







摘要
本文介绍了 Facebook FAIR 在 WMT19 共享新闻翻译任务中的提交。我们参与了两个语言对和四个翻译方向,即英语↔德语(English ↔ German)和英语↔俄语(English ↔ Russian)。与去年提交的系统类似,我们的基线系统是基于 BPE 的大型 Transformer 模型,这些模型使用 FAIRSEQ 序列建模工具包进行训练,并依赖于采样的反向翻译(back-translation)。今年,我们尝试了不同的双语数据过滤方案,并添加了经过筛选的反向翻译数据。我们还通过集成(ensemble)和针对特定领域数据进行微调(fine-tuning)来优化模型,然后使用噪声信道模型(noisy channel model)重排序进行解码。在人工评估排名中,我们的提交在所有四个翻译方向上均排名第一。在 En→De 方向,我们的系统不仅显著优于其他系统,还超越了人工翻译。相比我们的 WMT’18 提交系统,该系统在 BLEU 评分上提高了 4.5 分。
1 引言
我们参与了 WMT19 共享新闻翻译任务,涵盖两个语言对和四个翻译方向,即英语→德语(En→De)、德语→英语(De→En)、英语→俄语(En→Ru)和俄语→英语(Ru→En)。我们的方法基于去年的提交(Edunov 等, 2018),包括使用子词模型(Sennrich 等, 2016)、大规模反向翻译和模型集成。所有模型均使用 FAIRSEQ 序列建模工具包(Ott 等, 2019)进行训练。尽管 En→De 方向现在支持文档级上下文信息,我们所有的系统仍然是纯句子级的系统。未来,我们预计利用这些额外的上下文信息可以进一步提升效果。
与 WMT18 相比,我们今年新增了 En↔Ru 和 De→En 方向。尽管所有四个方向都属于高资源场景(拥有大量双语数据),我们仍然证明了利用高质量的单语数据进行反向翻译仍然至关重要。对于所有语言方向,我们都使用反向方向的双语系统对 Newscrawl 数据集进行反向翻译。除了对相对干净的 Newscrawl 进行反向翻译,我们还尝试对更大、更嘈杂的 Commoncrawl 数据集进行部分反向翻译。在最终模型中,我们采用了针对特定领域的微调,并使用噪声信道模型重排序进行解码(Anonymous, 2019)。
相较于 WMT18 提交的 En→De 方向,我们的系统在 BLEU 评分上提升了 4.5 分。这些提升部分归因于数据集质量的变化,但我们认为主要改进来源于更大的模型、更大规模的反向翻译以及使用强信道和语言模型的噪声信道模型重排序。
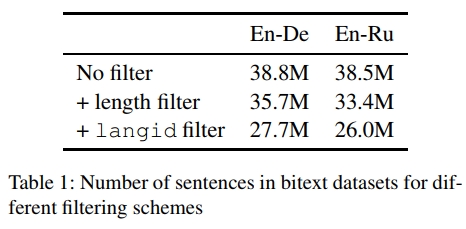
2 数据
对于 En↔De 语言对,我们使用了所有可用的双语数据,包括经过 bicleaner 处理的 Paracrawl 数据集。单语数据方面,我们使用了英语和德语的 Newscrawl。尽管我们的语言模型是在文档级数据上训练的,但在最终解码步骤中并未使用文档级边界,因此我们的系统仍然是纯句子级的。
对于 En↔Ru 语言对,我们同样使用了所有可用的双语数据。单语数据方面,我们使用了英语和俄语的 Newscrawl,并额外筛选了部分俄语 Commoncrawl 数据集。我们之所以选择使用俄语 Commoncrawl 来扩充单语数据,是因为俄语 Newscrawl 数据集的规模相较于英语和德语要小得多。
