







摘要
尽管大规模预训练的Transformer模型在处理自然语言任务方面已证明非常有效,但处理长序列输入仍然是一个重大挑战。其中一个任务是长输入摘要生成,在该任务中,输入文本的长度超过了大多数预训练模型的最大输入上下文。通过一系列广泛的实验,我们研究了哪些模型架构的变化和预训练范式可以最有效地将预训练的Transformer模型适配到长输入摘要生成任务。我们发现,采用带有全局编码器标记的分块局部Transformer,在性能和效率之间达到了良好的平衡,并且在长序列上的额外预训练显著提高了下游摘要生成的性能。基于这些发现,我们提出了PEGASUS-X,这是PEGASUS模型的扩展,加入了额外的长输入预训练,以处理最多16K tokens的输入。PEGASUS-X在长输入摘要任务上取得了与更大模型相媲美的优异表现,同时只增加了少量参数,并且不需要模型并行来进行训练。
1. 引言
大规模预训练的Transformer模型在处理自然语言任务方面已被证明极为有效(Devlin et al., 2018;Brown et al., 2020)。然而,处理长文本序列仍然是这些模型面临的重大挑战。训练能够处理长序列的模型在计算和内存上都非常昂贵,而且还需要在长序列数据上进行训练和评估,而长序列数据可能更为稀缺且收集成本较高。鉴于Transformer模型在短序列语言任务上的广泛成功,我们的目标是研究如何扩展这些模型以处理更长的序列。
在这项工作中,我们专注于长输入摘要任务:将长输入文档总结成较短的文本序列。这类任务的输入文档通常比大多数标准Transformer模型的最大上下文长度要长,因此需要进行专门的模型架构修改以及新的训练机制。为了避免Transformer中注意力计算的内存消耗呈二次增长,许多内存高效的Transformer变体已被提出(Tay等,2020,2021)。然而,这些变化如何被纳入模型中一直不一致且随意,并且几乎没有确立的最佳实践。例如,有些研究增加了额外的长输入预训练阶段,以将模型权重适配到新架构(Beltagy等,2020),而另一些则直接在长输入摘要数据上进行微调而不做任何预适应(Zaheer等,2020;Pang等,2022)。由于训练这些模型的高成本,尚未系统地研究如何最好地适配模型来处理长输入序列。因此,很难确定哪些模型和训练变化是必要的或互补的。
为了解决这些问题,我们进行了一系列广泛的实验证明,研究了架构变化、模型配置和预训练方案,以识别出训练Transformer模型来应对长输入摘要任务的最佳方法。我们评估了一组高效的Transformer变体,并提出了一种更简单的块状局部Transformer架构,具有错列块和全局标记,能够在性能和内存效率之间达到良好的平衡。我们还表明,在固定令牌预算下,先在短序列上预训练,再将模型适配到长序列的高效Transformer架构并进行额外训练,显著提高了性能,相比之下,只有长输入预训练或没有适应的模型表现较差。我们还研究了其他模型设计选择,如位置编码方案、编码器-解码器层分布以及预训练和微调架构超参数不一致的影响。
基于我们的实证研究结果,我们将预训练的PEGASUSLarge模型(Zhang等,2020)适配到处理最长16K输入令牌的长输入摘要任务。所得的模型,我们称之为PEGASUS-X,在长输入摘要任务上取得了优异的成绩,在某些情况下超过了更大模型LongT5(Guo等,2021),并在两个任务——GovReport和PubMed上创下了新的最佳成绩。此外,短输入摘要的性能几乎没有受到影响。一个较小的版本,我们称之为PEGASUS-XBase,使用更少的参数实现了类似的成绩。两个模型的代码和权重将在https://github.com/google-research/pegasus以及Hugging Face Transformers(Wolf等,2020)中发布。除了长输入摘要之外,我们相信我们的许多发现将有助于社区有效地将Transformer模型适应于处理其他任务中越来越长的输入序列。
总结:
我们的贡献包括:
- 我们评估了一系列高效的Transformer架构以及其他模型改进,报告了它们在长输入摘要任务上的效果和计算资源的权衡。
- 基于我们的研究结果,我们提出了一种方法,将短上下文的预训练Transformer编码器-解码器适配为处理长输入,并将其应用于PEGASUS,显著提升了其长文档摘要性能,同时保持了短输入的性能。
- 我们发布了结果模型的检查点:一个包含568M参数的模型(PEGASUS-X)和一个较小的272M参数模型(PEGASUS-XBase),两者在大多数任务上表现出色。
2 长输入摘要的挑战
2.1 计算挑战
