




文章目录
汉语自动分词基本算法
1 最大匹配法(Maximum Matching , MM)
该方法是有词典切分,最大匹配法还可以分为正向最大匹配法(Forward MM,FMM)、逆向最大匹配法(Backward MM , BMM)、双向最大匹配法(Bi-directional MM)。
假设句子:
S
=
c
1
c
2
⋯
c
n
S=c_1c_2\cdots c_n
S=c1c2⋯cn,其中
c
i
c_i
ci为单个字,某一个词
w
i
=
c
1
c
2
⋯
c
m
w_i=c_1c_2\cdots c_m
wi=c1c2⋯cm,
m
m
m为词典中最长词的字数。下面给出FMM的算法描述。
1.1 FMM算法描述
对于一个输入语句:
- 令 i = 0 i=0 i=0,当前指针 p i p_i pi指向输入字串初始位置,执行以下操作:
- 计算当前指针 p i p_i pi到字串末端的字数 n n n,如果 n = 1 n=1 n=1,转4,结束算法。
- 从当前
p
i
p_i
pi起,取
m
m
m个汉字作词
w
i
w_i
wi,判断:
(a)如果 w i w_i wi是字典中的词,则在 w i w_i wi后添加一个切分标志,转(c);
(b)如果 w i w_i wi不是词典中的词且 w i w_i wi的长度大于1,将 w i w_i wi从右端去掉一个字,转(a);否则( w i w_i wi的长度等于1),则在 w i w_i wi后添加一个切分标志,将 w i w_i wi作为单字词添加到词典中,执行(c)步;
(c)根据 w i w_i wi的长度修改指针 p i p_i pi的位置,如果 p i p_i pi指向字串末端,转(4),否则, i = i + 1 i=i+1 i=i+1,返回(2); - 输出切分结果,结束分词程序。
1.2 例子
假设词典中最长单词的字数为8。输入字串:他是研究生物化学的一位科学家。FMM切分过程:
⋯
⋯
\cdots\cdots
⋯⋯
FMM切分结果:他/是/研究生/物化/学/的/一/位/科学家/。
1.3 优缺点
优点有:
- 程序简单易行,开发周期短;
- 仅需要很少的语言资源(词表),不需要任何词法、句法、语义资源。
弱点有:
- 歧义消解的能力差;
- 切分正确率不高,一般在95%左右。
2 最少分词法(最短路径法)
基本思想是,设待切分字串
S
=
c
1
c
2
⋯
c
n
S=c_1c_2\cdots c_n
S=c1c2⋯cn,其中
c
i
c_i
ci为单个字,
n
n
n为串的长度,
n
≥
1
n \ge 1
n≥1。建立一个节点数为
n
+
1
n+1
