







 本文介绍了Java正则表达式使用的非确定型有限状态自动机(NFA)原理,包括NFA与DFA的区别以及优化正则表达式的方法,如避免回溯、使用边界匹配和环视结构等。同时,文章讲解了Grok在Logstash中的应用,它是如何将非结构化日志转换为结构化的,并讨论了Grok的优势和限制。
本文介绍了Java正则表达式使用的非确定型有限状态自动机(NFA)原理,包括NFA与DFA的区别以及优化正则表达式的方法,如避免回溯、使用边界匹配和环视结构等。同时,文章讲解了Grok在Logstash中的应用,它是如何将非结构化日志转换为结构化的,并讨论了Grok的优势和限制。
1、正则引擎
NFA:Java使用的正则引擎是(非确定型有限状态自动机)。
概念:一个状态可以通过标记了字符或ε的多条边跳转到另一个状态。字符或ε 分别表示读入一个字符或不读入字符可以跳转到另一个状态上,比如遇到表达式的右括号和回溯。
特点:NFA的特点是匹配过程面临很多的岔路去做出选择,一旦某条岔路失败,就需要回溯,类似于深度优先搜索。不过并不一定完全遍历,完成匹配之后就停止搜索了。
比如(a|b)*abb
表达式主导:NFA引擎是表达式主导的,依次尝试正则子表达式的各种可能。特点是匹配同一个字符串,不同的表达式会影响引擎做出不同的执行过程。控制权在表达式上流动,体现是匹配了控制权就在表达式上向右移到下一个匹配组,比如一个括号里的内容或者元字符。NFA的状态可以理解为“字符串当前匹配位置和控制权在表达式的位置”。
比如用a(c|b)匹配abc的过程:
1)一开始控制权在表达式开头的a,匹配字符串的a,匹配成功;
2)控制权后移到c,去匹配字符串的b,匹配失败;
3)控制权右移到b,去匹配字符串的b,匹配成功,结束;
ac|ab匹配abc的过程会在以上过程2)和3)之间多一个回溯:
控制权右移到ab的a上,字符串回溯到a,再匹配,匹配成功;
DFA引擎:还有一种正则引擎是DFA引擎(确定型有限状态自动机),文本主导,根据文本去淘汰正则的子表达式。
只有一条字母标记的转换状态的边,意味着读入字符时只有一种可能去跳转状态。
可以理解为一个NFA上的很多可能可以转换成很多个DFA。
优点:每个字母只匹配一次,效率高
缺点:太确定了,不如NFA回溯提供的灵活
两条不同正则引擎都普适的原则:
1)最左优先匹配
匹配先从需要查找的字符串的起始位置尝试匹配;在当前位置测试整个正则表达式能匹配的每个可能,匹配到达表达式末尾就成功,否则回溯去测试其他可能。
2)标准的量词(\*,+,?,{m,n})匹配优先的(贪婪模式)
2、正则优化
依据:只要引擎报告匹配失败,它就必然尝试了所有可能。所以,如果有太多的回溯的可能,那么可能会导致程序阻塞,优化正则表达式的一个重要部分就是最小化回溯的数量。
1、测试:因处理匹配失败需要尽可能的回溯,所以较复杂的正则可以试着使用其不能匹配的字符串去测试,检查耗时漏洞。
2、选择:ac|ab→a(c|b),提取共用模式,依据最左优先匹配将常用的选择项放在前面。
3、闭包
避免.* +,用{m,n}来规定;
避免贪婪模式,使用懒惰模式,如{0,10}?;
考虑使用占有优先量词?+ *+ ++ {m,n}+,先尽可能多地去匹配,表达式后面不匹配时,也不会交还字符去回溯;如.*[0-9]*是减少正则表达式所需要的猜测;
避免*包含正则后面的内容,不然引起不必要的回溯,如.*[0-9]*
4、使用边界匹配器/锚点(^、$、\b等),限定指定位置
5、考虑使用环视结构(零宽断言)
(?<=Expression)逆序肯定环视,前缀是Expression
(?<!Expression)逆序否定环视,前缀不是Expression
(?=Expression)顺序肯定环视,后缀是Expression
(?!Expression)顺序否定环视,后缀不是Expression
逆序是从在字符串上当前迭代位置向左去匹配,顺序是向右;Java只支持逆序环视长度确定的表达式;可以圈定匹配范围,匹配失败不会进行回溯,而是进入下一轮迭代。
6、用最小范围的元字符, 少用 . 字符,尽量避免用过大的元字符,比如不用([\w\-]+)匹配字母单词,\w是包括字母数字下划线的
7、根据优先级不去使用冗余的括号。
NFA的三种基本运算:联合运算 r|s、连接运算 rs、闭包Kleene运算 r*
优先级:闭包运算符优先级最高,且是左结合的,连接第二,联合运算优先级最低。
8、区分捕获组()和非捕获组(?:),需要提取的用捕获组,不需的用非捕获组,减少状态记录,提高效率。
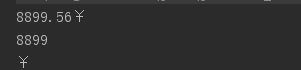
Pattern pattern = Pattern.compile("(\\d+)(?:\\.?)(?:\\d+)([¥$])$");
Matcher matcher = pattern.matcher("8899.56¥");
if (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.group(2));
}
3、Java使用grok
Grok 最主要是Logstash 的一个重要插件。
Logstash 是可以动态地采集、转换和传输服务器端数据的一个管道,并且不受格式或复杂度的影响。为何可以不受格式的影响,就是因为它的Grok插件。
通常用来把单行非结构化的日志数据,通过它默认内置的很多预定义的正则表达式,去进行逐步的模式匹配,转换成结构化的日志。
grok的pattern文件里预定义好的一些正则匹配: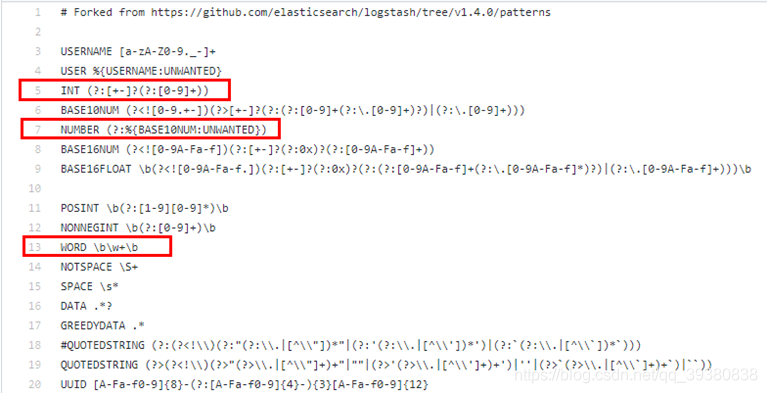
语法:%{PATTERN_NAME:NAMED_GROUP_IN_RESULT}
比如一条Apache的日志:localhost GET /index.html 1024 0.016
![]()
Java里使用grok:
可以在Maven库里看到有非常多的grok,一开始都不知道该用哪个: https://mvnrepository.com/search?q=grok
<!-- https://mvnrepository.com/artifact/io.thekraken/grok -->
<dependency>
<groupId>io.thekraken</groupId>
<artifactId>grok</artifactId>
<version>0.1.5</version>
</dependency>Last Release on Nov 15, 2016
<!-- https://mvnrepository.com/artifact/io.krakens/java-grok -->
<dependency>
<groupId>io.krakens</groupId>
<artifactId>java-grok</artifactId>
<version>0.1.9</version>
</dependency>(May 08, 2018)
io.thekraken的grok是io.krakens的旧版本,使用方法可参考大佬博客:https://blog.youkuaiyun.com/HarderXin/article/details/76838914 还有很多其他家的grok,相应官网上都有使用方法: https://github.com/aicer/grok http://grok.nflabs.com/HowToUse
最正统的logstash上的grok插件: https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
1)添加resources/pattern.txt,按照grok的pattern文件里预定义匹配式的格式,在文件里加入自定义的匹配式
2)引入Maven
<dependency>
<groupId>io.krakens</groupId>
<artifactId>java-grok</artifactId>
<version>0.1.9</version>
</dependency>3)使用Grok相关类处理
private static final String GROK_PATTERN_PATH = "src/main/resources/pattern.txt";
private static InputStream inputStream = null;
public static void main( String[] args )
{
try {
//创建实例
inputStream = new FileInputStream(new File(GROK_PATTERN_PATH));
GrokCompiler grokCompiler = GrokCompiler.newInstance();
grokCompiler.register(inputStream);
//设置匹配式
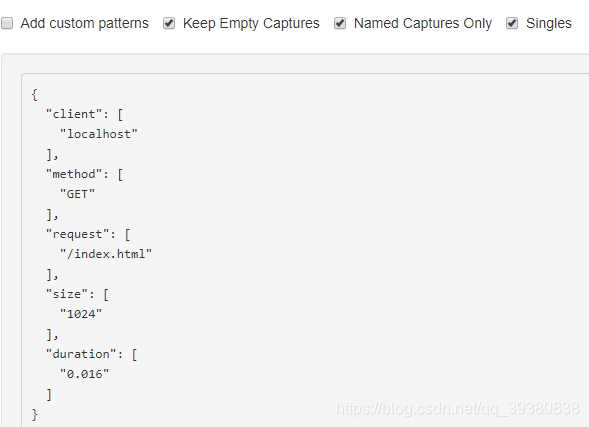
final Grok grok1 = grokCompiler1.compile("%{IPORHOST:client} %{WORD:method} %{URIPATHPARAM:request} %{INT:size} %{NUMBER:duration}");
String log1 = "localhost GET /index.html 1024 0.016";
Match gm1 = grok1.match(log1);
//执行匹配
final Map<String, Object> capture1 = gm1.capture();
System.out.println(capture1);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
System.out.println("读取pattern文件失败");
}
}
}在线调试:http://grokdebug.herokuapp.com/
官方:https://github.com/thekrakken/java-grok
4)处理结果
{duration=0.016, request=/index.html, method=GET, size=1024, URIPATH=/index.html, client=localhost, URIPARAM=null}grok评估:
1、最大的优势是它预定义了很多针对日志内容的匹配式,但规则抽取还是需要比较多自定义的匹配式,没有利用到;
2、抽取结果可以自动形成键值对,如果能在处理函数中获取,那么过滤操作时不用重新拿正则去匹配;
3、但正则对比最致命的是,如果一行包含多个可匹配结果,grok第一次匹配到就返回了,不会继续向前匹配,如
String log1 = "112 169 19 192";
final Grok grok1 = grokCompiler.compile("%{INT}");
//结果:{INT=112}
final Grok grok1 = grokCompiler.compile("(%{INT} )+");
//结果:{INT=19},使用+ ? * {n},只取最后一个匹配的
final Grok grok1 = grokCompiler.compile("%{INT} %{INT}");
//结果:{INT=[112, 169]}意味着使用一条规则能在句子里匹配到两个及以上的话,正则可以用while (matcher.find())都获取到;而grok只会返回某一个

















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









