




 本文是关于深度学习目标检测的论文阅读笔记,涵盖了RefineNet的多路径细化网络、Single-Shot Refinement Neural Network的改进SSD方法、Region Proposal by Guided Anchoring的引导锚点提议网络,以及Learning Pairwise Relationship在拥挤场景中多目标检测的应用。这些研究共同关注如何提升目标定位的精度,特别是在复杂和密集场景中。
本文是关于深度学习目标检测的论文阅读笔记,涵盖了RefineNet的多路径细化网络、Single-Shot Refinement Neural Network的改进SSD方法、Region Proposal by Guided Anchoring的引导锚点提议网络,以及Learning Pairwise Relationship在拥挤场景中多目标检测的应用。这些研究共同关注如何提升目标定位的精度,特别是在复杂和密集场景中。
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
Main idea:
- down-sampling 后的 deconvolution 不能恢复low-level 的feature。features from all levels are helpful for semantic segmentation. 高层特征有助于物体识别与分类, 低层特征则帮助生成sharp detailed boundaries.
- 提出了一种 multi-path refinement network(RefineNet), 能够提取多层次特征。
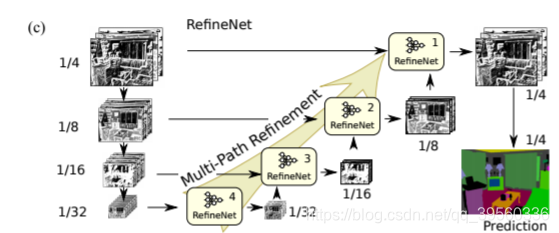
如上图,Refine net 的主要架构就是: 在resnet101(或其他基础网络)的四个不同尺度层的基础上通过4个级联的RefineNet block 最后得到输出。
RefineNet block:
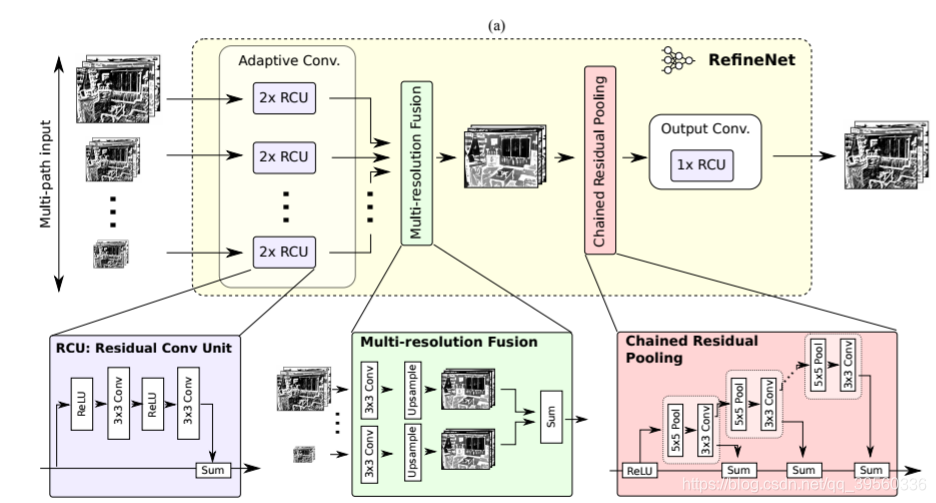
如上图:RefineNet主要分为四个部分。
- RCU:RCU就把所有输入经过一个类似于resnet的模块。在RefineNet中,输入可能是2个或者1个(refineNet4)
- Multi-resolution Fussion: 主要把RCU得到的两层合起来。主要就卷积之后,小的层上采样后和大的层加起来。
- Chained Residual Polling: 为了提取背景信息。一般用两个模块,每个模块先卷积,再pooling(5x5),(stride=1),也用了shortcut.
- 最后有一个RCU.