摘要任务本质上是将信息从长序列压缩到短序列,而大多数常见的摘要任务输入通常比Transformer语言模型的输入序列长度要短,通常为512到2048个令牌。随着模型处理语言能力的提高,领域推动了更具挑战性的摘要任务,要求更长的输入序列。Transformer中注意力机制的内存和计算需求按二次方增长,这对处理这些长摘要任务构成了挑战。为了解决这一限制,许多高效的Transformer变体(Beltagy等,2020;Zaheer等,2020;Choromanski等,2021;Wang等,2020;Kitaev等,2020)被提出。然而,即便采用了高效的Transformer架构,实现大约线性增长的内存消耗,模型通常还是会在短序列输入上进行预训练,然后在微调时适配长输入,这可能并非最优。
尽管最近有些研究开始关注仅使用解码器的自回归语言模型用于摘要(Radford等,2019;Brown等,2020;Chowdhery等,2022),但编码器-解码器模型仍然表现更好,并且仍然是该任务的首选架构(Wang等,2022b)。输入长度和摘要长度之间的不对称性需要对模型的资源限制进行新的考虑。考虑一个12层编码器和12层解码器的摘要模型,预训练时输入长度为512,在任务中微调时输入长度为16384,输出长度都为512。由于预训练通常使用较短的序列,而微调时使用较长的输入序列,因此微调可能比预训练更为资源密集且更慢,这与传统范式相悖。由于编码器输入增长了32倍,注意力机制中自注意力的内存消耗按二次方增长,因此我们预计微调时编码器自注意力的内存消耗会是预训练时的1024倍。即使我们使用能够实现线性内存消耗和计算的高效Transformer变体,编码器的自注意力和解码器的交叉注意力操作仍然会比预训练时消耗32倍的内存。除了注意力机制外,像FFN这类随输入长度线性增长的操作,也大大增加了训练和推理所需的计算量。
另一方面,长文档摘要的独特特点也可能促使我们对这些问题提出新的解决方案。例如,如果长序列的编码计算成为计算瓶颈,我们可以考虑使用较少的编码器层和更多的解码器层,在推理时牺牲解码速度来加快训练。微调时更高的相对成本也为适应预训练模型以加快微调速度提供了更多动力,例如通过混合短长输入训练课程、通过额外的预训练适应高效Transformer架构等。
为了应对这些问题和挑战,我们进行了一系列消融实验,研究哪些方法能够改善下游摘要结果,并探讨其中的计算资源权衡。
2.2 任务/数据集挑战
构建长文档摘要模型的一大挑战是缺乏足够的数据来训练和评估这些模型。最近推出的新长文档摘要数据集在一定程度上缓解了这个问题(Chen等,2022;Shaham等,2022;Kryściński等,2021),尽管好的数据集仍然稀缺,导致这一问题依然具有挑战性。目前数据集中的主要问题是:摘要任务的相对简单性,输入缺乏多样性,数据收集过程可能导致数据泄露,训练样本数量不足等。更多讨论可以参考Wang等(2022a)。
3 实验设置
与Zhang等(2020)类似,我们大多数实验使用了PEGASUSBase大小的模型,随后将我们的研究结果应用于PEGASUSLarge大小的模型。
3.1 预训练
我们通常遵循PEGASUS(Zhang等,2020)中的预训练步骤来预训练PEGASUSBase模型。我们在消融研究中的所有实验都使用C4(Raffel等,2020)进行500k步的预训练,输入令牌为512,输出令牌为256,掩蔽比例为45%,除非另有说明。对于长输入预训练,我们将输入长度扩展到4096个令牌,并将掩蔽比例从45%调整为5.625%,降低比例的因子为8,以适应输入序列长度的8倍增加。我们还仅过滤掉长度超过10000字符的文档。
3.2 微调
我们通过在arXiv(Cohan等,2018)和GovReport(Huang等,2021)长上下文摘要任务上微调来评估我们的预训练模型。在相关情况下,我们还在较短上下文的XSUM和CNN/DailyMail任务上进行微调。在每个实验中,我们报告基于ROUGE-1、ROUGE-2和ROUGE-L分数的几何平均数(RG)作为最佳验证集分数(Lin,2004),基于rouge-score包进行计算。对于arXiv任务,我们使用最大16384个令牌的输入长度和256个输出令牌进行微调,而对于GovReport任务,我们使用10240个输入令牌和1024个输出令牌,因为该任务的摘要较长。对于XSUM和CNN/DailyMail任务,我们使用512个输入令牌,输出长度分别为64和128,遵循PEGASUS的超参数设置。微调的完整超参数集可以在附录7中找到。除非另有说明,我们在预训练(在较短上下文上)和微调(在较长上下文上)之间直接切换到高效的Transformer架构,中间没有适应阶段。
4 实验
4.1 Encoder架构
我们首先研究用高效的Transformer编码器替换标准编码器的有效性,以使我们的模型能够处理更长的输入序列,同时保持合理的设备内存消耗。我们首先考虑两种高效的Encoder架构,它们代表了两种不同的内存高效注意力计算方法。
