







 本文深入探讨Spark作业的运行架构,从Spark作业提交、运行模式、算子分类到RDD特性,详细解析了map、flatmap、reduceByKey、groupByKey、aggregateByKey的区别。此外,还介绍了内存不足的处理策略、Spark与MapReduce的效率差异,以及Spark如何与Kafka对接的两种方式,并对比了Receiver方式与Direct方式的优缺点。
本文深入探讨Spark作业的运行架构,从Spark作业提交、运行模式、算子分类到RDD特性,详细解析了map、flatmap、reduceByKey、groupByKey、aggregateByKey的区别。此外,还介绍了内存不足的处理策略、Spark与MapReduce的效率差异,以及Spark如何与Kafka对接的两种方式,并对比了Receiver方式与Direct方式的优缺点。
文章目录
- 1.Spark作业运行架构
- 2.Spark有几种运行模式
- 3.Spark的算子分类
- 4.RDD的五个特征
- 5.RDD,DataFrame,DataSet的区别
- 6.map和flatmap的区别
- 7.educeByKey、groupByKey和combineByKey、aggregateByKey的区别
- 8.spark中rdd.persist()和rdd.cache()的区别
- 8.spark内存不足怎么处理?
- 9.mapreduce和spark计算框架效率区别的原因
- 10.Spark数据倾斜怎么处理?
- 11.Spark如何和kafka对接?
- 12.storm V.S. sparkStraming的优缺点
- 13.SparkStreaming V.S. Flink
1.Spark作业运行架构
(1)、将编写的程序打成 jar 包,调用 spark-submit 脚本提交任务到集群上运行
(2)、运行 sparkSubmit 的 main 方法,在这个方法中通过反射的方式创建我们编写的主类的实例对象,然后调用 main 方法,开始执行我们的代码(注意,我们的 spark 程序中的 driver就运行在 sparkSubmit 进程中)
(3)、当代码运行到创建 SparkContext 对象时,那就开始初始化 SparkContext 对象了
(4)、在初始化 SparkContext 对象的时候,会创建两个特别重要的对象,分别是:DAGScheduler 和 TaskScheduler,初始化 DAG Scheduler、 Task Scheduler。
【DAGScheduler 的作用】依据 RDD 的宽依赖切分成一个一个的 stage,然后将 stage 作为 taskSet提交给 DriverActor
(5)、在构建 TaskScheduler 的同时,会创建两个非常重要的对象,分别是 DriverActor 和ClientActor
【clientActor 的作用】向 master 去进行注册并申请资源(CPU Core 和 Memory)
【DriverActor 的作用】接受 executor 的反向注册,将任务提交给 executor
(6)、当 ClientActor 启动后,会将用户提交的任务和相关的参数封装到 ApplicationDescriptio对象中,然后提交给 master 进行任务的注册
(7)、当 master 接受到 clientActor 提交的任务请求时,会将请求参数进行解析,并封装成Application,然后将其持久化,然后将其加入到任务队列 waitingApps 中
(8)、当轮到我们提交的任务运行时,就开始调用 schedule(),进行任务资源的调度
(9)、master 将调度好的资源封装到 launchExecutor 中发送给指定的 worker
(10)、worker 接受到 Master 发送来的 launchExecutor 时,会将其解压并封装到 ExecutorRunner中,然后调用这个对象的 start(), 启动 Executor
(11)、Executor 启动后会向 DriverActor 进行反向注册
(12)、driverActor 会发送注册成功的消息给 Executor
(13)、Executor 接受到 DriverActor 注册成功的消息后会创建一个线程池,用于执行 DriverActor发送过来的 task 任务
(14)、当属于这个任务的所有的 Executor 启动并反向注册成功后,就意味着运行这个任务的环境已经准备好了,driver 会结束 SparkContext 对象的初始化,也就意味着 new SparkContext这句代码运行完成
(15)、当初始化 sc 成功后,driver 端就会继续运行我们编写的代码,然后开始创建初始的 RDD,然后进行一系列转换操作,当遇到一个 action 算子时,也就意味着触发了一个 job
(16)、driver 会将这个 job 提交给 DAGScheduler
(17)、DAGScheduler 将接受到的 job,从最后一个算子向前推导,将 DAG 依据宽依赖划分成一个一个的 stage,然后将 stage 封装成 taskSet,并将 taskSet 中的 task 提交给 DriverActor
(18)、DriverActor 接受到 DAGScheduler 发送过来的 task,会拿到一个序列化器,对 task 进行序列化,然后将序列化好的 task 封装到 launchTask 中,然后将 launchTask 发送给指定的Executor
(19)、Executor 接受到了 DriverActor 发送过来的 launchTask 时,会拿到一个反序列化器,对launchTask 进行反序列化,封装到 TaskRunner 中,然后从 Executor 这个线程池中获取一个线程,将反序列化好的任务中的算子作用在 RDD 对应的分区上.