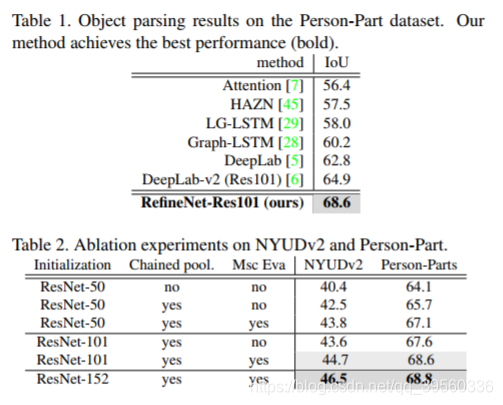
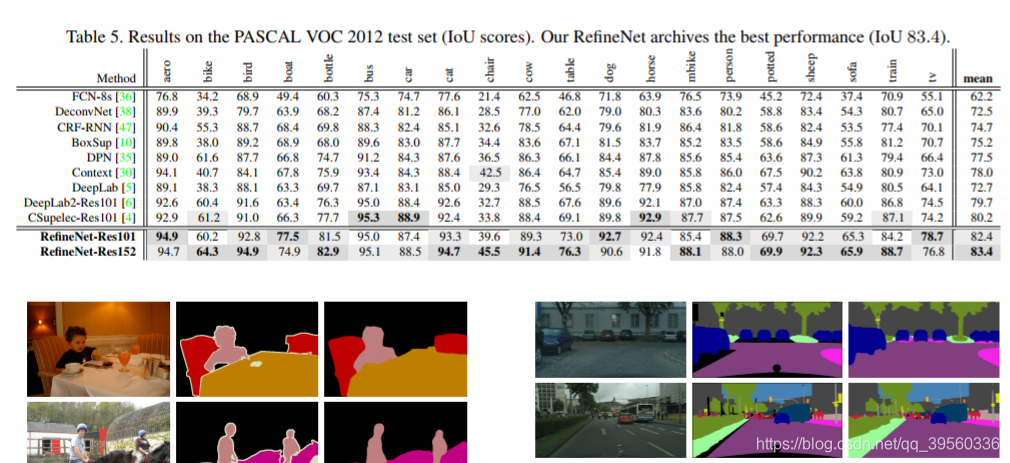
实验:
Single-Shot Refinement Neural Network for Object Detection
Main idea:
- . propose RefineDet (the anchor refinement module and the object detection module.) 主要对ssd的anchor调整,1. 滤去了negative anchor, 2. 调整anchor的大小和位置。结合了two-stage和one-stage的方法,two-stage更准,one-stage更快。two-stage中有RPN可以去除极端样本,解决imbalance问题。
- . 网络结构:
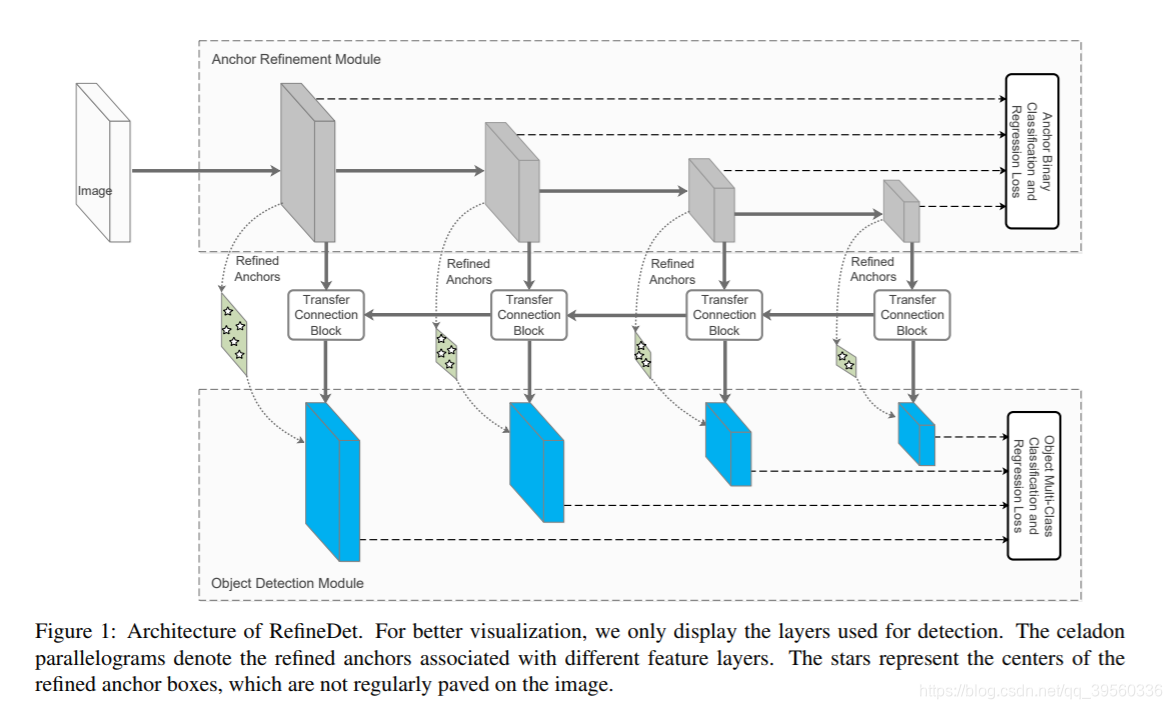
如上图,包括三个部分:
-
ARM(anchor refinement module):
- 作用:
- remove negative anchors.
- 粗略地调整anchor的位置和大小