Big Bird(Zaheer等,2020)采用稀疏注意力计算的方法,结合滑动窗口注意力(sliding-window attention)、随机注意力(random attention)以及一组全局注意力Token(global-attention tokens)。相反,Performer(Choromanski等,2021)采用了通过正交随机特征(orthogonal random features)分解注意力矩阵的方法。这两种架构的优点在于不需要引入新的参数,因此可以直接将预训练的Transformer权重迁移到这些架构中。此外,这两种模型在Long Range Arena任务上表现良好(Tay等,2021)。然而,在本实验中,我们在相同的Encoder架构上进行预训练和微调,以避免预训练和微调架构不匹配的问题。
此外,我们还引入了两种简单的局部注意力(local attention)Transformer编码器变体。首先,我们使用了一种简单的块局部Transformer(Local),其中Encoder输入Token被划分为不重叠的块(blocks),Token只能关注(attend to)同一块中的其他Token。其次,我们在此基础上扩展,添加一组可学习嵌入的全局Token(Global-Local),这些全局Token可以被所有Encoder Token关注,并能关注所有Encoder Token。这些组件在原理上类似于Big Bird的滑动窗口注意力和全局Token注意力,以及其他高效Transformer(如ETC(Ainslie等,2020)和Longformer(Beltagy等,2020))中的类似结构。然而,我们选择了更简单的块局部注意力,而不是滑动窗口注意力,并通过错位(staggering)局部注意力块来弥补缺少重叠块的问题,具体内容将在第4.2节详细讨论。尽管设计较为简单,我们的方法在性能上仍然具有很强的竞争力。
在实验设置上,Big Bird、Local和Global-Local均使用块大小64,其中Global-Local还使用32个全局Token。Performer使用256个随机特征(random features)。
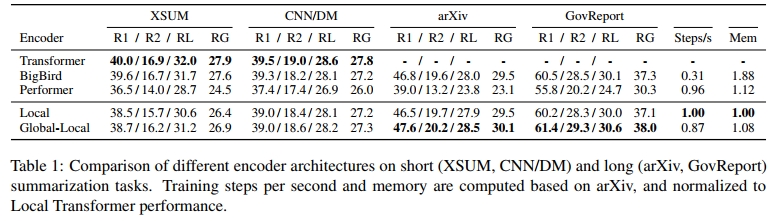
短文本和长文本摘要任务的实验结果见表1。表中最右侧的列显示了在arXiv任务上微调时,每秒训练步数的相对比例以及每台设备的内存消耗情况。在短文本摘要任务中,标准Transformer(全注意力)表现最佳,其次是Big Bird。在长文本摘要任务中,Big Bird和Global-Local模型表现最佳,但Big Bird消耗的内存远高于其他架构,并且训练速度显著较慢。相反,我们发现Performer虽然在内存消耗和训练效率上较优,但其性能相比其他架构明显较差。
另一方面,我们发现Local和Global-Local Encoder在性能和效率之间达到了良好的平衡。使用块局部注意力机制的Local Encoder,其性能接近Big Bird,但速度更快且占用更少的内存。Global-Local Encoder在牺牲少量速度和内存的情况下,换取了更好的性能,甚至超越了Big Bird。虽然Local和Global-Local模型在短文本摘要任务上的表现不如Big Bird和标准Transformer,但在长文本摘要任务中,这些模型架构实现了更优的性能权衡。
要点总结:Local attention 是一个出人意料的强大基线,加入 global tokens 显著提升了性能,同时这两种模型都具有较高的资源效率。
4.2 Local 和 Global-Local 的配置
鉴于 Local 和 Global-Local 编码器变体的良好性能,我们进一步探索对这些模型的架构调整。
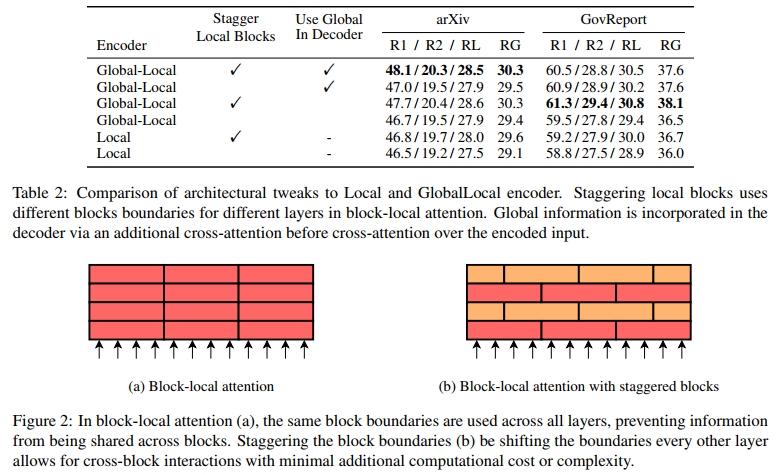
首先,我们引入局部注意力块(local attention blocks)的错位(staggering)机制。在滑动窗口注意力(sliding window attention)中,Token 可以跨窗口交互,而在块局部注意力(block-local attention)中,Token 只能关注同一块(block)中的其他 Token。如果在每一层都将输入 Token 划分为相同的块,这意味着整个编码器过程中,块之间不会进行信息交换。为了解决这个问题,我们引入了一项小的架构调整,即在交替的层(alternating layers)之间错位块划分。我们在图 2 中展示了该方法的示例。具体而言,我们通过在每隔一层时将块边界偏移半个块的方式来错位注意力块。在实际实现中,我们通过在隐藏表示的两侧填充(padding)半个块,并相应地使用掩码(masking)来完成此操作。