n+1的切分有向无环图
G
G
G,各节点编号依次为
v
0
,
v
1
,
v
2
,
⋯
,
v
n
v_0,v_1,v_2,\cdots,v_n
v0,v1,v2,⋯,vn。
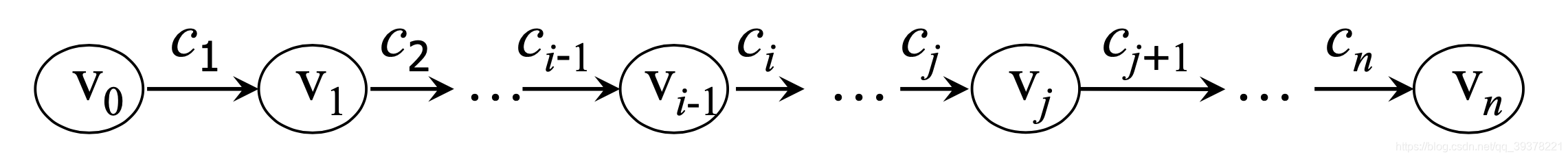
求最短路径(贪心法或简单扩展法)
2.1 算法描述
- 相邻节点 v k − 1 , v k v_{k-1},v_k vk−1,vk之间建立有向变 < v k − 1 , v k > <v_{k-1}, v_k> <vk−1,vk>,边对应的词默认为 c k c_k ck。如上图所示。
- 如果
w
=
c
i
c
i
+
1
⋯
c
j
(
0
<
i
<
j
≤
n
)
w=c_ic_{i+1}\cdots c_j(0 \lt i \lt j \le n)
w=cici+1⋯cj(0<i<j≤n)是一个词,则节点
v
i
−
1
,
v
j
v_{i-1}, v_j
vi−1,vj之间建立有向边
<
v
i
−
1
,
v
j
>
<v_{i-1}, v_j>
<vi−1,vj>,边对应的词为
w
w
w。如下图所示
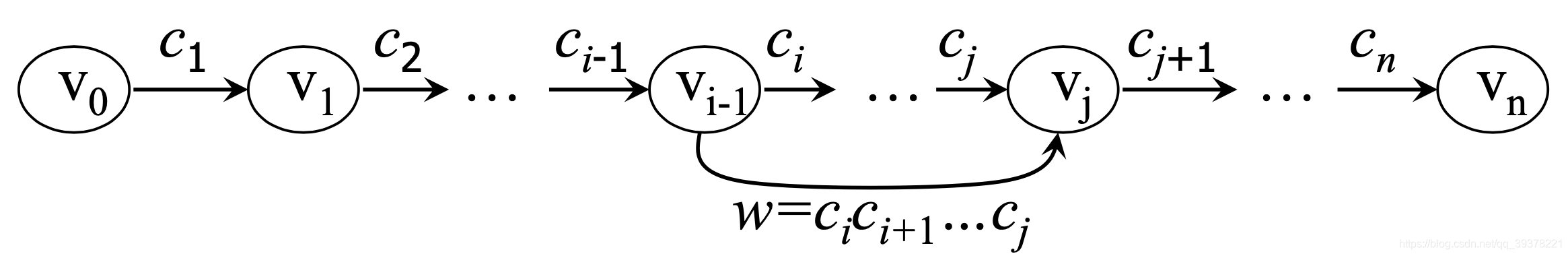
- 重复步骤2,直到没有新路径(词序列)产生。
- 从产生的所有路径中,选择路径最短的(词数最少的)作为最终分词结果。
2.2 例子
输入字串:他只会诊断一般的疾病
- 首先准备词典
- 构建词图

- 贪婪组合
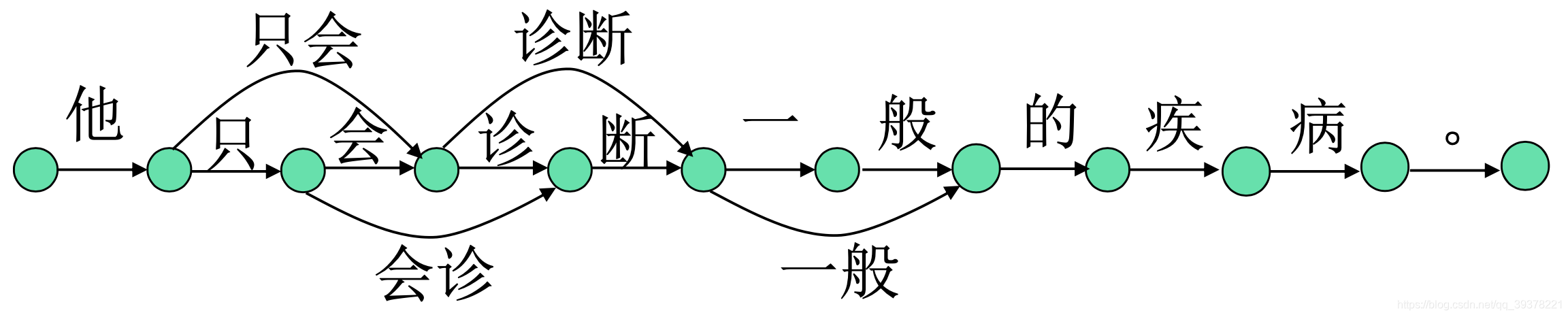
- 输出候选:(a)他/只会/诊断/一般/的/疾病/。(词个数为7)(b)他/只/会诊/断/一般/的/疾病/。(词个数为8)
- 最终结果:他/只会/诊断/一般/的/疾病/。
但是如果输入字串:“他说的确实在理”。通过算法也会得出两种候选:(a)他/说/的/确实/在理/。(b) 他/说/的确/实在/理/。 这两种情况的词数都是6,系统无法做出正确性判断。
2.3 优缺点
优点:
- 切分原则符合汉语自身规律;
- 需要的语言资源(词表)也不多。
弱点:
- 对许多歧义字段难以区分,最短路径有多条时,选择最终的输出结果缺乏应有的标准;
- 字串长度较大和选取的最短路径数增大时,长度相同的路径数急剧增加,选择最终正确的结果困难越来越大。
3 基于语言模型的分词方法
方法描述:设对于待切分的句子
S
S
S,
W
=
w
1
w
2
⋯
w
k
(
1
≤
k
≤
n
)
W=w_1w_2\cdots w_k(1\le k \le n)
W=w1w2⋯wk(1≤k≤n)是一种可能的切分。则有:
W
∗
=
