







 本文深入探讨了Java并发编程的关键概念和技术,包括线程同步、锁机制、线程池、Fork/Join框架及并发容器的使用,旨在帮助开发者理解和掌握多线程编程的实践技巧。
本文深入探讨了Java并发编程的关键概念和技术,包括线程同步、锁机制、线程池、Fork/Join框架及并发容器的使用,旨在帮助开发者理解和掌握多线程编程的实践技巧。
目录
并行基础
Thread.join
若一个线程A执行了thread.join()语句,其含义为:线程A等待thread线程终止之后才从thread.join()返回。此外,我们还可以在该方法中设置等待时间。
在下面的例子中,我们设置10个线程,每个线程调用前一个线程的join()方法,即前一个线程结束了,后一个线程才返回,而线程0需要等待main线程结束。
package test2;
import J4.Interrupted;
public class JoinMain {
static class Domino implements Runnable {
private Thread thread;
public Domino(Thread thread) {
this.thread = thread;
}
@Override
public void run() {
try {
thread.join();
}catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "终止");
}
}
public static void main(String[] args) throws InterruptedException{
Thread previous = Thread.currentThread();
for(int i = 0; i < 10; i++) {
Thread thread = new Thread(new Domino(previous), "thread-" + String.valueOf(i));
thread.start();
previous = thread;
}
System.out.println(Thread.currentThread().getName() + "终止");
}
}
管道输入/输出流
管道输入/输出流主要用于线程之间的传输,传输的媒介为内存。它们主要通过:PipedWriter,PipedReader,PipedInputStream,PipedOutputStream。
下面我们来建立main线程(写内容)和自定义线程printThread(读内容)之间通信:
package J4;
import java.io.*;
public class Piped {
public static void main(String[] args) throws Exception{
PipedWriter writer = new PipedWriter();
PipedReader reader = new PipedReader();
//输出流和输入流需要进行连接,否则会抛出异常
writer.connect(reader);
Thread print = new Thread(new printThread(reader));
print.start();
int content = 0;
try {
while ((content = System.in.read()) != -1) {
writer.write(content);
}
}catch (IOException e) {
e.printStackTrace();
}finally {
writer.close();
}
}
static class printThread implements Runnable {
private PipedReader reader;
public printThread(PipedReader reader) {
this.reader = reader;
}
@Override
public void run() {
int content = 0;
try {
while ((content = reader.read()) != -1) {
System.out.print((char)content);
}
}catch (IOException e) {
e.printStackTrace();
}
}
}
}
重入锁
重入锁可以完全替代关键字synchronized,下面是一个简单的案例
package text3;
import java.util.concurrent.locks.ReentrantLock;
public class ReenterLock extends Thread{
public static ReentrantLock lock = new ReentrantLock();
public static int i = 0;
@Override
public void run() {
for(int j = 0; j < 100000; j++) {
lock.lock();
try {
i++;
}finally {
lock.unlock();
}
}
}
public static void main(String[] args) throws InterruptedException{
Thread t1 = new ReenterLock();
Thread t2 = new ReenterLock();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
与synchronized相比,我们必须手动指定何时加锁,何时释放锁。一个线程可以连续多次获得同一把锁,但释放时也要相同的次数。重入锁提供了一些高级的功能
中断响应
对于关键字synchronized来说,若一个线程在等待锁,那么它的结果只有两个:要么它获得锁继续执行,要么它继续保持等待。
对于使用重入锁的程序,它可以根据需要来取消的锁的请求。下面给出一个案例
package text3;
import java.util.concurrent.locks.ReentrantLock;
/*
t1线程占用lock1锁,再试图占用lock2锁.