- 相当于two-stage最终的RPN,
- 作用:
-
ODM(e object detection module
)- 作用:进一步调整anchor位置和预测分类
- 和ssd结尾差不多
- Negative Anchor Filter: 如果negative confidence 超过一个阈值(i.e. 0.99),就舍弃。
-
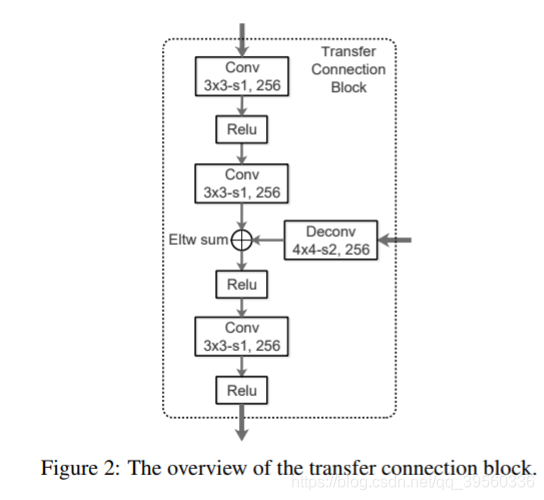
TCB(a transfer connection block)
- 作用: 连接 ARM和ODM
- Loss:
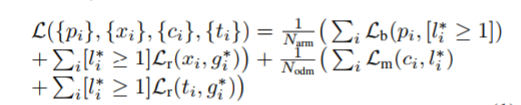
包括四部分:
1. ARM的位置regression L_r
2. ARM 处cross-entropy/log loss over two classes L_b
2. ODM 处位置regression L_r
3. multi-class classifi-cation loss L_m
Region Proposal by Guided Anchoring
Main idea: Gaided Anchoring
-
Uniform anchoring drawback:
a. 必须为不同问题手动设计不同的比例
b. anchor数量太多 -
提出了一个更有效的方法生成anchor:
a.first identifying sub-regions that may contain objects
b. then determining the scales and aspect ratios at different locations. -
Scales and aspect ratios of anchors are now variable instead of fixed
-
Guided Anchoring Region Proposal Network (GA-RPN)
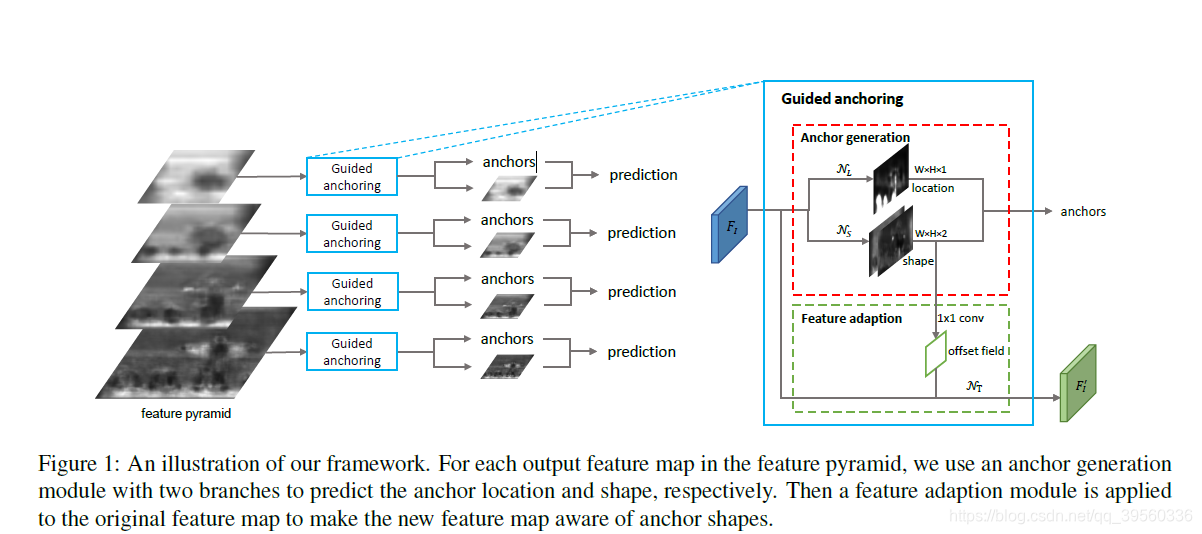
网络架构如上图,
其中N_l 为一个1x1卷积 后加一个sigmoid, 生成这个块有没有object的分数。 下面那个N_s也是1x1卷积,产生两个通道,分别是dw,dh. 产生框的形状。这个框的形状是这样算的:
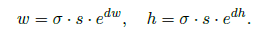
在判断哪里有框的部分,它是这样的:

即:ground truth框的中间对应的块为正样本,边一点就不算,边缘就负样本。
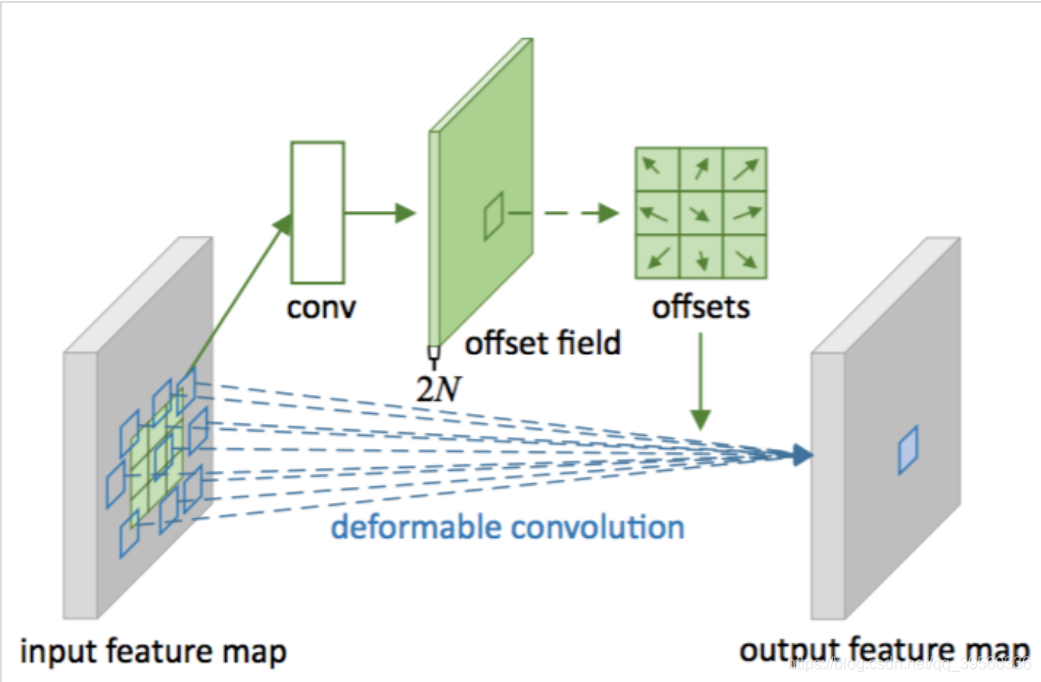
在Feature Adaption部分, 主要是要根据学到的anchor重新生成feature map. N_T用到了可变形卷积(Deformable Convolutional Networks),大概长这样:
最后有四部分loss:
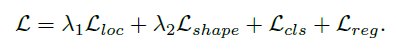
大概也是anchor和最后的两部分loss加起来。
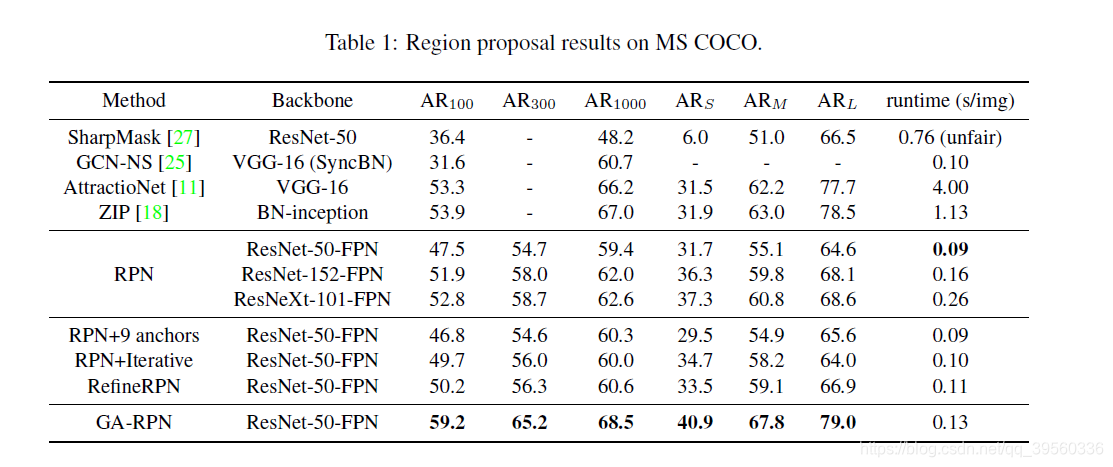
结果(贴一个):

Learning Pairwise Relationship for Multi-object Detection in Crowded Scenes
Main idea:
- 普通的非极大抑制(NMS)不能将两个很近的相似object分开。 比如拥挤的人群检测就很难。所以提出了一种Pairwise网络专门判断到底有没有两个人。
- 首先判断两个proposal之间的IOU(交并比)大小, 超过一个阈值才把两个proposal送入paisewise网络.