2.Spark有几种运行模式
4种:standalone模式,Local模式,Spark on YARN 模式,mesos模式。
Spark提供了一个容易上手的应用程序部署工具bin/spark-submit,可以完成Spark应用程序在local、Standalone、YARN、Mesos上的快捷部署。可以指定集群资源master,executor/ driver的内存资源等。
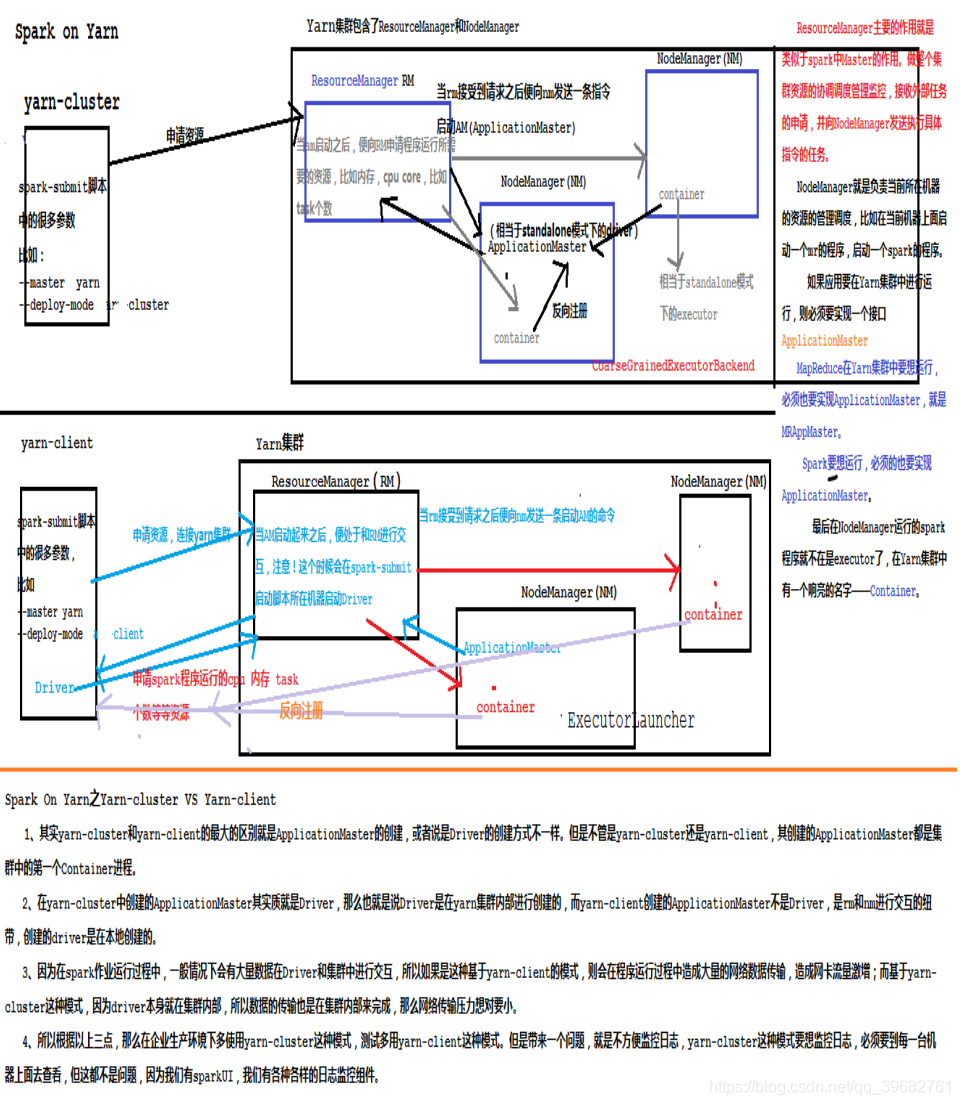
Spark如何指定本地模式:
在IDEA,Eclipse里面new SparkConf().setMaste开发的模式就是Local模式。还有,我们直接用Spark-Shell这种进来的模式也是local。
new SparkConf().setMaster(“local”),这时候默认的分区数 = 你的本台服务器的CPU core的个数。
new SparkConf().setMasater(“local[N]”) 这个时候分区的个数 = N
分区数 = task 的个数
3.Spark的算子分类
1)Transformation 变换/转换算子:这种变换并不触发提交作业,完成作业中间过程处理。
Transformation 操作是延迟计算的,也就是说从一个RDD 转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
2)Action 行动算子:这类算子会触发 SparkContext 提交 Job 作业。
Action 算子会触发 Spark 提交作业(Job),并将数据输出 Spark系统。
4.RDD的五个特征
- A list of partitions
一组分区(物理概念)/分片(逻辑概念) - -A function for computing each split
每个RDD都有一个函数,作用在所有分片之上 - -A list of dependencies on other RDDs
每个RDD都跟其他RDD有依赖关系, 分成两类:
窄依赖(独生):一个父分区数据只交给一个子分区--------->没有shuffle
宽依赖(超生):一个父分区数据经过shuffle后对应多个子分区---------shuffle依赖 - -Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
可选的,如果是Key-value类型的RDD,那么这个RDD可以指定一个分区器,默认的分区器,是HashPartitioner - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
an HDFS file)
假如读取的数据是来自于HDFS, split有三个副本。对于任何一个副本,都有一个优先参与计算的位置列表,三个副本的位置:hadoop02, hadoop05,hadoop04
优先位置:hadoop05, hadoop02, hadoop04
5.RDD,DataFrame,DataSet的区别
- RDD是分布式的 Java对象的集合;
- DataFrame是分布式的Row对象的集合,比RDD多了数据的结构信息,即schema。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化;
- Dataset可以认为是DataFrame的一个特例,主要区别是Dataset每一个record存储的是一个强类型值而不是一个Row
6.map和flatmap的区别
map函数会对每一条输入进行指定的操作,然后为每一条输入返回一个对象;而flatMap函数则是两个操作–先映射后扁平化:同map函数一样:对每一条输入进行指定的操作,然后为每一条输入返回一个对象,最后将所有对象合并为一个对象。
7.educeByKey、groupByKey和combineByKey、aggregateByKey的区别
•reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义;