t2线程占用lock2锁,再试图占用lock1锁,
两者处于死锁
t2线程执行中断方法,放弃对lock1锁的请求,同时释放lock2锁。
t1线程获得lock2锁从而继续执行
*/
public class IntLock extends Thread{
private static ReentrantLock lock1 = new ReentrantLock();
private static ReentrantLock lock2 = new ReentrantLock();
private static int lockFlag;
public IntLock(int lockFlag) {
this.lockFlag = lockFlag;
}
@Override
public void run() {
try {
if(lockFlag == 1) {
lock1.lockInterruptibly();
try {
Thread.sleep(500);
}catch (InterruptedException e) {}
lock2.lockInterruptibly();
}else {
lock2.lockInterruptibly();
try {
Thread.sleep(500);
}catch (InterruptedException e) {}
lock1.lockInterruptibly();
}
}catch (InterruptedException e) {
e.printStackTrace();
}finally {
if(lock1.isHeldByCurrentThread()) {
lock1.unlock();
}
if(lock2.isHeldByCurrentThread()) {
lock2.unlock();
}
System.out.println(Thread.currentThread().getName() + "退出");
}
}
public static void main(String[] args) throws InterruptedException{
Thread t1 = new IntLock(1);
t1.setName("t1");
Thread t2 = new IntLock(2);
t2.setName("t2");
t1.start();
t2.start();
Thread.sleep(1000);
t2.interrupt();
}
}
线程t1占用锁lock1后,尝试去占用锁lock2。线程t2占用锁lock2后,尝试占用锁lock1。此时形成两个线程相互等待对方释放锁的场面。在这个程序中,对锁的请求我们用lockInterruptibly()方法,这是一个可以响应中断的方法。我们中断线程t2,它会放弃对锁lock1的请求并释放它持有的锁lock2。线程t1得到锁lock2后得以继续执行下去。
输出结果为:
t1退出
t2退出
限时等待对锁的请求
限时等待是避免死锁的方法之一,我们可以使用tryLock()方法实现。下面给出一个案例:
package text3;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
/*
在一个线程(t1或t2)占用到锁lock后,休眠6秒。
另一个线程(t1或t2)尝试获取锁lock(最多等5秒),5秒后输出语句。
*/
public class TimeLock extends Thread{
private static ReentrantLock lock = new ReentrantLock();
@Override
public void run() {
try {
if(lock.tryLock(5, TimeUnit.SECONDS)) {
System.out.println(currentThread().getName());
Thread.sleep(6000);
}else {
System.out.println(currentThread().getName() + " 未获取锁");
}
}catch (InterruptedException e) {
e.printStackTrace();
}finally {
if(lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
public static void main(String[] args) {
Thread t1 = new TimeLock();
t1.setName("t1");
Thread t2 = new TimeLock();
t2.setName("t2");
t1.start();
t2.start();
}
}
线程(t1或t2)申请到锁成功后,休眠6秒(占用着锁),另一个线程(t1或t2)尝试去申请锁(限时等待5秒),5秒后输出获取失败语句。
当tryLock()方法不带参数时,若线程获取锁失败,则线程不会等待,并返回false。
公平锁
大多数情况下,锁的申请都是非公平的,也就是说,若两个线程t1,t2先后申请锁A,当锁A可用时,系统只会从锁A的等待队列中随机挑选一个。而公平锁则会按照申请时间的先后顺序处理。关键字synchronized产生的所控制是所公平的,而重入锁允许我们对公平性进行设置。如下所示
ReentrantLock lock = new ReentrantLock(true);
值得注意的是,实现公平锁要求系统维护一个有序队列,因此公平锁的实现成本较高,若无特别的需求,不需要使用公平锁。
重入锁的搭档:Condition
Condition对象的await()方法和signal()方法与Object对象的wait()方法和notify()方法的作用大致相同。类似的,wait()方法和notify()方法要与关键字synchronized合作使用,而Condition是与重入相关联的,通过ReentrantLock对象的newCondition()方法,可以生成一个与该重入锁绑定的Condition对象。下面演示Condition的功能
package text3;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
/*
当线程t1使用condition.await()方法时,要求t1持有相关的重入锁lock。
在该方法调用完后,t1释放该锁。
同理, condition.signal()方法调用时,也要求线程先获得锁,故在主线程里调用lock.lock()方法,在signal方法调用后,唤醒condition
里等待队列中的一个线程,线程被唤醒后,尝试获取与之绑定的重入锁,故主线程需要释放锁。一旦成功获取即可继续执行
*/
public class ReenterLockCondition implements Runnable{
