






1、内核源码树和ZImage需是保持一样的。ZImage是压缩版的linux镜像文件,各Image的区别为:【Linux】Image、zImage与uImage的区别-优快云博客
2、so:动态链接库。ko:kernel obj内核文件,驱动的注册卸载操作就是对ko的操作。lsmod(查看已安装的模块)、insmod(安装模块)、rmmod(卸载模块)。
modinfo a.ko,中重要的点:depends:依赖项。 vermagic:版本特征。
我对模块的理解:模块其实也是一堆动态链接库,把一堆文件打包起来,编译一个.ko的可执行文件。这个.ko文件可能对独立的,也可能是与其他模块有耦合关系的。最底层的实现就是模块的注册和卸载分别关联不同的函数,不同的函数去执行不同的功能。模块就是函数。
关于模块的注册等有没有其他的更好的实现方式呢?
暂时没想到,模块即函数,函数编写完成后打包成某格式的文件,随后将文件copy到Linux系统中,但Linux系统为什么使用insmod或rmmod的形式呢?因这属于kernel的二进制文件,直接复制到某路径下不足以加载他们,insmod实现原理为会读取指定的.ko文件并解析其内容,.ko文件包括模块的元数据和实际代码,元数据中包括模块的符号表、依赖关系、许可证等。
3、module_init():注册,注册完毕后函数就没啥用了; module_exit():卸载
MODULE_ LICENSE("GPL"); // 描述模块许可证**十分重要**
MODULE_AUTHOR("作者"); // 添加作者
__init,内核启动时统一加载.init.text中的函数,然后释放掉这块区间。目的是为了节省内存。类似于.so文件,加载一次后就一直存在内存中,此时原副本就可以不存在了。
4、makefile类似于一个shell脚本,但与shell脚本有明显不同,依靠Linux中的make工具实现内部指令的解释,格式为目标、依赖、命令。
定义一个新目标:随后直接make cp即可实现后续命令
makefile理解:makefile就是个脚本语言,变量赋值后即定义。可以把KERN_DIR替换成其他的变量,例如KERN_DIR123。

将各linux命令以目标(自定义)形式形成的一个组合。除自定义外,还又包含了一些makefile的特性字段来标识不同的含义,如下:
makefile的特殊变量,类似$@, $+等 (copied)_makefile特殊变量-优快云博客
makefile名字可以任意指定,不一定非得是Makefile/makefile,也可以是build.mk,区别就是当指定为Makefile时,默认make可以索引到这个文件,当指定为其他文件时,需要加入-f进行索引。当然,后缀也不一定是.mk。
make -f build.mk脚本有很多例如shell脚本、Python脚本、JavaScript脚本、PHP脚本,不同脚本使用的脚本语言不通,因为其对应的解析器不同。