2.1 数据预处理
与去年提交的 En→De 方向类似,我们对所有数据进行了标点符号规范化,并使用 Moses 分词工具(Koehn 等, 2007)进行分词。对于 En↔De 语言对,我们使用了 32K 次拆分操作的联合 BPE 进行子词切分(Sennrich 等, 2016)。对于 En↔Ru 语言对,我们分别为每种语言单独训练了 24K 次拆分操作的 BPE 编码。实验表明,使用单独 BPE 编码训练的系统远优于使用联合 BPE 训练的系统。
2.2 数据筛选
2.2.1 双语数据
从互联网抓取的大型数据集通常非常嘈杂,如果直接使用原始数据,可能会降低系统性能。因此,清理这些数据是提升系统效果的重要步骤。
我们应用了语言识别筛选(langid;Lui 等, 2012),仅保留正确语言对的句子对。尽管 langid 并非最准确的语言识别方法(Joulin 等, 2016),但它的一个副作用是可以去除极端嘈杂的句子,这些句子主要由无意义的字符组成,往往会被错误分类并因此被筛除。
此外,我们去除了长度超过 250 个词的句子,并删除了源/目标长度比超过 1.5 的句子对。总体而言,我们过滤掉了约 30% 的原始双语数据。双语数据集的具体规模详见表 1。
2.2.2 单语数据
对于单语 Newscrawl 数据,我们同样应用了 langid 过滤。由于俄语的单语 Newscrawl 语料库比德语或英语的规模小得多,我们使用 Commoncrawl 语料库的数据来扩充俄语的单语数据。
Commoncrawl 是可用于训练的最大单语语料库,但它也非常嘈杂。为了从这个庞大的语料库中筛选出数量有限的高质量、领域内的句子,我们采用了 Moore 和 Lewis(2010)提出的领域内数据选择方法(§3.2.1)。
3 系统概述
3.1 基础系统
我们的基础系统基于 FAIRSEQ 实现的大型 Transformer 架构(Vaswani 等, 2017)。我们通过增加嵌入维度(embed dimension)、前馈网络(FFN)大小、注意力头(heads)数量和层数来提升网络容量。实验表明,使用更大的 FFN(8192)可以在保持网络规模可控的同时带来合理的性能提升。因此,所有后续模型(包括集成模型)均采用此较大的 FFN Transformer 架构。
所有模型均使用 FAIRSEQ(Ott 等, 2019)在 128 块 Volta GPU 上进行训练,训练设置遵循 Ott 等(2018)的方法。
3.2 大规模反向翻译
反向翻译(back-translation)是一种有效且常用的数据增强技术,可以将单语数据引入翻译系统。其基本流程是:首先训练一个目标语到源语的中间翻译模型,然后利用该模型将单语目标语数据翻译成额外的合成平行数据。这些合成数据与人工翻译的双语数据一起用于训练最终的源语到目标语翻译系统。
在本研究中,我们使用了从一个三模型集成(ensemble)的目标语到源语模型中采样(sampling)的反向翻译数据(Edunov 等, 2018)。实验表明,相较于使用单个模型进行反向翻译,使用集成模型生成的反向翻译数据可以带来更好的系统性能(表 2)。先前的研究还发现,适当增加双语数据的采样权重可以进一步改善反向翻译的效果(Edunov 等, 2018)。我们采用了该方法来调整模型训练时双语数据与合成数据的比例,实验表明,1:1(合成数据:双语数据)的比例效果最佳。