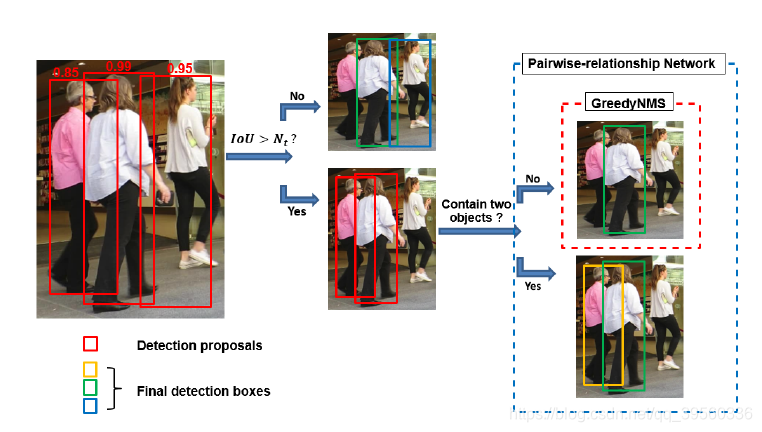
- 然后paisewise的主要结构如下:
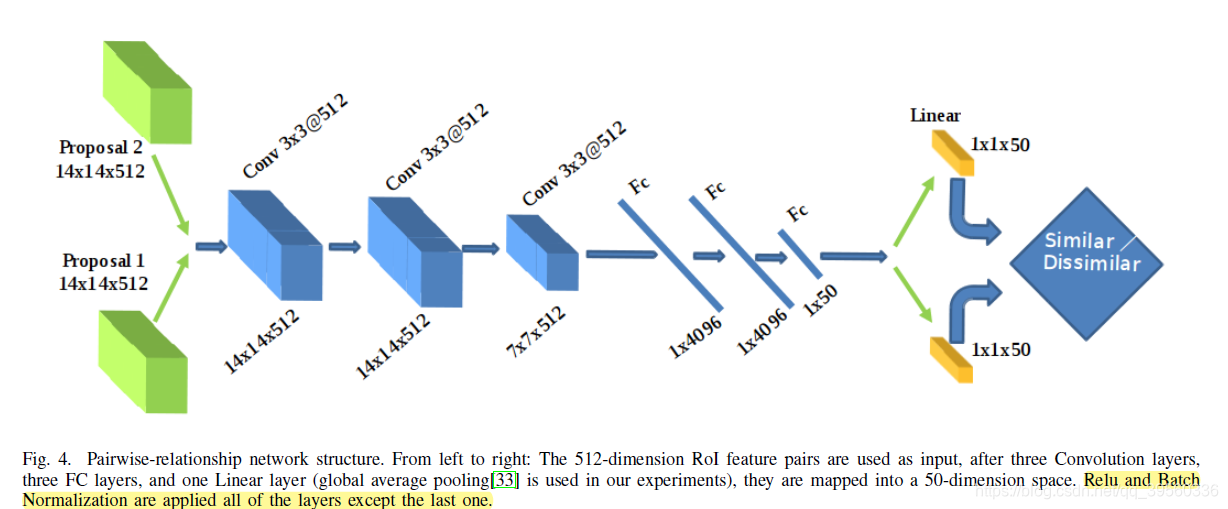
- 主要思想就是把生成两个框的feature map(14x14x512)丢进去卷一下,映射到高维,比一下两个向量的相似度. 这里的feature map用了 VggNet中的Conv4_3, 也就是放缩了1/8. 然后这里用了ROIAlign技术得到14*14固定大小的tensor.
- Global Average Pooling: 最后一个FC换成这个会好一点
- Loss:
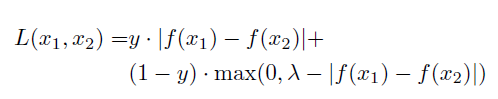
- 和GreedyNMS一起使用更佳,IOU超过阈值使用greedyNMS。
总结:
除了第一个refineNet是分割任务外,基本上都是检测任务。都用到那种多层次特征结合的方法。就是先经过一个网络缩小,再从最小的feature map出发,不停upsample,和上一层级的feature结合的这种网络似乎很常见,很有效。其他几篇paper, 就抓住经典detect方法的一部分作出改进。比如用神经网络获得anchor, 针对NMS,改进之类的。

















 8256
8256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









