








 超级会员免费看
超级会员免费看

摘要
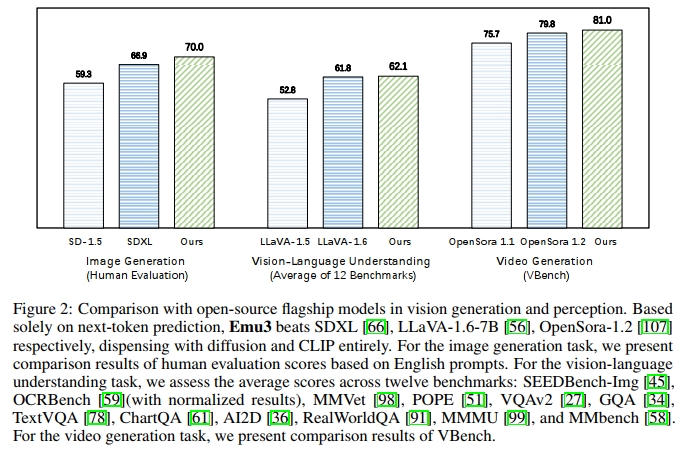
尽管下一词预测被认为是实现通用人工智能的一条有前景的路径,但它在多模态任务中的表现一直不尽如人意,这些任务目前仍以扩散模型(如Stable Diffusion)和组合方法(如CLIP结合LLMs)为主导。本文介绍了Emu3,这是一套全新的、仅通过下一词预测训练的最先进多模态模型。通过将图像、文本和视频标记化到一个离散空间中,我们在多模态序列的混合数据上从头训练了一个单一的Transformer模型。Emu3在生成和感知任务中均超越了多个成熟的特定任务模型,超越了SDXL和LLaVA-1.6等旗舰模型,同时消除了对扩散或组合架构的需求。Emu3还能够通过预测视频序列中的下一词来生成高保真视频。我们通过专注于一个单一的核心——标记,简化了复杂的多模态模型设计,释放了在训练和推理过程中扩展的巨大潜力。我们的结果表明,下一词预测是构建超越语言的通用多模态智能的一条有前景的路径。我们开源了关键技术和模型,以支持这一方向的进一步研究。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











