







1. 关于进程
在linux操作系统中,进程通过fork()函数调用,通过复制一个现有的进程来创建一个新的进程;
调用fork()的叫做父进程,而创建的进程叫子进程,fork()调用从内核返回两次,一次回到父进程,另一次回到新产生的子进程;
接着调用exec()函数可以创建新的地址空间,并把新的程序载入。
最后,通过exit()调用退出执行。
2. 进程描述符
在内核中,进程的列表存放在名为 任务队列 (task_struct)的双向链表中,链表中每一项类型都是task_struct、名为进程描述符的结构, 定义在<linux/sched.h>文件中。
linux 4.x的内核
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
.....
}
3. 分配进程描述符
每个进程的进程描述符放在其内核栈的最底端,这样可以方便类似于x86这样寄存器较少的硬件体系调用栈指针,而避免使用额外的寄存器去记录。
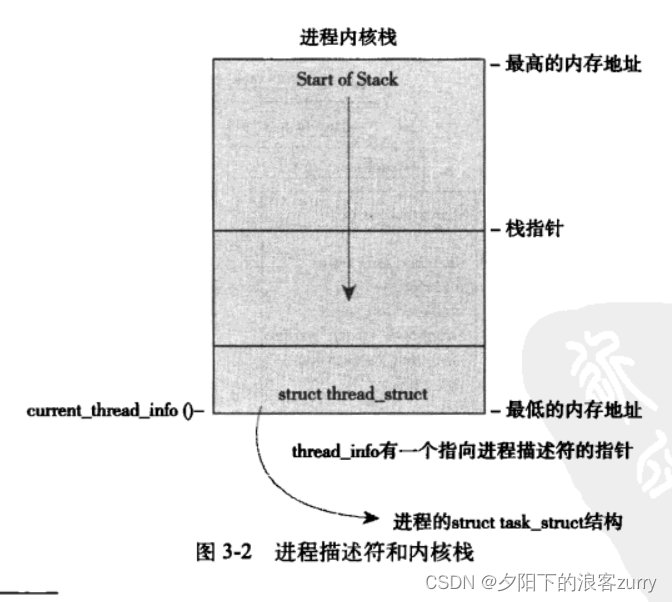
源码如下(在/x86/include/asm/thread_info.h中):
struct thread_info {
struct task_struct *task; /* main task structure */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
mm_segment_t addr_limit;
unsigned int sig_on_uaccess_error:1;
unsigned int uaccess_err:1; /* uaccess failed */
};
每个任务的thread_info结构在其内核栈的尾端分配。
进程描述符的存放
内核通过唯一的进程标识值或者 PID 来标识每个进程;
PID 是 一个属于pid_t 类型的数(实际上就是int),其最大默认值在<linux/threads.h>文件中可以看到,而内核将其放置在进程描述符中;
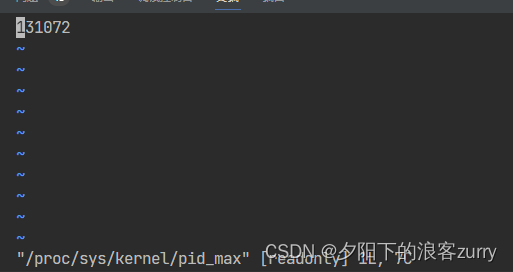
内核中pid默认值就是允许同时运行的进程的最大值,一般来说pid大的进程比pid小的进程后执行,如果要修改 pid数量的上限,可通过 vim /proc/sys/kernel/pid_max 来修改
linux 4.x内核:
在内核中,访问任务通常需要获得指向task_struct的指针,因为大部分进程的代码都是通过task_struct执行的,所以通过current宏找到当前执行程序的进程就非常重要(current宏针对不同的硬件体系,其实现也不同);
在linux 4.x的内核中,current_thread_info()函数如下:
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)(current_top_of_stack() - THREAD_SIZE); //通过当前栈顶来计算
}
最后再通过 current_thread_info()->task 找到当前task_struct的地址;
注意: thread_info 是因为x86硬件体系没有足够多的寄存器来存放task_struct结构体,只能通过内核栈的尾端创建此结构体。
进程运行的状态
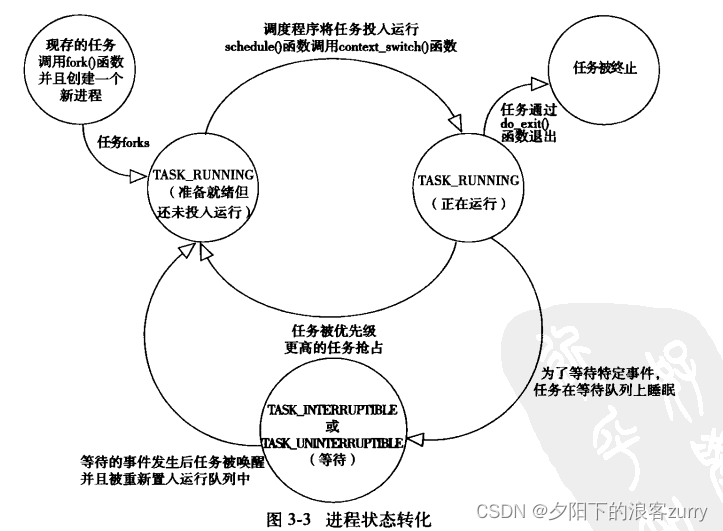
设置进程状态
set_task_state():
#define __set_task_state(tsk, state_value) \
do { (tsk)->state = (state_value); } while (0)
#define set_task_state(tsk, state_value) \
smp_store_mb((tsk)->state, (state_value))
该函数将指定的进程设置为指定的状态。必要的时候,它会设置内存屏障来强制其他处理器作重新排序(一般是在SMP系统中)。
而set_current_state() 和前者含义相同:
#define __set_current_state(state_value) \
do { current->state = (state_value); } while (0)
#define set_current_state(state_value) \
smp_store_mb(current->state, (state_value))
进程上下文
即当进程进行系统调用时从用户态转到内核态,最后又切换回用户态的一系列状态。(可执行程序代码是进程的重要部分,这些代码从可执行文件载入到进程空间执行)
进程家族树
在linux系统中,所有进程都是pid为1的进程的后代。而内核在系统启动的最后阶段会启动init进程,该进程读取系统的初始化脚本并且执行相关的程序,最终完成系统启动的整个过程。