其次,在 Global-Local 模型中,解码器(decoder)仅关注编码的 Token 表示,而不关注 global tokens 的表示。因此,我们提出了一种变体,其中我们将 global tokens 的表示提供给解码器,具体而言,在执行对编码 Token 的交叉注意力(cross-attention)之前,我们引入第二个 encoder-decoder 交叉注意力机制,该机制仅关注 global tokens。我们的目标是让解码器在执行对编码序列的交叉注意力之前,先整合 global tokens 提供的全局信息。
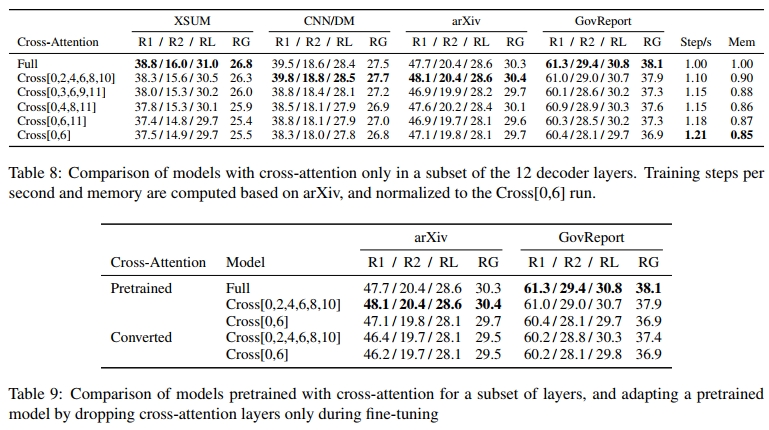
表 2 展示了这两项改进的实验结果。我们发现错位局部块(staggered local blocks)能显著提高 Local 和 Global-Local 模型的性能。值得注意的是,即使在已经具备全局信息交互机制的 Global-Local 模型中,错位块仍然提升了性能,这表明这两种模型改进是互补的。相反,我们发现在解码器中引入 global token 信息并未带来显著的性能提升,特别是在已经使用了错位局部块的情况下。
要点总结:错位局部注意力块(staggering local attention blocks)显著提升性能,并且与 global tokens 互补。
4.3 Global-Local:块大小和全局 Token 数量
接下来,我们对 Global-Local 编码器的块大小(block size)和全局 Token 数量(global tokens)进行调整,实验结果如表 3 所示。
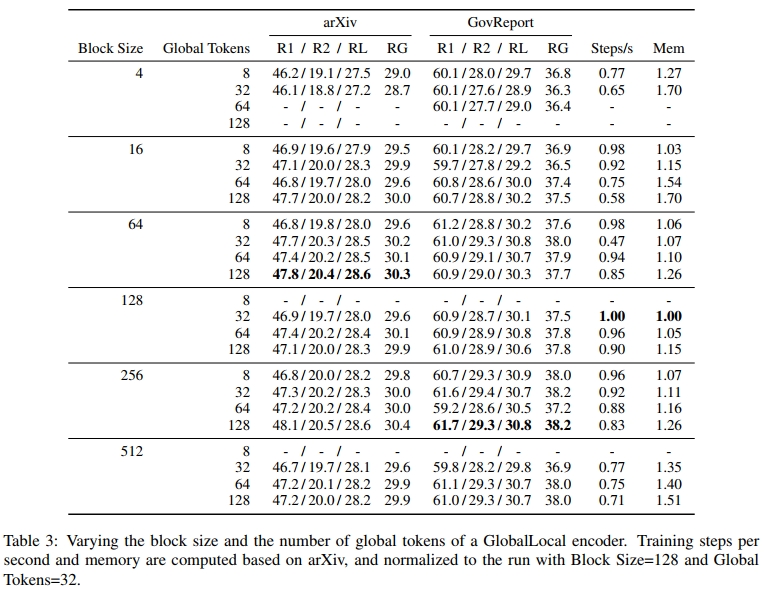
总体而言,我们发现增加块大小(block size)或全局 Token(global tokens)的数量可以提升性能,但同时会增加内存消耗和计算时间。然而,增大块大小的效果并不显著,并且在达到较大的块大小或全局 Token 数量时,性能提升会趋于饱和。因此,在资源允许的情况下,增大这两个超参数是有利的,但与其他潜在的模型改进相比,它可能不是优先级最高的调整项。为了保持一致性,在后续的消融实验中,我们统一采用块大小为 64、全局 Token 数量为 32。
要点总结:较大的块大小或更多的全局 Token 会提升性能,但效果会趋于饱和。
4.4 位置编码方案
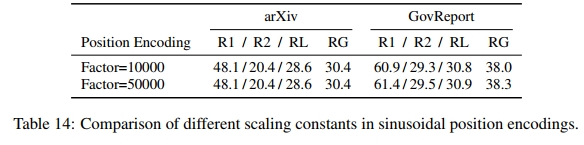
近年来,新的位置编码方案(position encoding schemes)如 RoPE(Su et al., 2021)和 ALiBi(Press et al., 2022)受到了关注,并在下游任务评测中展现出更好的性能。随着输入序列长度的增加,尤其是超过了隐藏表示的维度,以往的位置信息编码方式可能已不再最优。此外,RoPE、T5 以及 ALiBi 等相对位置编码(relative position encodings)可能更适用于在预训练和微调之间对不同输入长度的模型进行适配。因此,这是一个重新评估编码器模型中位置编码方案的良好契机。
由于局部注意力块(local attention blocks)与相对位置编码的实现方式存在较为复杂的交互关系,我们首先使用全注意力(full-attention)Transformer 进行初步研究。我们在预训练时采用 512 的输入长度,在微调长序列任务时使用 2048 的输入长度——此实验同时检验了位置编码是否具备适应更长序列的能力。
除了 PEGASUS 和 Vaswani et al. (2017) 所使用的正弦(sinusoidal)位置编码,我们还考察了 T5 的基于桶(bucket-based)的相对位置编码方案、RoPE、绝对位置嵌入(absolute position embeddings),以及不使用任何位置编码(作为基线)。对于绝对位置嵌入,我们遵循 Beltagy et al. (2020) 的方法,在微调前通过复制已学习的位置信息嵌入(learned position embeddings)来处理更长的序列。所选的位置编码方案应用于模型的所有部分,包括编码器(encoder)和解码器(decoder)。我们没有对 ALiBi 进行实验,因为我们找不到将 ALiBi 适配到交叉注意力(cross-attention)中的自然方式。
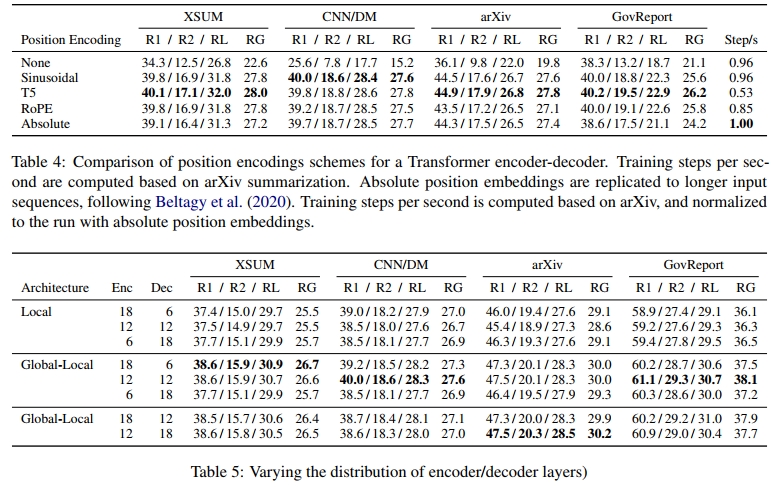
我们的实验结果见表 4。我们发现,尽管 T5 的表现最佳,但它的计算速度几乎是其他位置编码方案的两倍,这一结果与 Press et al. (2022) 的研究一致。正弦(sinusoidal)位置编码和 RoPE 的表现仅略逊于 T5,但计算效率要高得多,因此它们更具吸引力。鉴于正弦位置编码的实现方式更为简单,我们在后续实验中选择继续使用它。
要点总结:正弦位置编码仍然是长输入 Transformer 的一个良好选择。