3.2.1 反向翻译 Commoncrawl 数据
Newscrawl 数据集中可用的俄语单语数据量远少于英语和德语(表 3)。为了增加用于反向翻译的俄语单语数据,我们尝试引入 Commoncrawl 语料库。与 Newscrawl 相比,Commoncrawl 语料库规模更大,数据噪声更高,并且不特定于某一领域。
因此,我们尝试采用特定方法筛选出与 Newscrawl 语料库最相似的 Commoncrawl 子集。具体而言,我们采用 Moore 和 Lewis(2010)提出的领域内数据过滤方法进行筛选。
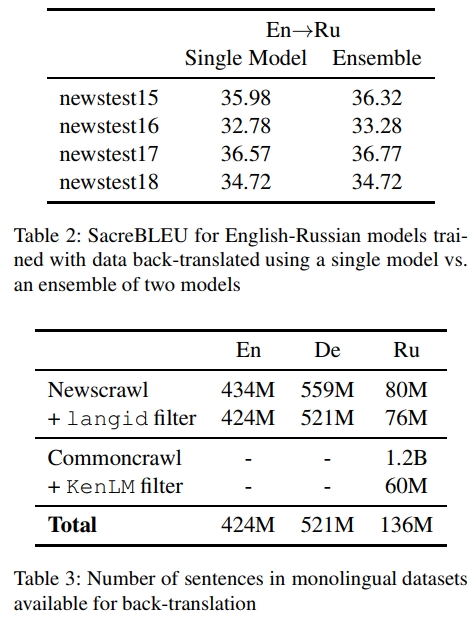
给定一个领域内语料库 I I I(在本研究中为 Newscrawl)和一个非特定领域的语料库 N N N(在本研究中为 Commoncrawl),我们的目标是找到从与 I I I相同的分布中抽取的子语料库 N I N _ { I } NI。
对于任意句子 s s s,我们可以利用贝叶斯公式计算该句子 s s s属于 N I N _ { I } NI的概率:
P ( N I ∣ s , N ) = P ( s ∣ N I ) P ( N I ∣ N ) P ( s ∣ N ) (1) P ( N _ { I } | s , N ) = \frac { P ( s | N _ { I } ) P ( N _ { I } | N ) } { P ( s | N ) } \tag{1} P(NI∣s,N)=P(s∣N)P(s∣NI)P(NI∣N)(1)
我们忽略 P ( N I ∣ N ) P ( N _ { I } | N ) P(NI∣N)项,因为对于给定的 I I I和 N N N该值是一个常数。此外,我们使用 P ( s ∣ I ) P ( s | I ) P(s∣I)代替 P ( s ∣ N I ) P ( s | N _ { I } ) P(s∣NI),因为 I I I和 N I N _ { I } NI具有相同的分布。
转换到对数域后,句子 s s s的概率分数可以计算为:
log P ( N I ∣ s , N ) = log P ( s ∣ I ) − log P ( s ∣ N ) \log P ( N _ { I } | s , N ) = \log P ( s | I ) - \log P ( s | N ) logP(NI∣s,N)=logP(s∣I)−logP(s∣N)
归一化长度后,该公式可以表示为:
H I ( s ) − H N ( s ) H _ { I } ( s ) - H _ { N } ( s ) HI(s)−HN(s)
其中, H I ( s ) H _ { I } ( s ) HI(s)和 H N ( s ) H _ { N } ( s ) HN(s)分别表示由在 I I I和 N N N上训练的语言模型 L I L _ { I } LI和 L N L _ { N } LN计算得到的、基于词的归一化交叉熵分数。
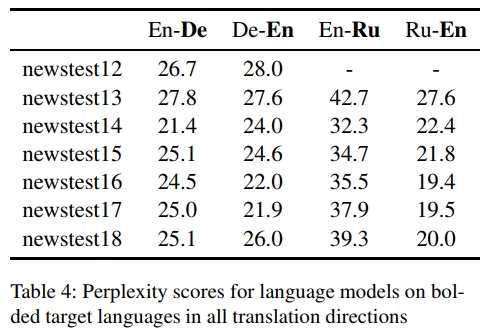
