







本系列
前言
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器
以组件形式工作在应用项目中,和leaf 不同,leaf是提供server集群,client调server获取ID
有以下特性:
- 通过特殊的workerId分配策略,解决workerId不好手动指定,以及唯一性问题
- 通过时钟不回退解决时钟回拨导致的ID重复问题
- 通过借用未来时间来解决雪花算法天然存在的并发限制
下面依次分析这些特性的实现原理
每一位分配
ID中每一位的分配默认如下:

- 最高位:符号位为0,表示是正数
- 接下来28位:以秒为单位的时间范围,28位的秒能表示8.5年。看起来很少。但如果用cached模式的话这28位和系统时间关系不大,下文详细介绍
- 接下来22位:workerId,最多支持419w
- 最低13位:每一秒的序列号,13bit最多支持8192个
雪花算法的难点就是怎么保证ID不重复,分解到每一位中就是保证:
- 不同的机器一定有不同的workerId,由于代表worker的22位不同,那么不同机器产生的ID一定不同
- 以及相同的机器产生的所有ID中时间戳不同,由于代表时间戳的28位不同,那么产生的ID一定不同
- 要做到这点,就要解决时钟回拨问题
怎么保证workerId不重复
workId使用数据库自增主键生成,每次业务实例启动都生成个新的,用后即弃,因此永远不会重复
不仅不同机器之间不会重复,相同机器重启后也不会和之前的自己重复
同时也解决了手动配置workerId麻烦的问题
public long assignWorkerId() {
// build worker node entity
WorkerNodeEntity workerNodeEntity = buildWorkerNode();
// 往db插一条记录
workerNodeDAO.addWorkerNode(workerNodeEntity);
// 返回主键,当做workerId
return workerNodeEntity.getId();
}
只用在db建这张表:其他字段都是描述实例的信息,最关键的就是自增id
CREATE TABLE WORKER_NODE
(
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATE NOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time',
CREATED TIMESTAMP NOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
)
COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;
22位的workerId最多支持419w次启动,如果 每7天重启1次,一年52次,如果按用100年算,能支持接近800台机器。对绝大多数业务来说都够用了
降低重启频率,降低使用年限,以及扩展workerId的bit位,还能支持更多的机器
怎么解决时钟回拨
uid-generator提供了default模式和cached模式,区别在于cached模式能突破每秒qps限制,以及能用更久的时间,下文基于cached模式介绍
uid-generator解决时钟回拨的方法就是,代表时间戳的28位和真实时间没有关系,而是从某一秒开始,直到这个一秒拥有的序列号都用完,才会用下一秒
源码中的开始秒数为:从机器启动开始时间减去2016-5-20对应时间的秒数,但到现在应该已经超过8.5年了,所以需要改改源码。实际上从1开始递增也行
也就是说,这28位只会递增,永远不会回退。和系统时间没关系,也就没有时钟回拨的问题了
但带来的一点小问题就是,生成的ID和时间关联性不大
上一节提到,每个实例每次重启都不会重复,这里再保证每个实例运行期间也不会重复,因此生成的ID保证绝对唯一
怎么突破每秒qps限制
如果是标准雪花算法,每一秒生成的ID数量是有限制的,因为每次获取ID时就要计算当前时间戳,如果当前时间戳的序列号满了,只能等待。不能借用未来的时间戳。因为如果借用了,就可能和未来产生的ID重复
cached模式下,不再每次获取ID时都基于当前时间,而是从一个环形队列中获取
当发现环形队列余量不够时,异步拿下一个时间 lastSecond + 1 的所有序列号填充环形队列,填充完让 lastSecond++
这样还能不能获取下一个ID,就和当前时间没关系了,只和队列中还有没有剩余ID有关系。只要填充速度足够快,就能打破标准雪花算法的每秒qps限制
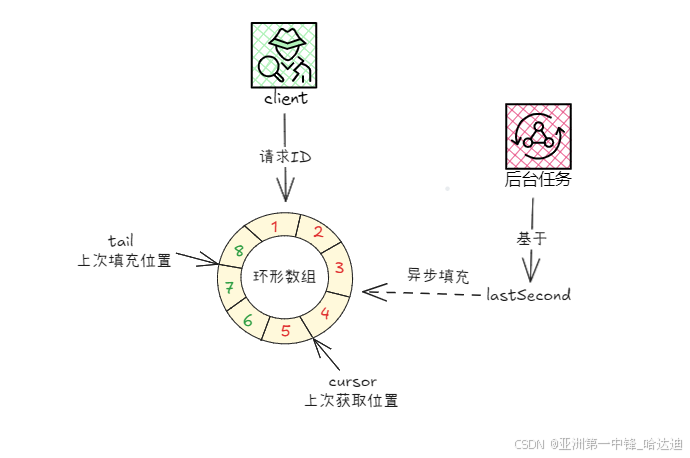
获取ID源码如下:
public long take() {
// 上一个读到的位置
long currentCursor = cursor.get();
// 更新读到的位置+1,如果满了不更新
long nextCursor = cursor.updateAndGet(old -> old == tail.get() ? old : old + 1);
// 如果剩下空间少到一定阈值,异步填充
long currentTail = tail.get();
if (currentTail - nextCursor < paddingThreshold) {
bufferPaddingExecutor.asyncPadding();
}
// 满了,拒绝
if (nextCursor == currentCursor) {
rejectedTakeHandler.rejectTakeBuffer(this);
}
int nextCursorIndex = calSlotIndex(nextCursor);
long uid = slots[nextCursorIndex];
// 返回id
return uid;
}
异步填充流程:
public void paddingBuffer() {
// is still running
if (!running.compareAndSet(false, true)) {
LOGGER.info("Padding buffer is still running. {}", ringBuffer);
return;
}
// 填充buffer中所有可填充的空间
boolean isFullRingBuffer = false;
while (!isFullRingBuffer) {
// 获取接下来几秒的所有id,直到填满ringBuffer
List<Long> uidList = uidProvider.provide(lastSecond.incrementAndGet());
for (Long uid : uidList) {
isFullRingBuffer = !ringBuffer.put(uid);
if (isFullRingBuffer) {
break;
}
}
}
// not running now
running.compareAndSet(true, false);
}
uidProvider.provide的实现如下:
protected List<Long> nextIdsForOneSecond(long currentSecond) {
int listSize = (int) bitsAllocator.getMaxSequence() + 1;
List<Long> uidList = new ArrayList<>(listSize);
// 生成这一秒的第一个id,就是填充ID的各个位
long firstSeqUid = bitsAllocator.allocate(currentSecond - epochSeconds, workerId, 0L);
for (int offset = 0; offset < listSize; offset++) {
// 这一秒的其他id根据第一个id计算得到
uidList.add(firstSeqUid + offset);
}
return uidList;
}

















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