Makefile可以被认为是一种特殊的脚本文件,但它与传统意义上的脚本有一些不同。Makefile是用于自动化构建过程,特别是用于编译程序的一种配置文件。
以下是Makefile作为一种脚本的特点:
特殊的格式:Makefile有自己特定的格式和语法规则,它由一系列的规则组成,这些规则定义了文件之间的依赖关系以及如何构建这些文件。
构建指令:Makefile中的规则包含构建指令,这些指令通常是用来编译源代码文件、链接程序或执行其他构建相关的任务。
自动化:Makefile使得构建过程自动化。一旦定义了规则,用户可以通过简单的命令(通常是
make命令)来自动化地构建整个项目,而不需要手动执行每个步骤。依赖管理:Makefile管理文件之间的依赖关系,只有当依赖的文件发生变化时,相关的目标文件才会重新编译。
执行环境:Makefile通常在命令行环境中执行,它依赖于
make工具来解析和执行Makefile中的指令。与传统脚本(如Shell脚本、Python脚本等)相比,Makefile的不同之处在于:
非交互式:Makefile通常不是交互式的;它不提供交互式命令行接口,而是根据定义好的规则自动执行。
构建特定:Makefile专为软件构建过程设计,而不是用于通用编程任务。
无编程语言特性:Makefile没有提供传统编程语言的特性,如控制流语句(if-else、for循环等),尽管它有一些内置的函数和变量。
总的来说,虽然Makefile可以被视为一种脚本,但它更准确地说是一个构建脚本或构建配置文件,专门用于自动化和管理软件项目的构建过程。
5、Linux中一切皆文件,对驱动的操作其实就是对open、write、read的操作。
驱动千千万,Linux这边首先需要解决是归一化,其解决办法就是建立一个函数指针的结构体,类似于一个逻辑控制块,每个驱动都包含,也类似于FreeRTOS中的任务控制块。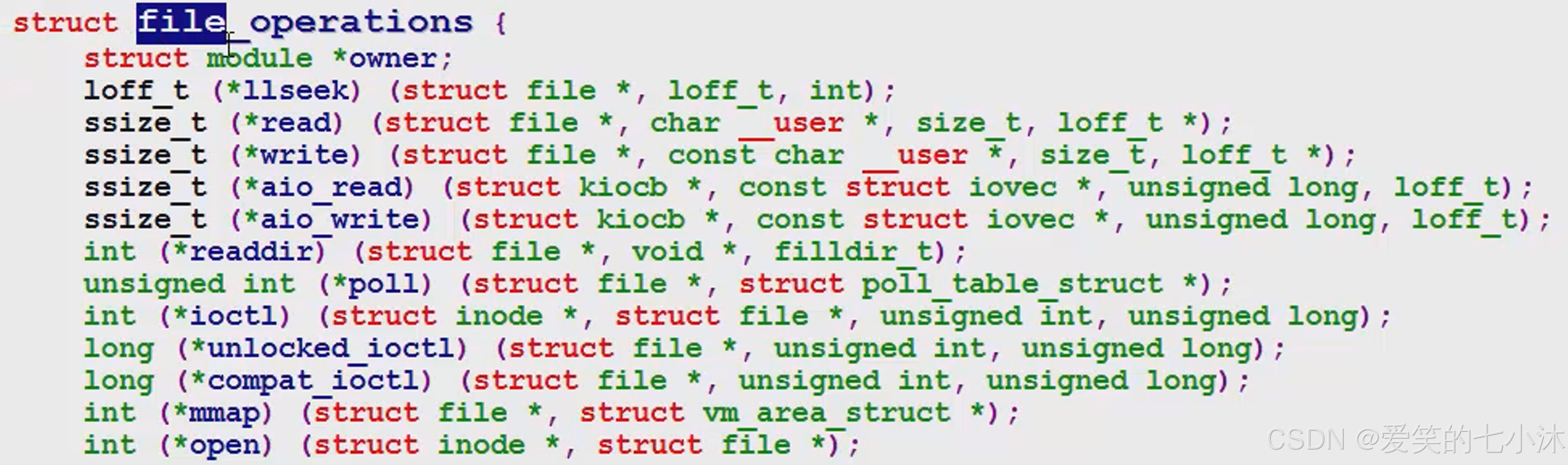
用C++形式表示,这就是个母类,声明了一堆虚函数,不同的驱动表示不同的子类。每个驱动都是一个单例模式对象,这个驱动要通过注册函数register_chrdev注册给Linux,然后Linux才知道有这个东西了,猜测内核这边应该是有个链表,注册成功后可以直接使用内核函数进行索引。
6、Linux的驱动注册函数:
inline关键字:.h文件可以声明,也可以定义,但是一般不作定义,因为一个.h文件可能会被多个.c文件包含,但变量/函数的声明只能有一个,所以加入inline处理,直接加载到调用处。inline的函数一般都不是很大,不然代码的体积会增加。

Linux中字符设备驱动个数最大255个。注册完毕后在代码中的位置。
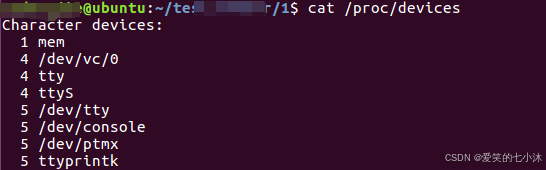
驱动在代码中的位置:
cat /proc/devices
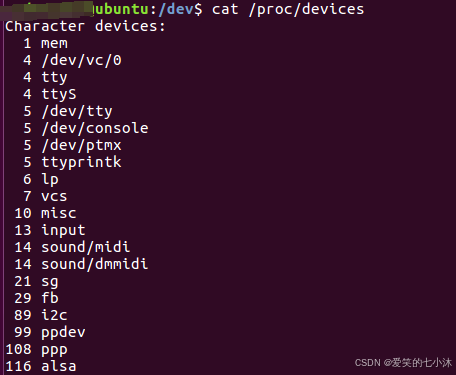
为什么有驱动后还单独搞个设备文件出来呢?
