







 博客介绍了爬取网站信息需解决正则表达式问题,阐述了Python中正则表达式的贪婪与非贪婪匹配概念,常用非贪婪模式如.*?。还给出爬取猫眼电影Top100信息的步骤,包括进入网站、分析元素、写正则表达式分组匹配,最后将结果写入txt文件。
博客介绍了爬取网站信息需解决正则表达式问题,阐述了Python中正则表达式的贪婪与非贪婪匹配概念,常用非贪婪模式如.*?。还给出爬取猫眼电影Top100信息的步骤,包括进入网站、分析元素、写正则表达式分组匹配,最后将结果写入txt文件。
1. 爬取网站中的信息有一个很重要的点就是需要解决正则表达式的问题,我们先需要对正则表达式的常用匹配规则要清楚,这样在写匹配字符串的相关信息的时候才不会出现太大的困难,其中python中使用到的正则表达式与其他语言中使用到的正则表达式基本上是一样的
此外在python中的正则表达式的匹配有两个很重要的概念:
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配
非贪婪匹配:就是匹配到结果就好,就少的匹配字符
在python中经常使用到的是非贪婪模式进行匹配,当满足匹配条件之后使用匹配尽可能少的字符
经常使用到的是: .*?,表示的是匹配任意数量的字符,所以在python的使用正则表达式进行字符串匹配的时候使用得很多的就是这个,这是因为在网页的源代码中使用html5等语言写的标签中存在着存在着多个不相关的字符,假如像忽略掉那么直接使用.*?即可以贪婪的方式来进行匹配即可
1 . 匹配任意除换行符“\n”外的字符;
2 *表示匹配前一个字符0次或无限次;
3 +或*后跟?表示非贪婪匹配,即尽可能少的匹配,如*?重复任意次,但尽可能少重复;
4 .*? 表示匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。
如:a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab和ab。
2. 弄清楚了上面的基本概念之后我们来写一下爬取猫眼电影top100的有关信息的程序,步骤如下:
(1)首先是进入网站首页:https://maoyan.com/
(2)点击导航栏中的榜单,找到Top100
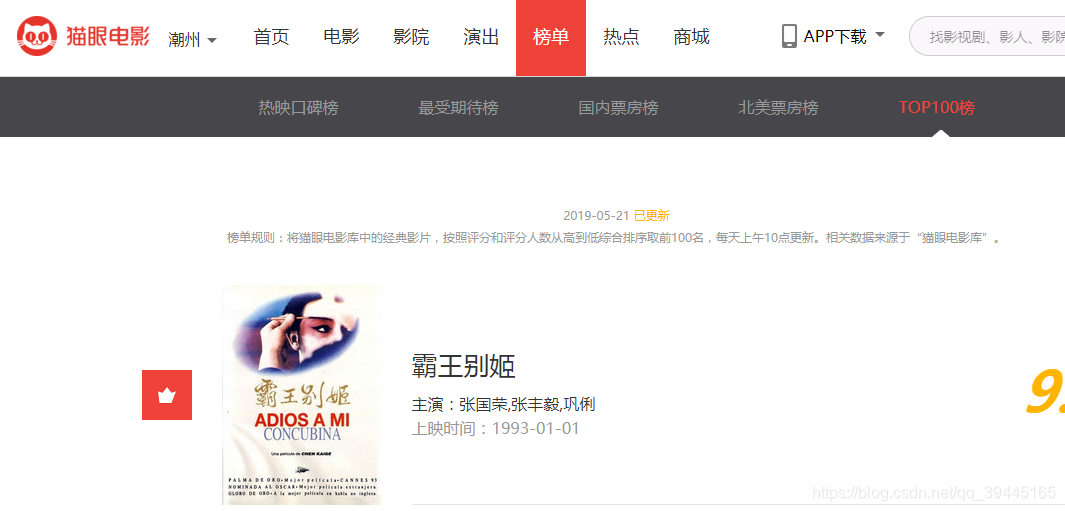
(3)在浏览器中打开开发者工具,谷歌浏览器中可以使用fn + f12来打开
打开之后分析我们需要爬取的有关信息,可以点击一下下图中箭头所指的图标然后点击左边网页中的元素那么就可以定位到网页中相应控件的源代码这样我们在写正则表达式进行匹配的时候就非常方便
定位到我们需要爬取的控件对应的源代码:我们想要爬取的主要有六个信息
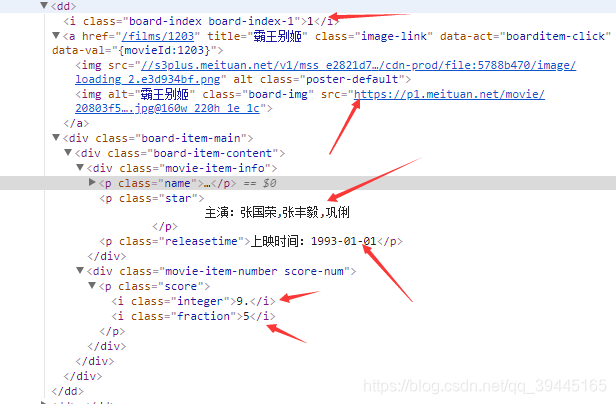
接下来就是对应相应的控件来写出正则表达式,在匹配的正则表达式中我们需要使用到python中分组的功能,把匹配的相应的六个信息进行分组,在正则表达式中使用括号表示分组,假如中间像忽略若干个没有的字符那么使用.*?进行匹配,匹配相关的字符将对应的字符找这些即可,最后将爬取的结果写到一个txt文件中,在写文件的时候需要规定编码这样写进txt文件中的就不是默认的Unicode编码
下面是具体的代码:
# -*- coding: utf-8 -*-
"""
Created on Tue May 21 20:28:58 2019
@author: administrator
"""
import requests
from requests.exceptions import RequestException
import re
import json
#导入进程池
#from multiprocessing import pool as pool
def get_one_page(url):
try:
response = requests.get(url)
# 200代表请求已成功被服务器接收
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
# 重点是需要会写python中匹配的正则表达式
# .*?表示的是贪婪模式(表示的是任意多个字符)
# python中的字符串的正则表达式一定要写对
# 否则程序都运行不了会直接蹦了
pattern = re.compile('<dd>.*?board-index.*?(\d+)</i>.*?alt.*?src="(.*?)"'
+ '.*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'
+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, html)
for item in items:
yield{
'index': item[0],
'image': item[1],
'title': item[3].strip()[3:],
'time': item[4].strip()[5:],
'score': item[5] + item[6]
}
def main(offset):
url = "https://maoyan.com/board/4?offset=" + str(offset)
print(url, '----\n')
html = get_one_page(url)
# print(html)
parse_one_page(html)
for item in parse_one_page(html):
# print(item)
write_to_file(item)
def write_to_file(content):
# 下面需要加上编码否则在输出的时候会将Unicode编码输出来
# 注意文件的绝对路径要写成双斜杠
with open('result.txt', 'a', encoding = 'utf-8') as f:
f.write(json.dumps(content, ensure_ascii = False) + '\n')
f.close()
if __name__ == '__main__':
for i in range(10):
main(i * 10)
# pool = Pool()
# pool.map(main, [i * 10 for i in range(10)])

















 1474
1474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









