种方法不仅被应用于最新的语言模型(Melis et al., 2020),还几乎出现在所有我们所知的预训练模型中(Devlin et al., 2019; Liu et al., 2019b)。
表示的可迁移性 计算机视觉和自然语言处理领域的大型预训练模型的表示能力已经被观察到,从第一层到最后一层会逐渐从通用特征转变为特定任务特征(Yosinski et al., 2014; Howard & Ruder, 2018; Liu et al., 2019a)。在 Transformer 模型中,最后几层往往会专门针对 MLM(Masked Language Modeling)任务进行优化,因此变得不易迁移(Zhang et al., 2020; Tamkin et al., 2020)。
多语言模型 近年来的多语言模型通常在覆盖约 100 种语言的数据上进行预训练,并使用跨所有语言共享的子词词汇表(Devlin et al., 2019; Pires et al., 2019; Conneau et al., 2020a)。为了在大多数语言上达到合理的性能,这些模型需要为每种语言分配足够的容量,这被称为“多语言诅咒”(curse of multilinguality)(Conneau et al., 2020a; Pfeiffer et al., 2020)。因此,多语言模型通常具有庞大的词汇表和较大的嵌入尺寸,以确保所有语言的 token 都能被充分表示。
高效模型 关于更高效的预训练模型,大多数研究都集中在剪枝(pruning)或知识蒸馏(distillation)方法上(Hinton et al., 2015)。剪枝方法通常通过移除部分模型结构(如注意力头)来减少计算量(Michel et al., 2019; Voita et al., 2019),而知识蒸馏则是将一个大型预训练模型压缩成一个更小的模型(Sun et al., 2020)。知识蒸馏可以被视为通过大型教师模型来重新分配预训练容量的一种替代方法。然而,蒸馏预训练模型的成本较高(Sanh et al., 2019),并且需要克服架构差异,同时平衡训练数据和损失项(Mukherjee & Awadallah, 2020)。相比之下,我们提出的方法更加简单,并且可以与知识蒸馏互补,以提升紧凑型学生模型的预训练效果(Turc et al., 2019)。
3. 模型效率的衡量
模型的效率可以从多个维度进行衡量,包括浮点运算次数(Schwartz et al., 2019)以及运行时间(Zhou et al., 2020)。我们遵循之前的研究(Sun et al., 2020),主要通过微调时的参数数量来比较模型的效率(有关该设置的更多说明,请参见附录 A.1)。此外,为了完整性,我们一般都会报告预训练(PT)和微调(FT)阶段的参数数量。
基线模型 我们的基线模型采用与多语言 BERT(mBERT;Devlin et al., 2019)相同的架构。该模型由 12 层 Transformer 组成,隐藏层维度 H 为 768,具有 12 个注意力头。输入和输出嵌入是耦合的,并且其维度 E 等于隐藏层维度,即 E o u t = E i n = H E_{out} = E_{in} = H Eout=Ein=H。该模型在预训练和微调阶段的总参数量为 1.77 亿(有关更多细节,请参见附录 A.2)。为了确保公平比较,我们训练了一些在超参数上有所不同的模型变体,但其他训练条件均保持一致。
任务 在实验中,我们采用 XTREME 基准(Hu et al., 2020)中的任务,这些任务需要进行微调,包括 XNLI(Conneau et al., 2018)、NER(Pan et al., 2017)、PAWS-X(Yang et al., 2019)、XQuAD(Artetxe et al., 2020)、MLQA(Lewis et al., 2020)以及 TyDiQA-GoldP(Clark et al., 2020a)等数据集。所有任务的详细信息可在附录 A.4 中找到。除非另有说明,我们的实验结果均基于开发集(dev set),并取三次微调实验的平均值。
4 重新审视嵌入解耦
朴素解耦
在当前最先进的多语言模型中,嵌入层占据了大量的参数预算(见表 1)。我们首先研究嵌入解耦对这些模型的影响。在表 2 中,我们展示了将基线模型的输入和输出嵌入解耦后的效果。
简单地解耦输出嵌入矩阵会使模型的整体表现略有提升,平均提升 0.4 个点。但这一增益在所有任务上并不均匀,因此单纯地解耦嵌入矩阵并保持相同的维度,并不会对模型性能产生重大影响。
然而,更重要的是,解耦输入和输出嵌入使它们的形状可以独立变化,从而提供了更大的建模灵活性。我们将在后续部分进一步探讨这一点。
输入 vs. 输出嵌入
解耦输入和输出嵌入后,我们可以灵活调整两者的维度,并确定哪一部分对于模型的迁移性能更为重要。为此,我们比较了两种模型的性能:
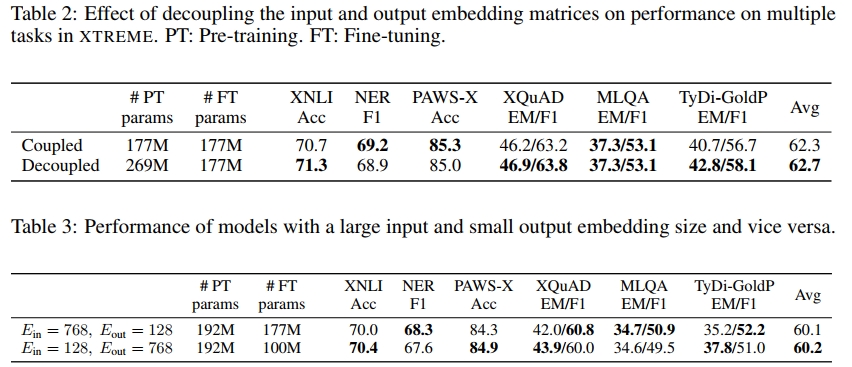
- E i n = 768 , E o u t = 128 E_{in} = 768,E_{out} = 128 Ein=768,Eout=128
- E i n = 128 , E o u t = 768 E_{in} = 128,E_{out} = 768 Ein=128,Eout=768(此模型在微调时的参数减少了 43%)
表 3 显示了实验结果。令人惊讶的是,预训练时具有更大输出嵌入尺寸的模型在平均水平上略微优于对比模型,即使在微调阶段减少了 7700 万个参数。
减少输入嵌入的维度可以显著减少参数量,同时对准确率的影响比减少输出嵌入的影响要小得多。因此,目前多语言模型的参数分配(见表 1)似乎存在较大低效性。对于一个输入和输出嵌入耦合的多语言模型而言,按照 Lan et al.(2020)的建议减少输入嵌入的维度来节省参数,会对性能造成严重的负面影响(见附录 A.5 了解详细信息)。
本节的结果表明,输出嵌入在预训练表示的可迁移性方面起着重要作用。特别是对于多语言模型来说,减小输入嵌入的维度可以在几乎不影响性能的情况下释放出大量参数。在接下来的部分,我们将研究如何通过调整嵌入尺寸和 Transformer 层的结构来进一步提高模型性能。
5 通过调整嵌入和层大小提高微调效率
增大输出嵌入维度
在第 4 节中,我们观察到减少 E o u t E_{out } Eout会影响模型在微调任务上的表现,这表明 Eout 对于模型的迁移能力至关重要。因此,我们研究了相反的情况,即是否可以通过增加 E o u t E_{out } Eout的大小来提升模型性能。
为此,我们进行实验,将输入嵌入大小 E i n E_{in} Ein 设为 128,保持模型的其他部分不变,并在不同的实验中将输出嵌入 E o u t E_{out } Eout设为 {128、768 和 3072}。
实验结果见表 4。在所有任务中,随着 E o u t E_{out } E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











