







摘要
视觉-语言基础模型的巨大成功推动了计算机视觉和多模态表示学习的研究与应用。然而,将此类基础模型有效迁移到特定语言场景仍然存在困难。在本研究中,我们提出了 Chinese CLIP,并采用两阶段预训练方法:第一阶段进行锁定图像微调(locked-image tuning),第二阶段进行对比学习微调(contrastive tuning)。具体而言,我们开发了 5 种不同规模的 Chinese CLIP 模型,参数量从 7700 万到 9.58 亿不等,并在收集的大规模中文图文对数据集上进行了预训练。我们的综合实验表明,Chinese CLIP 在 MUGE、Flickr30K-CN 和 COCO-CN 数据集的零样本学习(zero-shot learning)和微调(finetuning)设置下均实现了最先进(state-of-the-art, SOTA)的性能,并在 ELEVATER 基准测试中展现出具有竞争力的零样本图像分类能力。我们已公开代码、模型及演示。
1 引言
自 NLP 领域预训练技术爆发以来,基础模型(foundation models)受到了多个研究领域的关注。基础模型通过大规模无监督或弱监督数据学习,成为下游任务模型的基石。多模态表示学习领域的一个重要里程碑是 CLIP(Radford et al., 2021)。不同于传统的生成式预训练,CLIP 采用基于对比学习的训练方法,在从互联网上收集的大约 4 亿对图文数据集上进行预训练。尽管方法简单,CLIP 不仅在视觉-语言检索任务上取得了卓越表现,更重要的是,它作为一个视觉基础模型,在一系列数据集上的零样本图像分类任务中展现了最先进的性能。CLIP 构建了视觉与语言之间的联系,正在深刻改变多模态表示学习和计算机视觉领域的研究方向。
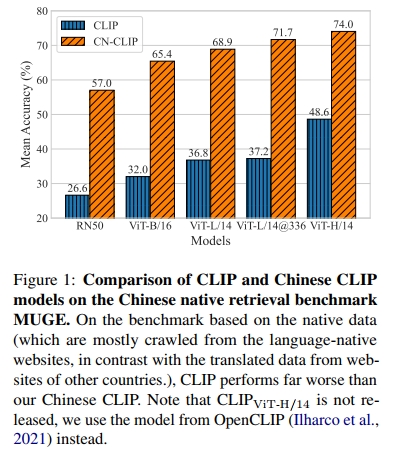
尽管如此,将跨模态预训练模型高效迁移到另一种语言仍然面临诸多挑战。首先,学习建模目标语言的视觉-语言数据分布对于迁移至关重要。尽管 CLIP 作为基础模型在大多数场景下表现出色,但我们发现,仅依靠机器翻译的 CLIP 在中文跨模态检索任务上的表现并不理想。图 1 展示了原始 CLIP 与我们的 Chinese CLIP 在所有模型规模上的巨大性能差距。我们认为,让两个编码器(视觉编码器和文本编码器)从目标语言的图像和文本中学习至关重要。其次,以往针对中文多模态预训练的方法受到多个因素的限制。从零开始进行预训练需要收集一个大规模、高质量的语言特定图文对数据集,类似于 OpenAI CLIP 使用的 Web Image Text(WIT)(Fei et al., 2021; Xie et al., 2022)。尽管可以通过 CLIP 初始化和 Locked-Image Tuning(LiT)(Zhai et al., 2022)快速将 CLIP 迁移至中文数据,但视觉编码器仍然无法从语言特定领域的图像中学习信息(Gu et al., 2022)。
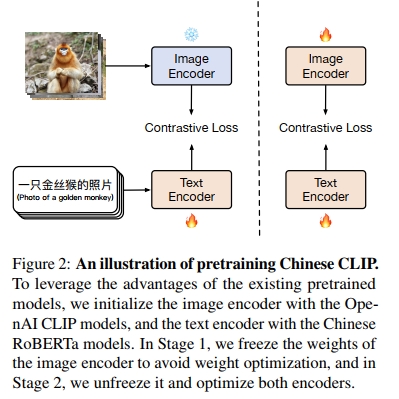
因此,我们提出了 Chinese CLIP,一个专门针对中文的视觉-语言基础模型,并在公开可用的中文图文对数据集上进行预训练。此外,我们仍然采用与 OpenAI CLIP 相同的模型架构。为了实现跨模态基础模型向中文数据的高效迁移,我们设计了一种 两阶段预训练方法,该方法同样适用于其他视觉-语言基础模型(如 ALIGN、Florence 等)。在本研究中,我们以 CLIP 为示例。具体而言,我们首先使用预训练模型初始化两个编码器,即来自 CLIP 的视觉编码器和来自 RoBERTa-wwm-Chinese(Cui et al., 2020)的文本编码器。在 第一阶段,我们冻结图像编码器,仅优化文本编码器,并采用 LiT 方法;在 第二阶段,我们对两个编码器进行对比学习微调(contrastive tuning)。通过这种方式,新模型可以通过初始化和 LiT 继承基础模型的能力,并通过对比学习微调实现高效的语言特定数据迁移。