4.5 扩展编码器与解码器层数
近年来,描述模型规模与性能之间经验关系的扩展规律(scaling laws)(Kaplan et al., 2020;Ghorbani et al., 2021;Zhang et al., 2022)已被广泛关注,并表现出惊人的一致性。本节中,我们进行了一组小规模的扩展实验,探讨编码器和解码器层数的分配对模型性能的影响。
实验结果见表 5。在表格的前半部分,我们将总层数固定为 24,并分别考察了编码器占比更大(encoder-heavy)和解码器占比更大(decoder-heavy)的配置,适用于 Local 和 Global-Local 两种模型。我们观察到,编码器和解码器层数分配对性能的影响相对较小。在 Local 模型中,解码器占比较大的模型略有性能提升。而在 Global-Local 模型中,我们发现编码器和解码器层数均衡分配时,性能优于编码器或解码器占比更大的情况,后两者的表现相当。
此外,我们还探讨了进一步增加编码器或解码器层数至 18 层的情况,结果见表 5 的后半部分。我们发现,相较于 12/12 层的编码器-解码器结构,增加层数并未提升性能,因此我们推测模型的瓶颈可能出现在其他超参数(如隐藏层维度)而非层数本身。
值得注意的是,由于输入和输出序列长度的不对称性,不同的编码器和解码器层数分配方式会导致不同的计算权衡。编码器占比更大的模型由于长输入序列的存在,需要更多的内存,而解码器占比更大的模型由于解码是自回归(autoregressive)过程,在推理时速度会较慢。鉴于性能提升的幅度较小,在实际应用场景中,内存或计算限制可能比性能差异更具决定性。
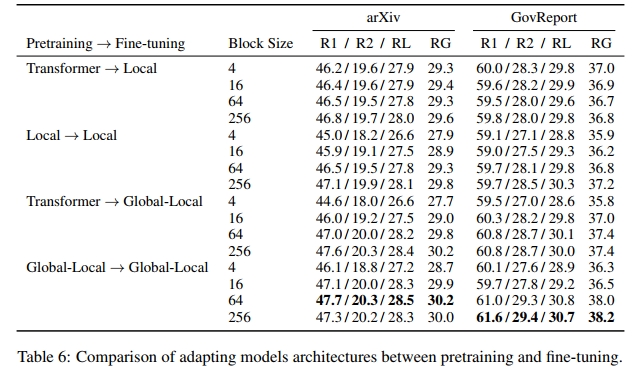
要点总结:平衡的 Global-Local 模型优于其他变体,但性能差异可能会被资源消耗等因素抵消。
4.6 预训练 vs. 微调架构
此前的研究通常采用全注意力(full-attention)Transformer 在较短序列上预训练的模型权重,并在微调时调整为高效 Transformer 编码器架构(Zaheer et al., 2020),或者在微调前增加一个额外的预训练阶段(Beltagy et al., 2020)。本节探讨这种方法是否最优,或者是否应该直接从预训练阶段开始就使用高效编码器。需要注意的是,即使使用高效编码器,我们仍然是在较短序列(512 tokens)上进行预训练。
我们分别采用全注意力 Transformer 和高效架构进行预训练,测试 Local 和 Global-Local 两种模型,并调整 block size。由于 Local Transformer 与标准 Transformer 的主要区别就在于 block size(除了交错块机制外,block size 为 512 的 Local 模型等同于标准 Transformer),因此不同的 block size 反映了模型在不同架构之间的适应程度。当从预训练的 Transformer 编码器转换为 Global-Local 架构时,由于 Global-Local 模型依赖新增的全局 token 嵌入,我们通过从词汇嵌入中随机采样的方式来初始化这些全局 token。
实验结果见表 6。对于 Local 模型,在较小 block size(如 16)下使用 local attention 进行预训练会降低性能,但在适中 block size(如 64)时,两种方法的效果相当。相比之下,Global-Local 模型在使用高效架构进行预训练时表现更好。我们推测,这种差异可能是由于 Global-Local 模型中新增的全局 token 嵌入需要从随机初始化开始学习,因此更需要预训练阶段的优化,使其能够与 local attention 共同训练。
要点总结: 对于中等 block size,直接使用 Local 编码器进行预训练或从全注意力 Transformer 适配都能取得相近的效果,但对 Global-Local 编码器来说,从预训练阶段就采用高效架构会有轻微优势。
4.7 预训练方案
目前,我们仅考虑了在短序列上进行预训练。理论上,在长序列上进行预训练可能会提高模型在长输入摘要任务中的表现。然而,仅使用长序列进行预训练成本较高,并且需要大量长文本数据,而这类数据相对较少。此外,长文档可能包含与短文档不同的信息,仅使用长序列进行训练可能会降低训练数据的多样性。
不同的长上下文 Transformer 采用了不同的预训练方法。例如,Longformer(Beltagy et al., 2020)通过多个阶段逐步增加预训练序列长度,以适应长序列输入;LongT5(Guo et al., 2021)则完全使用长序列进行预训练;而其他方法(Zaheer et al., 2020;Ivgi et al., 2022)则完全没有进行长序列预训练。