private static ReentrantLock lock = new ReentrantLock();
private static Condition condition = lock.newCondition();
private static ReentrantLock tmp = new ReentrantLock();
@Override
public void run() {
try {
lock.lock();
condition.await();
System.out.println(Thread.currentThread().getName() + " is await");
}catch (InterruptedException e) {
e.printStackTrace();
}finally {
System.out.println(Thread.currentThread().getName() + "成功获取锁");
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException{
ReenterLockCondition paramter = new ReenterLockCondition();
Thread t1 = new Thread(paramter);
t1.setName("t1");
t1.start();
Thread.sleep(2000);
lock.lock();
System.out.println(t1.getName() + Thread.holdsLock(t1));
System.out.println(Thread.currentThread().getName() + "是否持有该锁: " + Thread.holdsLock(Thread.currentThread()));
condition.signal();
lock.unlock();
}
}
当线程t1使用condition.await()方法时,要求t1持有与之绑定的重入锁lock。 在该方法调用完后,t1释放该锁。 同理, condition.signal()方法调用时,也要求当前线程先获得锁,故在主线程里调用lock.lock()方法,在signal方法调用后,唤醒condition里等待队列中的一个线程,线程t1被唤醒后,尝试获取先前与之绑定的重入锁,故主线程需要释放锁。一旦线程t1成功获取后即可继续执行
下面用Condition的await()方法和signal()方法实现一个阻塞队列。
package text3;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class myThreadQueue {
private ReentrantLock lock = new ReentrantLock();
private Condition notEmpty = lock.newCondition(); // 队列为空时,消费者线程进入该Condition的等待队列
private Condition notFull = lock.newCondition(); // 队列已满时,生产者线程进入该Condition的等待队列
private LinkedList<String> stringList = new LinkedList<>();
private int listMaxSize = 5;
public void put(String value){
try {
lock.lock();
System.out.println("准备放入队列");
while (stringList.size() == listMaxSize) {
System.out.println("队列已满,不可放");
notFull.await();
}
stringList.add(value);
System.out.println("放入队列:" + value);
notEmpty.signal();
}catch (InterruptedException e) {
notFull.signal();
e.printStackTrace();
}finally {
lock.unlock();
}
}
public String take() {
String returnValue = "";
try {
lock.lock();
System.out.println("准备从队列取出");
while (stringList.size() == 0) {
System.out.println("队列为空,不可取");
notEmpty.await();
}
System.out.println("从队列中取出:" + (returnValue = stringList.remove()) + "当前队列容量:" + stringList.size());
}catch (InterruptedException e) {
notEmpty.signal();
e.printStackTrace();
}finally {
lock.unlock();
return returnValue;
}
}
public static void main(String[] args) throws InterruptedException{
myThreadQueue queue = new myThreadQueue();
queue.put("1");
queue.put("2");
queue.put("3");
queue.put("4");
queue.put("5");
Thread consumer = new Thread(new Runnable() {
@Override
public void run() {
queue.put("6");
queue.put("7");
queue.put("8");
}
});
Thread producter = new Thread(new Runnable() {
@Override
public void run() {
queue.take();
queue.take();
queue.take();
}
});
producter.start();
consumer.start();
producter.join();
consumer.join();
}
}
允许多个线程同时访问:信号量Semaphore
无论是内部锁synchronized还是重入锁ReentrantLock,一次只允许一个线程访问一个资源。而信号量Semaphore可以指定一定数量的线程同时访问一个资源。下面给出它的构造函数和一些相关方法:
public Semaphore(int permits, boolean fair)) // permits为同时可以有多少个线程访问,fair指定是否公平 public void acquire() // 当前线程尝试获得许可,若无法获得则等待 public void release() // 当前线程释放持有的许可