首先Linux中一切皆文件,操作驱动就是操作文件,其次驱动数最大255个主设备号,但同类型设别可能有多个,故增设从设备号,主+从映射为一个独立的文件。
注册驱动调用顺序:
insmod->module_init(chrdev_init)->register_chrdev(主设备号,驱动名字符串,驱动块结构体)->file_operations.open/release // 建议自动分配主设备号
应用层API调用流程:
open()->底层file_operations.open()
7、
应用层与底层驱动之间通过设备号进行通信,设备号十分重要!!设备号分为主设备号和次设备号,主设备号标识种类,次设备号标识是第几个设备。
linux中一切皆文件,驱动设备文件也是一样,驱动中设备文件所在位置为/dev下,设备文件由主次设备号唯一生成。设备文件分为字符设备和块设备。
mknod <设备文件名> <设备类型> <主设备号> <从设备号>
mknod /dev/my_char_device c 240 0驱动操作示例:
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd = open("/dev/my_char_device", O_RDONLY);
if (fd < 0) {
perror("Failed to open device");
return 1;
}
char buffer[256];
ssize_t bytes_read = read(fd, buffer, sizeof(buffer));
if (bytes_read < 0) {
perror("Failed to read device");
close(fd);
return 1;
}
printf("Read %zd bytes:s\n", bytes_read, buffer);
close(fd);
return 0;
}8、
kernel和用户在内存中是两个空间,直接使用memcpy复制会报错,因为memcpy是一个用户控件函数。
在 Linux 内核编程中,将用户空间的数据复制到内核空间通常不直接使用
memcpy函数。memcpy是一个用户空间函数,用于在用户空间内复制内存内容,它不知道内核空间和用户空间之间的权限边界。而且直接用memcpy及易踩内存。由于内核空间和用户空间是隔离的,直接在内核空间使用
memcpy来操作用户空间的数据可能会导致未定义行为,甚至系统崩溃。相反,Linux 内核提供了一系列专门的函数来处理空间和内核空间之间的数据传递,这些函数会进行必要的权限检查和错误处理。
- copy_to_user():完成内核空间到用户空间的复制
- copy_from_user():完成用户空间到内核空间的复制
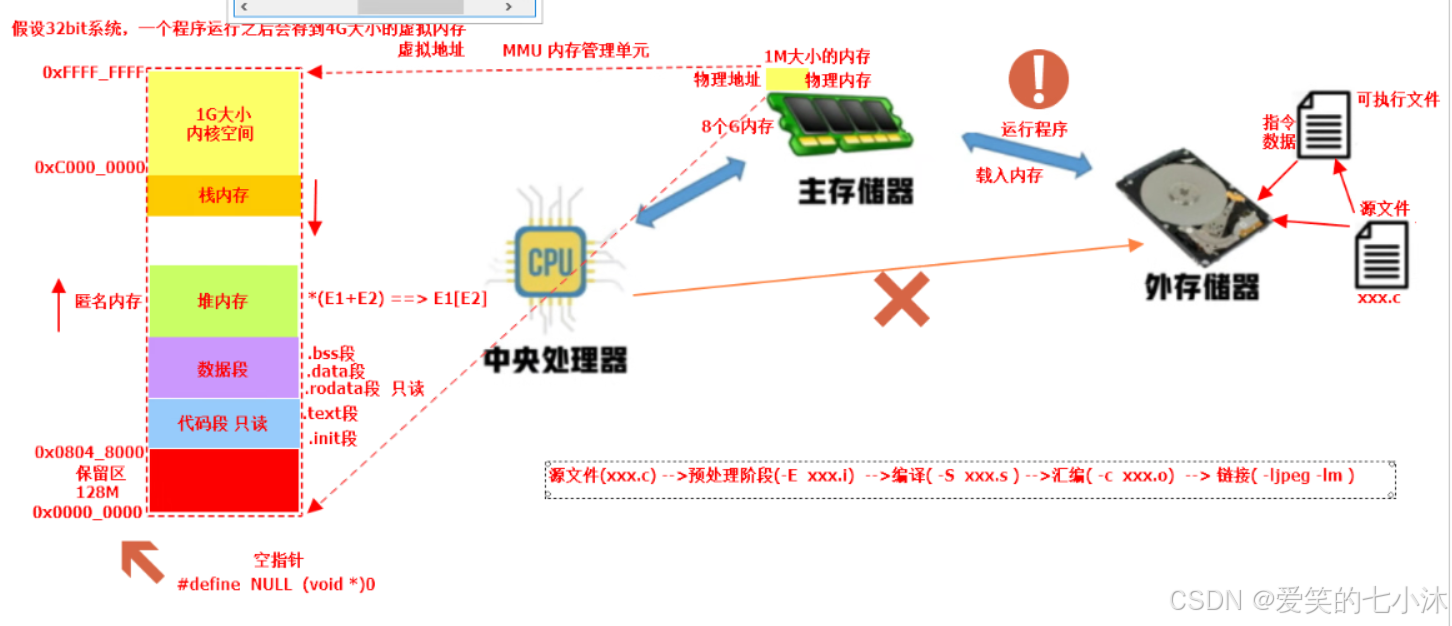
9、MMU开了后所有的都是虚拟地址。
实际工作中使用静态还是动态:移植代码时跟随源代码,源代码静态则静态,源代码动态则动态。
内核都是运行在虚拟内存空间中,这样可以隔绝用户代码控制,防止被误操作。
内核空间的代码就是给自己使用的,对外(用户)需要做隔离,对内的硬件地址做映射。
只要把内核代码down下来了,针对此部分的代码操作的内存地址都是在内核区的。
****对于不知道怎么使用的内核库函数,直接查看内核中其他位置的如何使用的,以求更快速完成代码编写****
在内核中为何需要把外设地址映射一个不一样的地址??