由于我们的语料库非常庞大,因此我们使用 n-gram 语言模型(Heafield, 2011),而不是神经语言模型,因为后者的训练和推理速度较慢。我们分别在 Newscrawl 和 Commoncrawl 语料库上训练两个语言模型 L I L _ { I } LI和 L N L _ { N } LN,然后计算 Commoncrawl 中每个句子的分数 H I ( s ) − H N ( s ) H _ { I } ( s ) - H _ { N } ( s ) HI(s)−HN(s)。我们设定了一个 0.01 的阈值,并选择所有得分高于该值的句子用于反向翻译,这些句子约占整个数据集的 5%。
3.3 微调(Fine-tuning)
使用特定领域的数据进行微调是一种常见且有效的方法,可提升翻译系统在特定任务上的翻译质量。在完成双语数据和反向翻译数据的训练后,我们会在一个较小的领域内语料库上额外训练一个 epoch 进行微调。
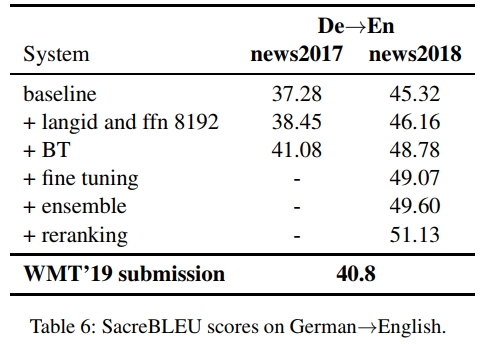
对于 德语 → 英语(De→En),我们在往年的测试集上进行微调,包括 newstest2012、newstest2013、newstest2015 和 newstest2017。
对于 英语 → 德语(En→De),我们除了使用往年的测试集外,还使用 News-Commentary 语料库进行微调。
对于英语 ↔ 俄语(En↔Ru),我们使用 News-Commentary、newstest2013、newstest2015 和 newstest2017进行微调。
其他测试集被保留用于其他调优过程和评估指标。
3.4 噪声信道模型重排序(Noisy Channel Model Reranking)
N-best 重排序是一种提高翻译质量的方法,它通过对 n-best 候选翻译 进行评分并选择最优候选项。在本次提交中,我们采用 噪声信道模型进行重排序。
给定目标序列 y y y和源序列 x x x,噪声信道方法利用贝叶斯公式 建模如下:
P ( y ∣ x ) = P ( x ∣ y ) P ( y ) P ( x ) (2) P ( y | x ) = \frac { P ( x | y ) P ( y ) } { P ( x ) } \tag{2} P(y∣x)=P(x)P(x∣y)P(y)(2)
由于对于给定的源序列 x x x, P ( x ) P ( x ) P(x)是一个常数,因此我们可以忽略它。剩下的两项分别是:
- P ( x ∣ y ) P ( x | y ) P(x∣y):信道模型(Channel Model)
- P ( y ) P ( y ) P(y):语言模型(Language Model)
此外, P ( y ∣ x ) P ( y | x ) P(y∣x) 被称为前向模型(Forward Model)。
为了结合这些得分进行重排序,我们对 n-best 候选翻译计算以下分数:
log P ( y ∣ x ) + λ 1 log P ( x ∣ y ) + λ 2 log P ( y ) (3) \log P ( y | x ) + \lambda _ { 1 } \log P ( x | y ) + \lambda _ { 2 } \log P ( y ) \tag{3} logP(y∣x)+λ1logP(x∣y)+λ2logP(y)(3)