每个进程都要一个父进程和0~n个子进程,而且每个task_struct结构都要一个执行父进程task_struct的parent指针和children链表
创建进程
Unix系统通过调用fork() 和 exec() 函数 来创建进程,子进程和父进程的区别在于PID、PPID和一些资源和统计量,exec()将可执行文件载入地址空间运行。Unix还用写时拷贝:创建子进程的时候使子进程和父进程的地址空间共享,除非写入新的数据才会进行复制操作。
而fork() 的开销就是复制父进程的页表和赋值给子进程唯一标识符。
fork() 函数调用的时候实际上调用的是clone(),clone() 再去调用 do_fork() 函数
do_fork()
long _do_fork(struct kernel_clone_args *args)
{
u64 clone_flags = args->flags;
struct completion vfork;
struct pid *pid;
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if (args->exit_signal != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(NULL, trace, NUMA_NO_NODE, args); // 重点!!!
add_latent_entropy();
if (IS_ERR(p))
return PTR_ERR(p);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, args->parent_tid);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
return nr;
}
其中do_fork() 函数调用copy_process() 函数,然后让进程开始运行:
copy_process() :
static __latent_entropy struct task_struct *copy_process(
struct pid *pid,
int trace,
int node,
struct kernel_clone_args *args)
{
int pidfd = -1, retval;
struct task_struct *p;
struct multiprocess_signals delayed;
struct file *pidfile = NULL;
u64 clone_flags = args->flags;
......
/*
* Force any signals received before this point to be delivered
* before the fork happens. Collect up signals sent to multiple
* processes that happen during the fork and delay them so that
* they appear to happen after the fork.
*/
sigemptyset(&delayed.signal);
INIT_HLIST_NODE(&delayed.node);
spin_lock_irq(¤t->sighand->siglock);
if (!(clone_flags & CLONE_THREAD))
hlist_add_head(&delayed.node, ¤t->signal->multiprocess);
recalc_sigpending();
spin_unlock_irq(¤t->sighand->siglock);
retval = -ERESTARTNOINTR;
if (signal_pending(current))
goto fork_out;
retval = -ENOMEM;
p = dup_task_struct(current, node); //重点!!!
if (!p)
goto fork_out;
.....
copy_process() 函数 完成了下列工作:
- 调用dup_task_struct() 函数,为进程创建内核栈,thread_info,task_struct,这些值和进程描述符在此时子进程和父进程是相同的;
static struct task_struct *dup_task_struct(struct task_struct *orig, int node)
{
struct task_struct *tsk; //创建新的task_struct
unsigned long *stack; //创建内核栈
struct vm_struct *stack_vm_area __maybe_unused;
int err;
.......