本节将探讨短序列和长序列预训练的平衡如何影响模型在下游任务中的表现,并尝试找到预训练成本与下游性能之间的最佳权衡。
我们考虑两种预训练设置:短输入预训练,输入 512 token,输出 256 token;以及长输入预训练,输入 4096 token,输出 256 token。我们在第 3.1 节描述了相应的数据预处理差异。
我们选择固定训练过程中所看到的输入 token 数量作为约束,并在此约束下调整配置。该约束大致反映了计算消耗量,并且对应于预训练过程中所看到的输入 token 总量。这与固定训练步数的方式不同,因为在相同步数下,长输入预训练会消耗更多计算资源。
与之前实验(通常进行 50 万步的短输入预训练)不同,我们将 总输入 token 预算设定为 1310 亿 token,相当于100 万步的 512 token 输入。这一更大的预算确保了当我们仅进行长输入预训练时,模型仍然能经过合理的训练步数。在此预算下,我们考虑四种配置:
- 100% 短输入预训练(100 万步)
- 75% 短输入(98.3B token,75 万步)+ 25% 长输入(32.8B token,3.125 万步)
- 50% 短输入(62.5B token,50 万步)+ 50% 长输入(62.5B token,6.25 万步)
- 100% 长输入预训练(12.5 万步)
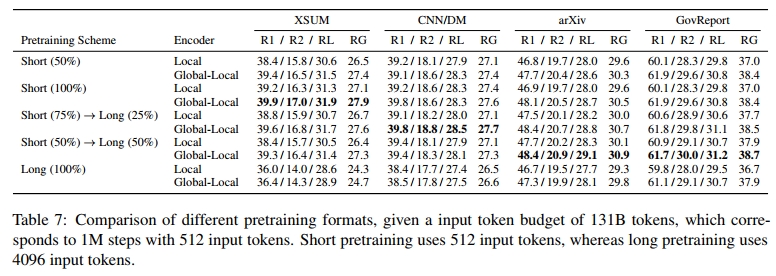
我们在表 7 中比较了不同预训练方案的性能,同时也包含了 50 万步短输入预训练作为对比基准。
首先,比较 50 万步和 100 万步的短输入预训练,我们发现增加预训练步数仍然可以提升性能,这表明 50 万步的基础模型可能仍然训练不足。其次,我们观察到 纯长输入预训练的表现始终较差,我们认为这可能是由于训练步数较少,进一步突出了潜在的训练不足问题。
在三个非“仅长输入”方案中,在长文本任务上的得分相近,而长输入预训练占比越高的方案在 ROUGE-2 和 ROUGE-L 指标上的表现略好。虽然分数的绝对差异较小,难以得出明确结论,但我们倾向于认为 在短输入预训练后加入一定比例的长输入预训练可以带来性能提升,尤其是在长文本摘要任务上。
我们基于上述发现,总结出 PEGASUS 模型(Zhang et al., 2020)适用于长序列摘要的调整方案如下:
- 采用 Global-Local 架构,使用 块交错(block staggering)**、**较多的全局 token,并在预训练阶段使用较大的块大小。
- 进行额外的长输入预训练,输入 4096 token,训练30 万步。
- 在微调时,扩展输入序列长度至 16384 token,具体长度取决于任务需求。
我们尝试了两种模型规模:
- PEGASUS-X(PEGASUS eXtended),基于 PEGASUSLarge。
- PEGASUS-XBase,基于新训练的 PEGASUSBase 模型,我们称之为PEGASUSBase+。
与 Hoffmann et al. (2022) 的发现类似,我们发现PEGASUSBase 受益于更多的训练 token,因此 PEGASUSBase+ 训练数据量与 PEGASUSLarge 相同。
我们初始化 PEGASUS-X 和 PEGASUS-XBase 的权重,分别使用PEGASUSLarge 和 PEGASUSBase+ 的预训练权重。
仅引入了两个新参数集:
- 全局 token 嵌入(global token embeddings)。
- 每个 Transformer 层的全局输入表示的独立 LayerNorm。
其中,PEGASUS-XBase 额外引入约 100 万参数**,**PEGASUS-X 额外引入约 200 万参数。
我们随机采样输入 token 嵌入 作为全局 token 嵌入的初始化,并 使用标准输入 LayerNorm 权重初始化全局 LayerNorm 权重。
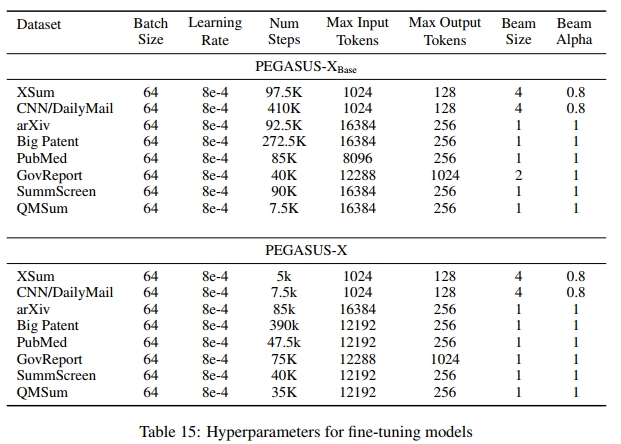
任务和模型的特定 微调超参数见 附录 15。
在本节中,我们报告 ROUGE-Lsum4 而非 ROUGE-L,以与其他论文和排行榜的指标保持一致。

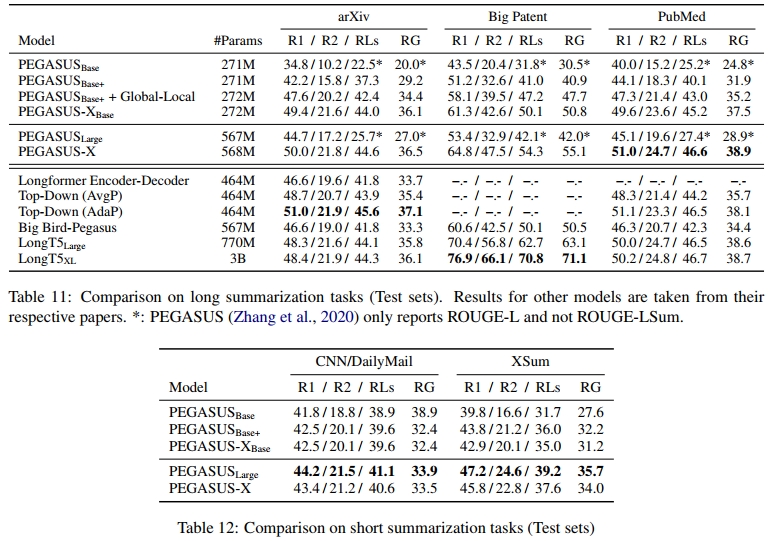
5.1 摘要任务的结果
长摘要任务:在表 11 中,我们比较了 PEGASUS 模型和 PEGASUS-X 在三个长输入摘要任务上的表现:arXiv、Big Patent 和 PubMed。在这三个任务中,PEGASUS-XBase 相较于 PEGASUSBase+,PEGASUS-X 相较于 PEGASUSLarge 都有显著的性能提升。为了单独评估额外的长输入预训练相对于仅切换架构以适应长输入序列的影响,我们还包括了使用 Global-Local 架构的 PEGASUS 模型的评估,这些模型没有进行进一步的预训练,在表中列为 PEGASUSBase+ + Global-Local。