其中, λ 1 \lambda _ { 1 } λ1和 λ 2 \lambda _ { 2 } λ2是需要调整的权重参数。我们使用 随机搜索(random search) 在验证集上进行调优,并选择最优的参数组合。此外,我们还调整了长度惩罚项(length penalty) 以进一步优化最终翻译结果。
对于所有翻译方向,我们的前向模型都是由经过微调和反向翻译训练的模型集成而成。由于我们在两个语言对的双向翻译任务中均有参赛,因此在任何特定的翻译方向上,我们都可以使用相反方向的前向模型作为信道模型。
我们的目标语言(英语、德语和俄语)的语言模型是采用前馈神经网络(FFN)大小为8192的大型 Transformer 解码器模型。我们在单语 Newscrawl 语料库上训练语言模型,并在英语和德语模型中使用文档级上下文。各语言模型在其翻译方向中的目标语言上的困惑度评分列于表4。由于俄语单语数据量较少,我们观察到俄语语言模型的表现低于德语和英语语言模型。
在解码过程中,我们使用随机搜索选择长度惩罚和权重 λ1 和 λ2,权重的选择范围为 [0,2),长度惩罚的选择范围为 [0,1)。对于所有语言方向,我们选择在 newstest2014 和 newstest2016 组合数据集上使 BLEU 分数最高的权重。
最终解码步骤如下:
- 先使用前向模型进行束搜索(束大小为50),生成 n-best 候选列表。
- 使用信道模型和语言模型对 n-best 候选翻译进行评分,采用之前调优得到的权重和长度惩罚。
- 选择得分最高的候选翻译作为最终输出。
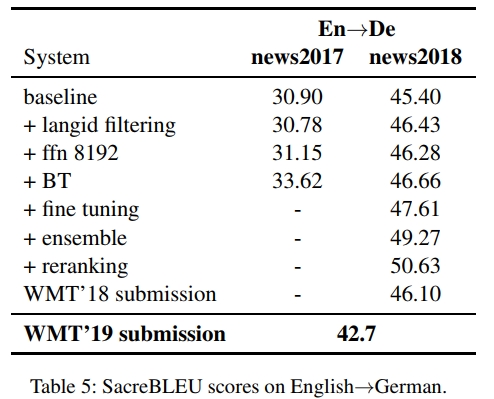
4 结果
En→De 的实验结果和消融实验见表 5,De→En 见表 6,En→Ru 见表 7,Ru→En 见表 8。我们使用 SacreBLEU (Post, 2018) 计算区分大小写的 SacreBLEU 分数,其中 En→Ru 方向采用国际化分词方式。在每个表格的最后一行,我们还报告了本年度测试集上提交系统的区分大小写 BLEU 分数。所有单个模型以及集成中的个体模型均为训练过程中最后 10 个检查点的平均结果。我们的基线系统是采用 (Vaswani et al., 2017) 所述的大型 Transformer 模型。基线系统使用最少的数据过滤,仅删除长度超过 250 个词或源/目标长度比超过 1.5 的句子,这样的设置为我们提供了一个合理的基线,以评估数据过滤的效果。
4.1 英语→德语
在 En→De 方向,langid 过滤、更大的 FFN 以及集成模型使得我们的基线系统在 news2018 上的 BLEU 分数提升了约 1.5。值得注意的是,我们最好的仅使用双语数据的系统已经比去年的系统高出 1 BLEU 分,这可能是由于更高质量的双语数据和改进的数据过滤技术的引入。添加反向翻译(BT)数据后,单模型的 BLEU 分数仅提高 0.3,但结合微调和集成后,总共提升了 3 BLEU。最后,在这些强大的集成系统基础上应用重排序进一步提升了 1.4 BLEU。
4.2 德语→英语
对于 De→En 方向,与 En→De 类似,我们也观察到 langid 过滤、更大的 FFN 和集成模型使得 BLEU 分数提高了约 1.4。与 En→De 相比,我们还发现反向翻译数据的加入更加显著,使得单模型的性能提高了超过 2.5 BLEU。微调、集成和重排序进一步提高了 2.4 BLEU,其中重排序贡献了 1.5 BLEU,占据了大部分的改进。