•groupByKey也是对每个key进行操作,但只生成一个sequence,groupByKey本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。使用groupByKey时,spark会将所有的键值对进行移动,不会进行局部merge,会导致集群节点之间的开销很大,导致传输延时。
•CombineByKey是一个比较底层的算子,用法如下:
三个参数: Int => C, (C,Int) => C , (C, C) => C
每个都是在前一个参数基础上进行,例如:
val list=List((“a”,2),(“a”,3),(“b”,1),(“b”,2),(“c”,1))
var rdd= sc.parallelize(list)
val rdd1 = rdd.combineByKey( //求每个key对应的value值之和及个数
(x:Int) => (x,1) , //参数1
(a:(Int,Int),b:Int)=>(a._1+b,a._2+1), //参数2
(c:(Int,Int),d:(Int,Int))=>(c._1+d._1,c._2+d._2)) //参数3
•aggregateByKey(zeroValue)(seqOp, combOp, [numPartitions]):
其中:(zeroValue)为初始值
例:
val rdd1 = rdd.aggregateByKey(0)((a,b)=>a+b,(a,b)=>(a+b)) //求每个key对应的value的值
val rdd1 = rdd.aggregateByKey((0,0))((a,b) => 求每个key对应的value的平均值 (a._1+b,a._2+1) ,(c,d)=>(c._1+d._1,c._2+d._2))
8.spark中rdd.persist()和rdd.cache()的区别
1)RDD的cache()方法其实调用的就是persist方法,缓存策略均为MEMORY_ONLY;
2)通过persist方法可以手工设定StorageLevel来满足工程需要的存储级别;
3)cache或者persist并不是action算子。
8.spark内存不足怎么处理?
1.在不增加内存的情况下,可以通过减少每个Task的大小
2.在shuffle的使用,需要传入一个partitioner,通过设置 spark.default.parallelism参数
3.在standalone的模式下如果配置了–total-executor-cores 和 --executor-memory 这两个参数外,还需要同时配置–executor-cores或者spark.executor.cores参数,确保Executor资源分配均匀。
4.如果RDD中有大量的重复数据,或者Array中需要存大量重复数据的时候我们都可以将重复数据转化为String,能够有效的减少内存使用
9.mapreduce和spark计算框架效率区别的原因
spark是借鉴了Mapreduce,并在其基础上发展起来的,继承了其分布式计算的优点并进行了改进,spark生态更为丰富,功能更为强大,性能更加适用范围广,mapreduce更简单,稳定性好。主要区别
(1)spark把运算的中间数据存放在内存,迭代计算效率更高,mapreduce的中间结果需要落地,保存到磁盘
(2)Spark容错性高,它通过弹性分布式数据集RDD来实现高效容错,RDD是一组分布式的存储在节点内存中的只读性的数据集,这些集合是弹性的,某一部分丢失或者出错,可以通过整个数据集的计算流程的血缘关系来实现重建,mapreduce的容错只能重新计算
(3)Spark更通用,提供了transformation和action这两大类的多功能api,另外还有流式处理sparkstreaming模块、图计算等等,mapreduce只提供了map和reduce两种操作,流计算及其他的模块支持比较缺乏。
(4)Spark框架和生态更为复杂,有RDD,血缘lineage、执行时的有向无环图DAG,stage划分等,很多时候spark作业都需要根据不同业务场景的需要进行调优以达到性能要求,mapreduce框架及其生态相对较为简单,对性能的要求也相对较弱,运行较为稳定,适合长期后台运行。
10.Spark数据倾斜怎么处理?
https://tech.meituan.com/spark_tuning_pro.html
11.Spark如何和kafka对接?