下面给出例子:
package text3;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
public class SemapDemo implements Runnable{
private final Semaphore semp = new Semaphore(5);
@Override
public void run() {
try {
semp.acquire();
Thread.sleep(2000);
System.out.println(Thread.currentThread().getName() + "完成");
}catch (InterruptedException e) {
e.printStackTrace();
}finally {
semp.release();
}
}
public static void main(String[] args) {
ExecutorService exec = Executors.newFixedThreadPool(20);
SemapDemo demo = new SemapDemo();
for(int i = 0; i < 20; i++) {
exec.execute(demo);
}
}
}
在本例中,指定可以同时有5个线程同时访问一个代码块,并开启20个线程。观察下面的输出,可以发现5个线程为一组,依次输出语句。
可能的输出为:
pool-1-thread-1完成
pool-1-thread-4完成
pool-1-thread-2完成
pool-1-thread-5完成
pool-1-thread-3完成
pool-1-thread-10完成
pool-1-thread-7完成
pool-1-thread-6完成
pool-1-thread-8完成
pool-1-thread-9完成
pool-1-thread-13完成
pool-1-thread-12完成
pool-1-thread-14完成
pool-1-thread-11完成
pool-1-thread-15完成
pool-1-thread-20完成
pool-1-thread-19完成
pool-1-thread-16完成
pool-1-thread-17完成
pool-1-thread-18完成
倒计数器:CountDownLatch
该类可以控制某一线程等待,直到在指定数量个线程执行完后才可继续执行。该类的构造函数如下:
public CountDownLatch(int count) //count为指定的计数线程的数量
下面演示CountDownLatch的用法:
package text3;
import java.util.Random;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/*
CountDownLatch对象的计数量为10,表明需要10个线程执行完任务后,等待在CountDownLatch对象的线程才可继续执行
*/
public class CountDownLatchDemo implements Runnable{
private static final CountDownLatch end = new CountDownLatch(10);
@Override
public void run() {
try {
Thread.sleep(new Random().nextInt(10) * 1000);
System.out.println("check complete");
end.countDown();
}catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws InterruptedException{
CountDownLatchDemo demo = new CountDownLatchDemo();
ExecutorService exec = Executors.newFixedThreadPool(10);
for(int i = 0; i < 10; i++) {
exec.submit(demo);
}
end.await(); // 要求当前线程(主线程)在等待10个线程执行完后才可继续执行
System.out.println("ooooooooook");
exec.shutdown();
}
}
线程池
为了避免系统频繁创建线程,我们可以让创建的线程复用。在线程池中,总有那么几个活跃线程,当我们需要使用线程时,可以从池子中取出一个空闲线程。当完成工作后,将该线程退回到线程池中。
为了更好地控制多线程,JDK提供了Executor框架,它的核心成员如下所示:

以上成员均在java.util.concurrent包中,其中,ThreadPoolExecutor表示一个线程池,Executors类则表示线程池工厂。通过Executors可以获得有特定功能的线程池,如下所示:
newFixedThreadPool():该方法返回一个固定线程数量(线程数量始终不变)的线程池。当有一个新任务提交时,若线程池有空闲线程,则立即执行。若没有,则新任务会暂存到一个任务队列中,直至有空闲线程。固定大小的线程池
下面以newFixedThreadPool()方法为例:
package text3;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolDemo {
public static class myTask implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis() + ": " + Thread.currentThread().getId());
try {
Thread.sleep(1000);
}catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
myTask task = new myTask();
ExecutorService es = Executors.newFixedThreadPool(5);
for(int i = 0; i < 10; i++) {
es.submit(task);
}
}
}
在此段代码我们创建了5个线程的线程池,依次向线程池提交10和任务。每个任务会将自己的执行时间和执行线程的id打印,并休眠1秒。下面是可能的输出:
1566264203248: 12
1566264203248: 14
1566264203248: 13
1566264203248: 11
1566264203248: 15
1566264204250: 15
1566264204250: 11