我们在三个中文跨模态检索数据集上评估了Chinese CLIP,包括 MUGE**、Flickr30K-CN(Lan et al., 2017)和 COCO-CN(Li et al., 2019c)。实验结果表明,无论是在零样本学习还是微调场景下,大规模和超大规模的 Chinese CLIP 均在三个数据集上达到了最先进(SOTA)的性能。此外,我们还在 ELEVATER 基准测试(Li et al., 2022b)“Image Classification in the Wild” 赛道上评估了其零样本图像分类能力。在分类任务上,Chinese CLIP 相较于其他最先进的方法表现出竞争力,并且优于现有的中文基线模型。
此外,我们提供了NVIDIA TensorRT 和 ONNX 部署模型,其推理速度比 PyTorch 模型快约 2 到 10 倍。
主要贡献
- 我们提出了 Chinese CLIP,这是一个基于我们收集的大规模中文图文对数据进行预训练的 CLIP 实现,并提出了一种 两阶段预训练方法,提高了预训练效率并提升了下游任务的表现。
- Chinese CLIP 在跨模态检索任务中,无论是在零样本学习还是微调设定下,均实现了 最先进(SOTA)性能,并在零样本图像分类任务中表现出竞争力。
2 方法
CLIP(Radford et al., 2021)基于大规模弱监督数据进行简单的视觉-语言对比学习预训练,是多模态表示学习领域的重要基础模型。它可以直接用于跨模态检索,并且其图像编码器可以作为视觉骨干网络。在本研究中,我们提出了一种基于大规模中文多模态数据预训练的语言特定 CLIP 模型。接下来,我们将详细介绍 Chinese CLIP 的方法设计与实现。
2.1 数据
CLIP 取得成功的关键之一在于其用于预训练的大规模数据集。根据 CLIP 复现实验(Ilharco et al., 2021),扩展数据规模并延长训练过程能够持续提升模型在零样本学习中的性能。今年,最新的多模态预训练模型 Wukong(Gu et al., 2022)和 R2D2(Xie et al., 2022)分别在包含 1 亿个图文对的公开数据集和包含 2.5 亿个样本的内部数据集上进行预训练,但仅公开了 2300 万个样本。为了便于复现,我们的目标是尽可能利用公开可用的数据来预训练 Chinese CLIP,因此我们专注于收集高质量的公共数据集。我们从最新的 LAION-5B(Schuhmann et al., 2021)中提取带有“zh”标记的中文数据,并收集 Wukong 数据集的数据。然而,由于部分链接不可用,我们最终仅能从 LAION-5B 和 Wukong 数据集中分别收集到约 1.08 亿和 7200 万个样本。此外,我们还添加了从经典英文多模态数据集翻译而来的数据,包括 Visual Genome(Krishna et al., 2017)和 MSCOCO(Chen et al., 2015),其中测试集已被移除。最终,我们构建了一个包含约 2 亿个图文对的中文多模态预训练数据集。
以下是数据预处理的流程。对于 LAION-5B 数据,我们使用 mCLIP(Carlsson et al., 2022)计算 CLIP 分数,并移除得分低于 0.26 的样本。此外,我们删除包含内部黑名单词汇的样本,该黑名单包括与广告、图片文件名等相关的词汇。同时,我们移除过短(少于 5 个字符)或过长(多于 50 个字符)的文本样本。对于图像,我们将其调整为 224 × 224 分辨率,大多数情况下使用该分辨率,而对于 ViT-L/14@336px,我们采用 336 × 336 的分辨率。
2.2 预训练方法
在预训练 Chinese CLIP 模型时,有多种设计选择。其中最简单的方法是从零开始预训练,即图像和文本编码器均随机初始化。然而,我们认为当前预训练数据的数量和质
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2943
2943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