- 检查创建该线程后,当前用户拥有的线程数有没有超过系统允许的最大值;
- 子进程与父进程区分开;
- 子进程的状态设置为TASK_UNITERRUPTIBLE;
- 调用copy_fs() 来更新task_struct的flags成员;
static int copy_fs(unsigned long clone_flags, struct task_struct *tsk)
{
struct fs_struct *fs = current->fs;
if (clone_flags & CLONE_FS) {
/* tsk->fs is already what we want */
spin_lock(&fs->lock);
if (fs->in_exec) {
spin_unlock(&fs->lock);
return -EAGAIN;
}
fs->users++;
spin_unlock(&fs->lock);
return 0;
}
tsk->fs = copy_fs_struct(fs); //更新
if (!tsk->fs)
return -ENOMEM;
return 0;
}
- 调用alloc_pid() 来给新进程分配一个有效的pid;
if (pid != &init_struct_pid) {
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
if (IS_ERR(pid)) {
retval = PTR_ERR(pid);
goto bad_fork_cleanup_thread;
}
}
- copy_process() 函数根据参数,拷贝或共享打开的文件,文件系统信息,信号处理函数,进程地址空间和命名空间;
- copy_process()函数做扫尾工作,并返回一个指向 子进程的指针。
vfork():
除了不拷贝父进程的页表项外,fork() 和 vfork() 的功能相同。
| fork | vfork |
|---|---|
| 拷贝父进程的地址空间 | 共享父进程的地址空间 |
- vfork()创建的子进程在访问地址空间时,会造成父进程访问地址空间是阻塞;
- 而vfork在调用do_fork()函数时,如果给定特定标识,vfork_done会指向一个特定的地址;
- 子进程比父进程先执行,父进程先等待,直到子进程通过vfork_done 并向父进程发送信号量;
- 调用mm_release() ,用于进程退出地址空间;
- 回到do_fork(),父进程醒来并返回;
线程:
原本在操作系统中,并没有线程的概念,Linux把所有线程都当作进程来实现,被视为一个与其他进程共享某些资源的线程,每个线程都要一个隶属于自己的 task_struct。
对于Linux来说,线程只是进程共享资源的一种手段,创建线程和创建普通进程的方式类似,只不过线程调用clone()函数时,需要多加一些参数。
内核线程(独立运行在内核空间的标准进程):
内核有时候需要通过创建内核线程在后台完成工作,和普通进程一样,内核进程可以调度,也可也被抢占,但区别在于没有独立的地址空间,只能在内核态运行,不可以切换到用户态,只能由内核线程创建!!!
在<linux/kthread.c>文件中,有关于内核线程的代码:
struct task_struct *kthread_create_on_cpu(int (*threadfn)(void *data),
void *data, unsigned int cpu,
const char *namefmt)
{
struct task_struct *p;
p = kthread_create_on_node(threadfn, data, cpu_to_node(cpu), namefmt,
cpu);
if (IS_ERR(p))
return p;
kthread_bind(p, cpu);
/* CPU hotplug need to bind once again when unparking the thread. */
to_kthread(p)->cpu = cpu;
return p;
}
<linux/kthread.h>
该函数由宏实现
#define kthread_run(threadfn, data, namefmt, ...) \
({ \
struct task_struct *__k \
= kthread_create(threadfn, data, namefmt, ## __VA_ARGS__); \
if (!IS_ERR(__k)) \
wake_up_process(__k); \
__k; \
})
新创建的进程处于不可运行的状态,如果没有调用wake_up_process(),他不会主动运行。
而内核线程启动后到结束,调用do_exit() 和 kthread_stop() 退出。
进程终结:
大部分进程的终结都要依靠do_exit() 函数来完成,do_exit() 函数有以下步骤:
- 将task_struct 中的标志成员设置为 PF_EXITING;
void __noreturn do_exit(long code)
{
struct task_struct *tsk = current;
int group_dead;
.....
if (unlikely(tsk->flags & PF_EXITING)) { /
pr_alert("Fixing recursive fault but reboot is needed!\n");
futex_exit_recursive(tsk);
set_current_state(TASK_UNINTERRUPTIBLE);
schedule();
}
exit_signals(tsk); // 将task_struct 中的标志成员设置为 PF_EXITING;
void exit_signals(struct task_struct *tsk)
{
int group_stop = 0;
sigset_t unblocked;
/*
* @tsk is about to have PF_EXITING set - lock out users which
* expect stable threadgroup.