1566264204266: 13
1566264204266: 14
1566264204266: 12前5个任务和后5个任务的执行时间之间相差1秒,且前5个任务的线程id和后5个任务的执行线程id完全一致,即这10个任务是分成两批执行的。
计划任务
newScheduledThreadPool()方法,它返回ScheduledExecutorService对象,它可以在指定的时间内对执行任务。schedule():在给定时间内进行一次任务调度。
scheduleAtFixedRate():对任务进行周期性执行,两个任务之间的时间间隔是以上一个任务开始执行为起点,在之后的Period时间后执行下一个任务。
scheduleWithFixedDelay():对任务进行周期性执行,两个任务之间的时间间隔是以上一个任务结束执行为起点,在之后的Period时间后执行下一个任务。
下面示范scheduleAtFixedRate用法(每隔2秒执行一次任务,任务执行1秒):
package text3;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ScheduledExecutorDemo {
public static void main(String[] args) {
ScheduledExecutorService service = Executors.newScheduledThreadPool(10);
service.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
System.out.println(System.currentTimeMillis() / 1000);
}catch (InterruptedException e ) {
e.printStackTrace();
}
}
}, 0, 2, TimeUnit.SECONDS);
}
}
可能的输出:
1566265468
1566265470
1566265472
1566265474
1566265476
1566265478
1566265480
1566265482
1566265484可以看到每个任务的时间间隔相差2秒
如果任务执行时间超过了每个任务相隔的时间会怎么样?我们修改一下上面的Thread.sleep():
package text3;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ScheduledExecutorDemo {
public static void main(String[] args) {
ScheduledExecutorService service = Executors.newScheduledThreadPool(10);
service.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(8000);
System.out.println(System.currentTimeMillis() / 1000);
}catch (InterruptedException e ) {
e.printStackTrace();
}
}
}, 0, 2, TimeUnit.SECONDS);
}
}
可能出现的结果:
1566265852
1566265860
1566265868
1566265876
1566265884
1566265892
1566265900
1566265908我们发现每个任务的执行时间间隔变成了8秒,也就是说,在上一个任务执行8秒后,下一个任务会被立即调用。
对于scheduleWithFixedDelay()方法,如果同样是任务执行8秒,任务执行间隔为2秒,则会发现任务的实际间隔为10秒
核心线程池的内部实现
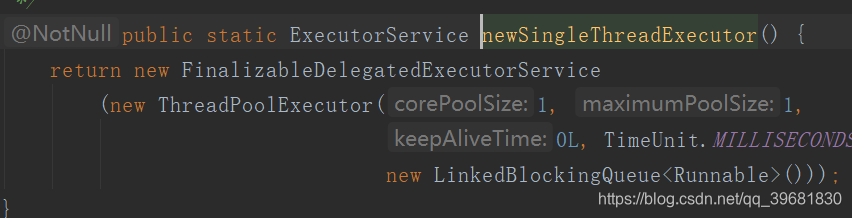
对于核心的几个线程池,无论是newFixedThreadPool()方法,newSingleThreadExecutor()方法,还是newCachedThreadPool()方法,它们的内部均使用了ThreadPoolExecutor类。下面是是ThreadPoolExecutor的一个重要构造函数:

参数的含义如下:

下面以new FixedThreadPool()方法,new SingleThreadExecutor()方法,和new CachedThreadPool()方法里调用的ThreadPoolExecutor的构造方法来说明其方法里的参数workQueue(任务队列)和handler(拒绝策略)。
workQueue(任务队列)
workQueue是BlockingQueue接口的对象,可以使用不同的BlockingQueue接口的实现类:
LinkedBlockingQueue(无界任务队列): 当有新任务来时,若系统的线程数小于corePoolSize,线程池会生成新的线程执行任务,但若系统的线程数到达corePoolSize时则不会生成新线程,若后续仍有新任务加入且没有空闲线程,则任务进入队列等待。
这里new FixedThreadPool()方法,new SingleThreadExecutor()方法的workQueue参数使用了LinkedBlockingQueue

SynchronousQueue(直接提交的队列);该队列没有容量,每一个插入线程执行完put后都会阻塞以等待消耗线程的操作
ArrayBlockingQueue:它的构造函数必须带一个容量参数,表示队列的最大容量。当使用该队列时,如果有新的任务执行且线程池的实际线程数小于corePoolSize,则会优先创建新线程,若大于则将任务加入等待队列。若等待队列已满,则在总线程数不大于maxiumPoolSize前提下创建新的进程执行任务。若大于maxiumPoolSize,则执行拒绝策略。
PriorityBlockingQueue:它可以控制任务的执行顺序。之前的ArrayBlockingQueue和LinkedBlockingQueue都是先进先出,而PriorityBlockingQueue可以根据任务自身的优先级顺序先后执行。
下面是ThreadPoolExecutor的execute方法
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
/*
workerCountOf()方法获取当前线程池的线程总数
1.若其值小于corePoolSize,则执行任务
2.否则在offer()方法中进入等待队列,若进入等待队列失败(有界队列容量已达上限或使用了SynchronousQueue类),则将任务提交给线程池。
3.若当前线程数已达maximumPoolSize,则提交失败,执行拒绝策略。
*/
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}handler(拒绝策略)