我们还与使用 Big Bird 架构(Zaheer et al., 2020)、Longformer 编码器解码器(LED;Beltagy et al., 2020)、Top-Down Transformer(Pang et al., 2022)在平均池化(AvgP)和自适应池化(AdaP)变体、LongT5 的 Large 和 XL 大小,以及 SLED(Ivgi et al., 2022)报告的结果进行了比较。LED、Top-Down 和 SLED 都使用 BARTLarge 权重进行初始化,未对长输入序列进行额外的预训练,尽管 AdaP 使用了一个多步骤的微调设置(见下文)。
我们注意到,Big Bird-PEGASUS 仅使用了 3072 个 token 的上下文,这可能是由于 Big Bird 更大的内存消耗导致的。我们发现,PEGASUS-X 在所有任务上都优于 Big Bird-PEGASUS,并且在两个对比任务上都优于 Top-Down-AvgP。Top-Down-AdaP 仍然优于 PEGASUS-X,我们强调,Top-Down-AdaP 使用了更复杂的多步骤微调设置,涉及使用参考摘要上的重要性标记器来构建池化 token 的权重。相比之下,PEGASUS-X 使用标准的微调管道进行微调。尽管如此,PEGASUS-X 仍然在 PubMed 上优于使用自适应池化的 Top-Down。PEGASUS-X 还在 arXiv 和 PubMed 摘要任务上优于 LongT5,尽管对比的 LongT5 模型有更多的参数。然而,我们发现 LongT5 在 BigPatent 上表现更好,这是一个主要以抽取为主的摘要任务。我们推测,LongT5 的较大规模可能在对非常长的编码序列进行抽取时表现更好。
短摘要任务:我们在表 12 中展示了 PEGASUS 和 PEGASUS-X 模型在较短摘要任务上的表现。我们观察到,PEGASUS-X 模型的表现相比其 PEGASUS 对应模型略有回退。我们推测,长输入预训练可能会对短输入任务的表现产生负面影响,因为长文档的训练数据过滤方式不同,可能导致训练数据分布的多样性较差。
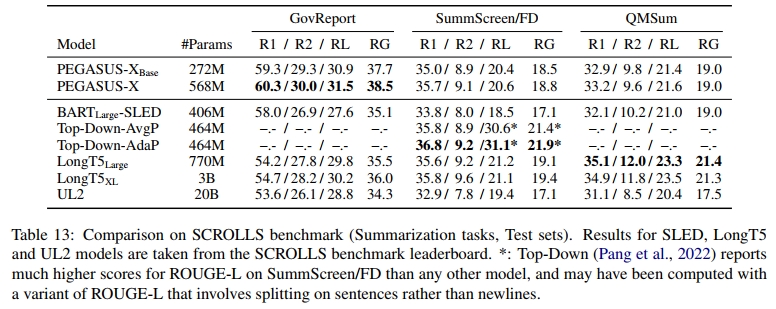
5.2 SCROLLS 摘要任务的结果
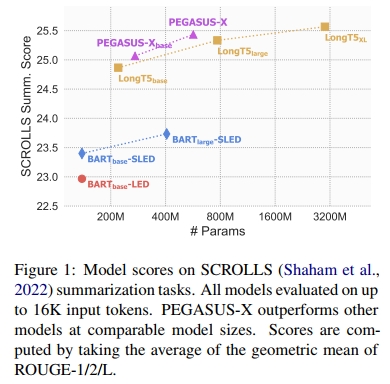
我们在表 13 中报告了 PEGASUS-X 模型在最近推出的 SCROLLS 基准中的摘要任务表现。该基准包括 GovReport(Huang et al., 2021)、SummScreen 的 ForeverDreaming 子集(Chen et al., 2022)和 QMSum(Zhong et al., 2021)。我们观察到,PEGASUS-X 在 GovReport 上优于所有其他模型,并且在该数据集上设置了新的最先进技术。PEGASUS-X 在 SummScreen/FD 上与 LongT5Large 和 Top-Down-AvgP 的表现相当,尽管在 QMSum 上不如两个 LongT5 模型。更重要的是,我们发现 PEGASUS-XBase 的表现也很有竞争力,在 GovReport 上优于两个 LongT5 模型,且在所有三个任务上仅稍微落后于 PEGASUS-X。PEGASUS-XBase 还优于 BARTLarge-SLED,一个具有类似 16K token 上下文长度的更大模型。PEGASUS-X 和 BARTLarge-SLED 的主要区别在于,PEGASUS-X 基于 PEGASUS,而 BARTLarge-SLED 基于 BART,且后者没有在长文档上进行额外的预训练。我们还注意到,UL2 仅使用 2K token 的上下文长度。
6 相关工作
长文档摘要:最近推出了几个人新的长输入摘要数据集和基准,为长输入摘要能力提供了更好的衡量标准,并且激发了这一研究方向的新兴趣。BookSum 数据集(Kryscinski et al., 2021)包含来自 Project Gutenberg 的书籍的段落、章节和完整摘要,基于从网络抓取的教育网站。(Chen et al., 2022)包含基于从网络抓取的粉丝写作的电视节目转录和剧集摘要。SCROLLS 基准(Shaham et al., 2022)和 MuLD 基准(Hudson 和 Al Moubayed, 2022)包含多个自然语言任务,涉及长输入,包括长输入摘要。SQuALITY 数据集(Wang et al., 2022a)包含来自 Project Gutenberg 故事的基于问题的摘要,注释员根据不同的问题编写摘要,这些问题涵盖了同一故事的不同方面。