*/
cgroup_threadgroup_change_begin(tsk);
if (thread_group_empty(tsk) || signal_group_exit(tsk->signal)) {
tsk->flags |= PF_EXITING;
cgroup_threadgroup_change_end(tsk);
return;
}
spin_lock_irq(&tsk->sighand->siglock);
/*
* From now this task is not visible for group-wide signals,
* see wants_signal(), do_signal_stop().
*/
tsk->flags |= PF_EXITING; //在此处设置 !!!
cgroup_threadgroup_change_end(tsk);
if (!signal_pending(tsk))
goto out;
unblocked = tsk->blocked;
signotset(&unblocked);
retarget_shared_pending(tsk, &unblocked);
if (unlikely(tsk->jobctl & JOBCTL_STOP_PENDING) &&
task_participate_group_stop(tsk))
group_stop = CLD_STOPPED;
out:
spin_unlock_irq(&tsk->sighand->siglock);
/*
* If group stop has completed, deliver the notification. This
* should always go to the real parent of the group leader.
*/
if (unlikely(group_stop)) {
read_lock(&tasklist_lock);
do_notify_parent_cldstop(tsk, false, group_stop);
read_unlock(&tasklist_lock);
}
}
- 删除内核定时器,确保没有定时器在排队,也没有定时器程序在运行;
(原本是del_timer_sync() 函数,但在linux 5.4.0的源码中我只找到了如下代码:)
group_dead = atomic_dec_and_test(&tsk->signal->live);
if (group_dead) {
/*
* If the last thread of global init has exited, panic
* immediately to get a useable coredump.
*/
if (unlikely(is_global_init(tsk)))
panic("Attempted to kill init! exitcode=0x%08x\n",
tsk->signal->group_exit_code ?: (int)code);
#ifdef CONFIG_POSIX_TIMERS
hrtimer_cancel(&tsk->signal->real_timer);
exit_itimers(tsk->signal);
#endif
if (tsk->mm)
setmax_mm_hiwater_rss(&tsk->signal->maxrss, tsk->mm);
}
- 如果BSD功能是开启的,do_exit() 函数会调用 acct_update_integrals(tsk) 来输出记账信息;
- 然后调用exit_mm() 函数释放掉进程占用的mm_struct,如果没有别的进程使用的话,就彻底释放;
....
audit_free(tsk);
tsk->exit_code = code;
taskstats_exit(tsk, group_dead);
exit_mm(); //此处
static void exit_mm(void)
{
struct mm_struct *mm = current->mm;
struct core_state *core_state;
exit_mm_release(current, mm);
if (!mm)
return;
sync_mm_rss(mm);
/*
* Serialize with any possible pending coredump.
* We must hold mmap_sem around checking core_state
* and clearing tsk->mm. The core-inducing thread
* will increment ->nr_threads for each thread in the
* group with ->mm != NULL.
*/
down_read(&mm->mmap_sem);
core_state = mm->core_state;
if (core_state) {
struct core_thread self;
up_read(&mm->mmap_sem);
self.task = current;
if (self.task->flags & PF_SIGNALED)
self.next = xchg(&core_state->dumper.next, &self);
else
self.task = NULL;
/*
* Implies mb(), the result of xchg() must be visible
* to core_state->dumper.
*/
if (atomic_dec_and_test(&core_state->nr_threads))
complete(&core_state->startup);
for (;;) {
set_current_state(TASK_UNINTERRUPTIBLE);
if (!self.task) /* see coredump_finish() */
break;
freezable_schedule();
}
__set_current_state(TASK_RUNNING);
down_read(&mm->mmap_sem);
}
mmgrab(mm);
BUG_ON(mm != current->active_mm);
/* more a memory barrier than a real lock */
task_lock(current);
current->mm = NULL;
up_read(&mm->mmap_sem);
enter_lazy_tlb(mm, current);
task_unlock(current);
mm_update_next_owner(mm);
mmput(mm);
if (test_thread_flag(TIF_MEMDIE))
exit_oom_victim();
}
- 接着调用exit_sem(tsk),如果进程排队等候IPC信号,则离开队列;
- 然后调用exit_files(tsk) 和 exit_fs(tsk) 分别递减文件描述符,文件系统数据的引用计数,如果计数为0,则代表该资源没有被使用,可以释放;
- 将task_struct 的 exit_code 成员中的任务退出代码置为exit() 提供的任务退出代码,或者去完成由其他内核定制的退出动作;退出代码随时给父进程检索;
- 调用exit_notify(tsk, group_dead),并给该线程寻找养父线程,养父线程为线程组中其他线程或者init线程,并把线程状态设置为EXIT_ZOMBIE;
static void exit_notify(struct task_struct *tsk, int group_dead)
{
bool autoreap;
struct task_struct *p, *n;
LIST_HEAD(dead);
write_lock_irq(&tasklist_lock);
forget_original_parent(tsk, &dead);
if (group_dead)
kill_orphaned_pgrp(tsk->group_leader, NULL);
tsk->exit_state = EXIT_ZOMBIE; //在此处设置状态!!!