拒绝策略通常是由于线程池的线程用完且等待队列已满而去使用。JDK内置的四种拒绝策略:

AbortPolicy策略:直接抛出异常,阻止系统正常工作。
CallerRunsPolicy策略:只要线程池未关闭,则该策略直接在调用线程中运行当前被丢弃的任务。
DiscardOldestPolicy策略:该策略丢弃即将被执行的一个任务,并尝试再次提交该任务。
DiscardPolicy策略:该策略丢去无法处理的策略,不做任何处理。
若以上策略无法满足实际需求,可以自己扩展RejectedExecutionHandler接口,该接口定义如下所示:

其中r为执行的任务,executor为当前线程池。
下面自己定义线程池和拒绝策略:
package text3;
import java.util.concurrent.*;
public class RejectThreadPoolDemo {
public static class myTask implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis() + ": " + Thread.currentThread().getId());
try {
Thread.sleep(100);
}catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException{
myTask task = new myTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.SECONDS,
new LinkedBlockingDeque<>(10), Executors.defaultThreadFactory(),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println(r.toString() + "被拒绝");
}
});
for(int i = 0; i < Integer.MAX_VALUE; i++) {
es.submit(task);
Thread.sleep(10);
}
}
}
这里我们自定义的线程池有5个常驻线程且最大线程数为5。为防止任务量过大而导致进入的等待队列将内存撑爆,我们也给出了等待队列的大小。并在拒绝策略中输出丢弃的信息。
自定义线程池中的线程
线程池的主要作用是防止线程的频繁创建,而最开始的线程则是由ThreadFactory创建而来。
ThreadFactory是一个接口。它只有一个用来创建线程的方法:
Thread newThread(Runnable r);
当线程池需要创建线程时,就会调用这个方法。
下面我们自定义ThreadFactory,里面的线程会输出创建语句并被设置为守护线程。当主线程执行完后,线程池会被强制销毁
package text3;
import java.util.concurrent.*;
public class ThreadFactoryDemo {
public static class myTask implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis() + ": " + Thread.currentThread().getId());
try {
Thread.sleep(100);
}catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException{
myTask task = new myTask();
ExecutorService es = new ThreadPoolExecutor(5, 5,
0L, TimeUnit.MICROSECONDS,
new SynchronousQueue<Runnable>(),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setDaemon(true);
System.out.println("创建了线程" + thread);
return thread;
}
});
for(int i = 0; i < 5; i++) {
es.submit(task);
}
Thread.sleep(2000);
}
}
扩展线程池
ThreadPoolExecutor是一个可以扩展的线程池,它提供了beforeExecute()方法和afterExecute()两个空方法以及terminated()方法来实现对线程池的控制。在实际应用中,可以对两个空方法扩展来实现对线程池运行状态的跟踪。
下面我们演示对线程池的扩展:
package text3;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ExtThreadPool {
public static class myTask implements Runnable {
public String name;
public myTask(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(System.currentTimeMillis() + ": " + Thread.currentThread().getId()
+ "name: " + name);
try {
Thread.sleep(100);
}catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException{
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingDeque<Runnable>()) {
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("准备执行:" + ((myTask)r).name);
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("执行完成:" + ((myTask)r).name);
}
@Override
protected void terminated() {
System.out.println("线程退出" );
}
};
for(int i = 0; i < 5; i++) {
myTask myTask = new myTask("task-" + i);
es.execute(myTask);
Thread.sleep(100);
}
es.shutdown();
}
}
我们在三个方法中都记录了任务的开始,完成以及线程的退出。在任务提交完成后,调用shutdown()方法关闭线程池。若当前正有线程在执行,shutdown()方法不会立即暴力终止所有任务,而是会等待所有任务执行完后再关闭线程池,但它不会等待所有线程执行完后再返回。shutdown()方法执行完后该线程池不能再接收其它新任务。