arg max
w
p
(
W
∣
S
)
=
arg max
w
p
(
W
)
∗
p
(
S
∣
W
)
W^*=\argmax_w p(W|S)=\argmax_w p(W)*p(S|W)
W∗=wargmaxp(W∣S)=wargmaxp(W)∗p(S∣W)
这里
p
(
W
)
p(W)
p(W)就是语言模型,
p
(
S
∣
W
)
p(S|W)
p(S∣W)就是生成模型。
优点:
- 在训练语料规模足够大和覆盖领域足够多时,可以获得较高的切分正确率。
弱点:
- 规模性能较多地依赖于训练语料的规模和质量,训练语料的规模和覆盖领域不好把握;
- 计算量较大。
4 基于HMM的分词方法
基本思想是把输入字串(句子)
S
S
S作为HMM的
μ
\mu
μ的输入;切分后的单词串
S
w
S_w
Sw作为状态的输出,即观察序列
S
w
=
w
1
w
2
⋯
w
n
(
n
≥
1
)
S_w=w_1w_2\cdots w_n(n \ge 1)
Sw=w1w2⋯wn(n≥1)。词性序列
S
c
S_c
Sc为状态序列,每个词性标记
c
i
c_i
ci对应HMM中的一个状态
q
i
q_i
qi,
S
c
=
c
1
c
2
⋯
c
n
S_c=c_1c_2\cdots c_n
Sc=c1c2⋯cn。则:
S
^
w
=
arg max
S
w
p
(
S
w
∣
μ
)
\hat S_w = \argmax_{S_w} p(S_w|\mu)
S^w=Swargmaxp(Sw∣μ)
优点:
- 在训练语料规模足够大和覆盖领域足够多时,可以获得较高的切分正确率。
弱点:
- 模型性能较多地依赖于训练语料的规模和质量,训练语料的规模和覆盖领域不好把握;
- 模型实现复杂、计算量较大。
5 由字构词(基于字标注)的分词方法
基本思想是,将分词过程看作是字的分类问题。该方法认为,每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位)。假定每个字只有4个词位:词首(B)、词中(M)、词尾(E)和单独成词(S),那么字归属一特定的词位。
该方法的重要优势在于,它能够平衡地看待词表词和未登录词的识别问题,文本中的词表词和未登录词都是用同一的字标注过程来实现的。在学习构架上,既可以不必专门强调词表词信息,也不用专门设计特定的未登录词识别模块,因此,大大地简化了分词系统的设计[黄昌宁,2006]
参考资料:《统计自然语言处理》宗成庆

















 183
183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