if (unlikely(tsk->ptrace)) {
int sig = thread_group_leader(tsk) &&
thread_group_empty(tsk) &&
!ptrace_reparented(tsk) ?
tsk->exit_signal : SIGCHLD;
autoreap = do_notify_parent(tsk, sig);
} else if (thread_group_leader(tsk)) {
autoreap = thread_group_empty(tsk) &&
do_notify_parent(tsk, tsk->exit_signal);
} else {
autoreap = true;
}
if (autoreap) {
tsk->exit_state = EXIT_DEAD;
list_add(&tsk->ptrace_entry, &dead);
}
/* mt-exec, de_thread() is waiting for group leader */
if (unlikely(tsk->signal->notify_count < 0))
wake_up_process(tsk->signal->group_exit_task);
write_unlock_irq(&tasklist_lock);
list_for_each_entry_safe(p, n, &dead, ptrace_entry) {
list_del_init(&p->ptrace_entry);
release_task(p);
}
}
- 调用schedule() 切换到新的进程,之前置为EXIT_ZOMBIE的进程不会再被调度,所有此处为该函数最后一处代码,退出后不再返回;
EXIT_ZOMBIE的进程不可运行(在内核态没有地址空间,也无法运行),唯一的作用就是想父进程提供信息(系统还保留了进程描述符),父进程收到信息并告诉内核是无关的信息,之前进程所持有的内存被释放,归还给操作系统。
最终需要删除进程描述符时,会调用release_task()
void release_task(struct task_struct *p)
{
struct task_struct *leader;
int zap_leader;
repeat:
/* don't need to get the RCU readlock here - the process is dead and
* can't be modifying its own credentials. But shut RCU-lockdep up */
rcu_read_lock();
atomic_dec(&__task_cred(p)->user->processes);
rcu_read_unlock();
proc_flush_task(p);
cgroup_release(p);
write_lock_irq(&tasklist_lock);
ptrace_release_task(p);
__exit_signal(p); // 删除进程,并删除该进程的所有资源,并进行统计和记录
/*
* If we are the last non-leader member of the thread
* group, and the leader is zombie, then notify the
* group leader's parent process. (if it wants notification.)
*/
zap_leader = 0; //如果该进程是线程组的最后一个进程,并且领头进程已经死掉,则该函数通知已经死掉的领头进程的父进程;
leader = p->group_leader;
if (leader != p && thread_group_empty(leader)
&& leader->exit_state == EXIT_ZOMBIE) {
/*
* If we were the last child thread and the leader has
* exited already, and the leader's parent ignores SIGCHLD,
* then we are the one who should release the leader.
*/
zap_leader = do_notify_parent(leader, leader->exit_signal);
if (zap_leader)
leader->exit_state = EXIT_DEAD;
}
write_unlock_irq(&tasklist_lock);
release_thread(p);
put_task_struct_rcu_user(p); //释放进程内核栈和thread_info所占的页,以及task_struct 的slab高速缓存
p = leader;
if (unlikely(zap_leader))
goto repeat;
}
至此,进程被完全释放;
之前提到会给僵尸进程寻找养父进程,代码如下:
static struct task_struct *find_new_reaper(struct task_struct *father,
struct task_struct *child_reaper)
{
struct task_struct *thread, *reaper;
thread = find_alive_thread(father);
if (thread)
return thread;
if (father->signal->has_child_subreaper) {
unsigned int ns_level = task_pid(father)->level;
/*
* Find the first ->is_child_subreaper ancestor in our pid_ns.
* We can't check reaper != child_reaper to ensure we do not
* cross the namespaces, the exiting parent could be injected
* by setns() + fork().
* We check pid->level, this is slightly more efficient than
* task_active_pid_ns(reaper) != task_active_pid_ns(father).
*/
for (reaper = father->real_parent;
task_pid(reaper)->level == ns_level;
reaper = reaper->real_parent) {
if (reaper == &init_task)
break;
if (!reaper->signal->is_child_subreaper)
continue;
thread = find_alive_thread(reaper);
if (thread)
return thread;
}
}
return child_reaper;
}

















 347
347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