分而治之:Fork/Join框架
Fork一词的原始含义为分支,使用fork()方法使得系统可以多一个执行分支(线程)。join()方法表示等待,即等待fork()方法后多出的线程执行完毕。JDK给出了一个ForkJoinPool线程池,在这里开启线程的任务不是由fork()方法完成,而是提交给ForkJoinPool线程池处理,以防fork()方法开启过多线程导致影响性能。在该线程池中,大多数情况下一个线程是需要处理多个任务的,因此一个线程都拥有一个任务队列,在这种情况下,可能会出现:线程A处理完自己的任务,而线程B还有一堆任务需要处理,此时,线程A就会帮助线程B,从B的任务队列底部开始获取数据,而线程B执行自己的任务时,从顶部获取数据。
我们可以向ForkJoinPool线程池提交一个ForkJoinTask任务,该任务支持fork()方法(分解任务)以及join()方法(等待任务)。ForkJoinTask任务有两个子类:RecursiveTask类(可携带返回值的任务)和RecursiveAction类(没有返回值的任务)。
下面我们用RecursiveTask类计算数列的求和
package text3;
import java.util.ArrayList;
import java.util.concurrent.*;
public class CountTask extends RecursiveTask<Long> {
private long start;
private long end;
private static final int Max = 1000;
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
public Long compute() {
long sum = 0;
boolean canCompute = (end - start) < Max;
if(canCompute) {
// System.out.println("start: " + start + " end: " + end);
for(long i = start; i <= end; i++) {
sum += i;
}
}else {
// 分成100个任务
long step = (start + end) / 100;
ArrayList<CountTask> taskList = new ArrayList<>();
long index = start;
for(int i = 0; i < 100; i++) {
long lastOne = index + step;
// 计算index到lastOne数列的任务
CountTask countTask = new CountTask(index, lastOne);
index += step + 1;
taskList.add(countTask);
// 提交任务
countTask.fork();
}
for(CountTask task : taskList) {
// 等待任务返回结果
sum += task.join();
}
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask task = new CountTask(0, 20000L);
ForkJoinTask<Long> result = forkJoinPool.submit(task);
try {
System.out.println("sum= " + result.get());
}catch (InterruptedException e) {
e.printStackTrace();
}catch (ExecutionException e) {
e.printStackTrace();
}
}
}
在该程序中,一个任务最能只能计算大小为1000的数列,若大于则将任务分解为100个子任务。
JDK的并发容器
线程安全的HashMap
HashMap不是线程安全的,下面我们来看一个例子:
package test2;
import java.util.HashMap;
import java.util.concurrent.ConcurrentHashMap;
public class HashMapMultiThread {
static HashMap<String, String> hashMap = new HashMap<>();
public static class AddThread extends Thread {
private int start;
public AddThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i = start; i < 100000; i+= 2) {
hashMap.put(Integer.toString(i), Integer.toString(i));
}
}
}
public static void main(String[] args) throws InterruptedException{
Thread t1 = new AddThread(0);
Thread t2 = new AddThread(1);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(hashMap.size());
}
}
线程t1负责将0到100000中的偶数(包括0)放入map,线程t2则将其奇数放入map中。我们期望的map大小应该是100000,然而结果会出现小于100000的情况。
若我们需要一个线程安全的HashMap,我们可以使用ConcurrentHashMap类或者使用Collections.synchronizedMap()方法包装HashMap。对于上例,我们可以改成这两种:
static Map hashMap = Collections.synchronizedMap(new HashMap<>());
// static ConcurrentHashMap<String, String> hashMap = new ConcurrentHashMap<>();
List的线程安全
在Java中,ArrayList和LinkedList不是线程安全的,而Vector是线程安全的。除此之外,我们还可以用Collections.synchronizedList包装任意的List。例如:
static List<String> list = Collections.synchronizedList(new LinkedList<>());


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