1、 利用Kafka的Receiver方式进行集成:KafkaUtils.createStream
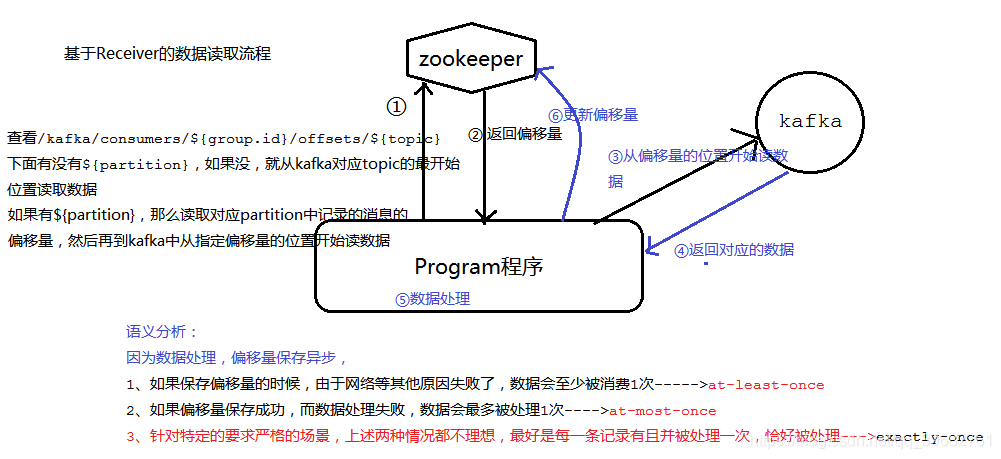
执行流程如下:
创建createStream,Receiver被调起执行
连接ZooKeeper,读取相应的Consumer、Topic配置信息等
通过consumerConnector连接到Kafka集群,收取指定topic的数据
创建KafkaMessageHandler线程池来对数据进行处理,通过ReceiverInputDStream中的方法,将数据转换成BlockRDD,供后续计算
val conf = new SparkConf().setMaster("local[*]").setAppName("StreamingKafkaReceiver")
val ssc = new StreamingContext(conf, Seconds(4))
val zkQuorum = "hdp01:2181,hap02:2181,hdp03:2181/kafka"
val groupId = "bd-1809-1"
val topics = Map(
"test1"->3 //创建新的分区,test1为name,3为分区数
)
//ReceiverInputDStream[(K, V)]-->K是kafka中消息对应的key(偏移量),V就是消息对应的value
val input:ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics)
input.flatMap{case (key, value) => {
value.split("\\s+")
}}.map((_, 1)).reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
2、 利用Kafka的Direct方式进行集成KafkaUtils.createDirectStream
执行流程如下:
实例化KafkaCluster,根据用户配置的Kafka参数,连接Kafka集群
通过Kafka API读取Topic中每个Partition最后一次读的Offset
接收成功的数据,直接转换成KafkaRDD,供后续计算
val conf = new SparkConf().setMaster("local[*]").setAppName("SparkStreamingKafkaDirect")
val ssc = new StreamingContext(conf, Seconds(4))
// auto.offset.reset -->smallest|largest
val kafkaParams = Map(
"bootstrap.servers" -> "bigdata01:9092,bigdata02:9092,bigdata03:9092",
"group.id" -> "group-1809-1",
"auto.offset.reset" -> "smallest"
)
val topics = "test1".split(",").toSet
val inputs:InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
inputs.flatMap{case (key, value) => {
value.split("\\s+")
}}.map((_, 1)).reduceByKey(_+_)
.print()
ssc.start()
ssc.awaitTermination()
3、二者区别:
1.简化的并行:在Receiver的方式中是通过创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。
2.高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复。
3.精确一次:在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录,消除了这种不一致性。
12.storm V.S. sparkStraming的优缺点
1.Storm是纯实时的,Spark Streaming是准实时的
2.Storm的事务机制、健壮性、容错性、动态调整并行度特性,都要比Spark Streaming更加的优秀
3.但是SparkStream, 有一点是Storm绝对比不上的,就是:它位于Spark生态技术中,因此Spark Streaming可以和Spark Core、Spark SQL无缝集合,也就意味这,我们可以对实时处理出来的数据,立刻进行程序中无缝的延迟批处理,交互式查询等条件操作
13.SparkStreaming V.S. Flink
Spark:底层是基于批处理设计
Flink:底层是基于流式处理思路来设计,是storm的增强版,还能做批处理


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