4.3 英语→俄语
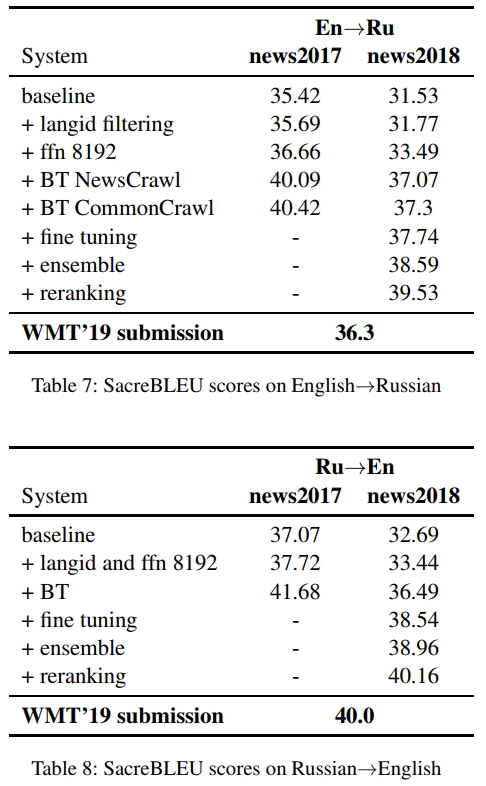
对于 En→Ru 方向,我们观察到,在应用了 langid 过滤、更大的 FFN 和集成模型后,相比仅使用双语数据的模型,性能提高了 2.4 BLEU。由于我们从一个质量较低的初始 En↔Ru 双语数据集开始,添加反向翻译数据后,我们观察到 BLEU 提升了 3.5。用 Commoncrawl 数据增强这些反向翻译数据,进一步提高了 0.2 BLEU。最后,应用微调、集成和重排序增加了 2.2 BLEU,其中重排序贡献了 1 BLEU。
4.4 俄语→英语
对于 Ru→En 方向,我们观察到与 En↔De 类似的趋势,langid 过滤、更大的 FFN 和集成模型使得仅使用双语数据的系统性能提高了 1.6 BLEU。反向翻译增加了 3 BLEU,这同样可能是由于可用的双语数据质量较低。微调、集成和重排序提高了接近 4 BLEU,其中重排序贡献了 1.2 BLEU。
4.5 重排序
对于每个语言方向,重排序都带来了显著的改进,即使是在强大的反向翻译模型集成的基础上应用重排序时,我们也观察到提升。我们还发现,最大的改进出现在 De→En 方向,提升了 1.5 BLEU,而最小的改进出现在 En→Ru 方向,提升了 1 BLEU。这可能是由于俄语语言模型相对较弱,它的训练数据量远低于英语和德语。改善我们的语言模型可能会使得重排序带来更大的提升。
4.6 人工评估
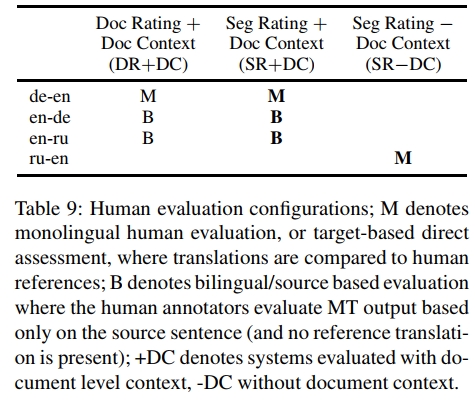
我们所有系统都参与了WMT’19的人工评估活动。针对不同系统,采用了不同评估方式:除俄→英系统外,所有系统均在文档级上下文环境中进行评估,并收集了文档级评分。对于从英语翻译的系统采用基于源语的直接评估,而翻译至英语的系统则采用基于目标语的直接评估(详见表9)。
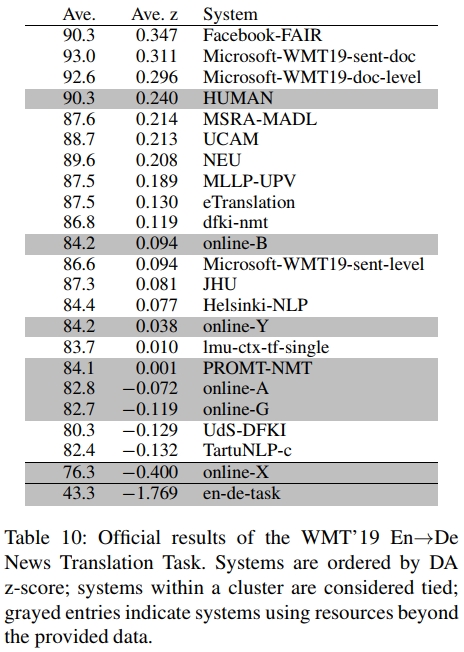
Facebook-FAIR在我们参与的四个语言方向上均排名第一。表10显示,我们的英→德提交系统显著优于其他系统及人工翻译结果。在德→英、英→俄和俄→英任务中,我们的系统同样获得了最高分。
尽管我们的系统纯属句子级模型,但无论评估是否使用文档上下文都表现优异。在文档级排名中,英→德系统同样位居榜首且显著超越人工翻译。英→俄系统在所有提交中得分最高,与人工翻译并列第一。德→英系统在受限系统中排名第二(详见Bojar等人2019年报告)。
5 结论
本文阐述了Facebook FAIR参与WMT19新闻翻译任务的技术方案。针对英德互译和英俄互译四个方向,我们采用统一策略:先过滤双语数据,对单语数据进行基于采样的回译,随后组合数据训练强个体模型。每个模型都经过微调并集成至最终系统,通过噪声信道模型重排序进行解码。实验证明,即使在强大系统基础上应用,我们的噪声信道重排序方法仍具显著优势,最终在人工评估的所有四个方向中均获第一。
论文名称:
Facebook FAIR’s WMT19 News Translation Task Submission
论文地址:
https://arxiv.org/pdf/1907.06616



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