因为外设的地址本质上是给Linux应用/裸机这类用户区使用的,内核地址是独立于用户区存在的,因此对外设的物理地址需要映射成内核地址使用。
为什么需要静态映射表:
1、对外访问方便:静态映射表将硬件设备的物理地址映射到内核的虚拟地址空间,使得内核可以直接通过虚拟地址访问外设资源,而不必关心其出厂时设计的物理地址。
2、创造平台无关的静态映射表,更换硬件平台时,静态映射表可以通过硬编码的方式将硬件资源的物理地址映射到虚拟内存中。
#include <linux/io.h>
#define PHYSICAL_ADDR 0x10000000
#define VIRTUAL_ADDR 0xf0000000
#define MappedSize 0x1000
void *mapped_base;
mapped_base = ioremap(PHYSICAL_ADDR, MappedSize, IOREMAP_NOCACHE); // 静态映射函数
if (!mapped_base) {
// 处理映射失败
}#define S5P_PA_GPIO S5P6440_PA_GPIO // 宏中包含PA表示物理地址
#define S5P_VA_GPIO S3C_ADDR(0x00500000) // 宏中包含VA表示虚拟地址
10、动态内存映射
为什么request_mem_region 和ioremap 一起使用?
- 资源保护和映射:
request_mem_region确保资源不被其他驱动程序使用,并且提供了资源的详细信息。ioremap则用于创建实际的虚拟地址映射。 - 灵活性和控制:结合使用两个函数,驱动程序可以同时获得资源保护的好处和
ioremap提供的灵活性。
struct resource *res = request_mem_region(phys_addr, len, "MyDevice"); // 向内存申请空间,确保不会被其他占用
if (!res) {
// 处理错误
}
void *virt_addr = ioremap(res->start, len); // 申请内存资源
if (!virt_addr) {
// 处理错误
}
// 使用 virt_addr 访问硬件资源
// ...
iounmap(virt_addr); // 释放内存资源
release_mem_region(res); // 告知内存不必占用此块内存区间问:为啥不把这俩函数合并成一个呢?既保证内核的内存区域是独立访问的,又实现了外设在内存中的映射。
答:只能是历史原因,二者在linux发行版本中有个先后顺序,一个是另一个的补丁。
request_mem_region和ioremap这俩函数哪个出现得早?
request_mem_region函数主要用于从系统分配一段连续的内存区域(Memory Region),并请求内核保留这段内存区域不被其他部分使用。这个函数通常在驱动程序初始化时使用,确保驱动程序可以安全地访问所需的内存区域。
ioremap函数用于将物理内存地址映射到内核的虚拟地址空间,使得内核可以访问设备内存中的数据。这个函数通常用于设备驱动程序,允许驱动程序访问设备寄存器或内存。一般来说,
request_mem_region可能比ioremap出现得更早,因为内存区域请求和映射是内存管理的基础部分,而设备驱动程序访问设备的内存映射功能则是更具体的需求。request_mem_region函数出现在Linux内核2.6.18版本中。
ioremap函数出现在Linux内核2.6.20版本中。
因此,ioremap出现在request_mem_region之后。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