高效 Transformer
近年来,许多高效的 Transformer 变种被提出(Tay et al., 2020),我们在这里讨论与本文更相关的工作。Beltagy et al. (2020) 使用全局 token 和滑动窗口局部注意力,通过自定义 CUDA 内核实现。ETC 模型(Ainslie et al., 2020)同时使用全局 token 和块级滑动窗口局部注意力,尽管全局注意力是基于序列的前几个 token 来合并的,而不是通过单独学习的全局 token 来实现。Zaheer et al. (2020) 通过添加随机注意力块扩展了 ETC,但我们发现这显著增加了代码复杂度和计算成本。Guo et al. (2021) 类似地扩展了 ETC 的块级滑动窗口注意力,但通过对 token 块进行池化计算瞬时的“全局 token”表示。Pang et al. (2022) 提出了通过增加额外的池化层来增强 Longformer 编码器-解码器,以改善长序列摘要性能。Ivgi et al. (2022) 提出了通过编码重叠块并在解码器中融合跨块信息来实现稀疏注意力的另一种方法。我们强调,尽管我们最终采用的 Global-Local 模型架构与几个其他提出的高效 Transformer 架构相似,但我们的关键贡献在于我们广泛的消融实验,识别了能改善(以及同样重要的,不改善)下游性能的架构调整。在长输入摘要的模型架构中,LongT5(Guo et al., 2021)与 PEGASUS-X 最为相似,共享类似的编码器-解码器架构、生成遮挡句子的类似训练目标,并且在编码器中混合使用局部注意力和全局信息共享。我们简要概述两者模型之间的关键区别。首先,LongT5 在长序列上从头开始训练,而我们则先使用在短序列上训练过的 PEGASUS 权重初始化模型权重,然后对长输入序列进行额外的预训练。这显著减少了整体预训练成本,因为短序列预训练可以更经济地执行。LongT5 还使用 T5 相对位置偏差,而 PEGASUS-X 使用正弦位置嵌入——如第 4.4 节所示,T5 相对位置偏差略有更好表现,但速度明显较慢。两者之间的高效编码器架构也有所不同:LongT5 使用基于池化 token 块的瞬时全局表示,而 PEGASUS-X 使用学习的全局 token 嵌入。LongT5 还使用基于 ETC(Ainslie et al., 2020)的滑动窗口局部注意力,而我们使用的是更简单的块局部注意力,并且是错位的块。最后,最大的 LongT5 模型有 30 亿个参数,是 PEGASUS-X 的 5 倍多。更广泛地说,Tay et al. (2021) 对多种高效 Transformer 架构进行了比较,评估了不同模型在长序列处理能力上的表现,以及计算需求。Tay et al. (2022) 进一步评估了新型 Transformer 架构的扩展属性,发现偏离完全注意力往往会损害下游性能。Xiong et al. (2022) 显示,简单的局部注意力变体在与更复杂的稀疏注意力方案竞争时具有高度竞争力,这与我们的发现一致。
7 结论
在这项工作中,我们探讨了一系列提出的改进方案,以使 Transformer 模型能够有效且经济地处理文本摘要任务中的长输入。通过广泛的消融实验,我们发现了一种简单但有效的方案,可以将短输入 Transformer 扩展以处理长输入摘要。基于我们的发现,我们提出了 PEGASUS-X,这是一个扩展版的 PEGASUS,具有修改后的架构和额外的长序列预训练。我们展示了 PEGASUS-X 在两个长输入摘要任务(GovReport 和 PubMed)上设置了最先进的技术,并且在许多其他任务中表现出色,即使它比一些对比模型要小得多。我们的发现还可以应用于扩展模型,以处理摘要以外其他领域的长输入序列,无论是从头开始预训练长输入模型,还是扩展已经预训练的短序列模型。
附录A 微调超参数
微调模型的超参数如表 15 所示。
附录B 工程细节
原始的 PEGASUS 模型是使用基于 TensorFlow 的代码库进行训练的。本文中的实验使用了一个新的代码库,该代码库是用 JAX(Bradbury et al., 2018)和 Flax(Heek et al., 2020)编写的。PEGASUS-XBase 和 PEGASUS-X 通过将 TensorFlow 检查点的权重转换为 Flax 检查点格式,然后继续进行长输入训练来进行训练。
论文名称:
Investigating Efficiently Extending Transformers for Long Input Summarization
论文地址:
https://arxiv.org/pdf/2208.04347



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











