









一、简述
将好的方案进行融合到YOLO中.
改进:调整了网络结构;利用多尺度特征进行对象检测,对象分类用logigtic取代了softmax。
二、新的网络结构 Darknet53
在基本的图像特征提取方面,YOLOv3采用了Darknet63(含有53个卷积层),借鉴了残差网络resnet的做法。
三、利用多尺度特征进行检测
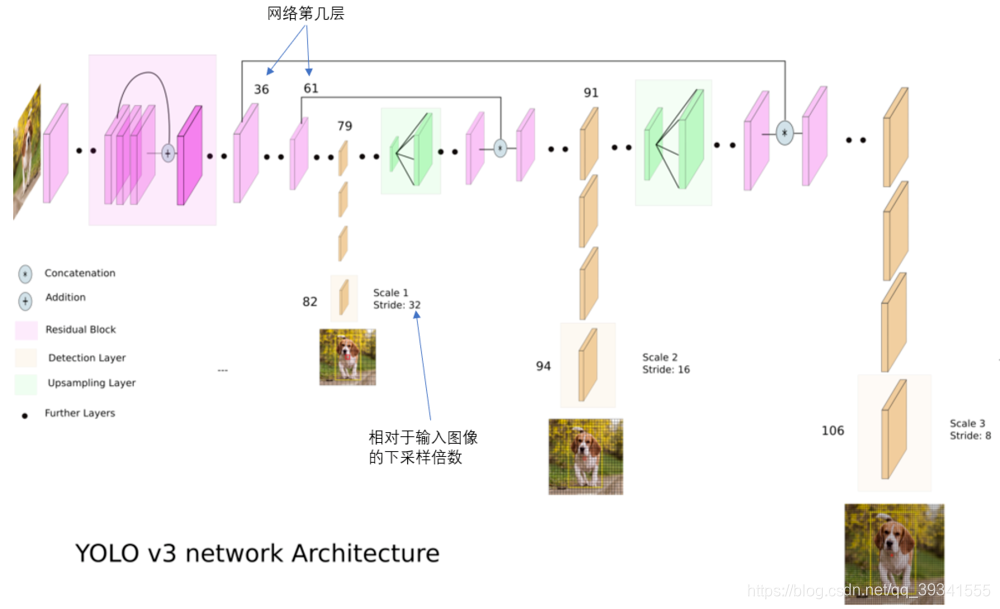
使用了3个不同尺度的卷积图来进行目标检测。
- 卷积网络在79层后,经过n个卷积层得到一种尺度的检测结果。相对输入,这个检测特征图有32倍的下采样。比如输入是416416,这个特征图就是1313了。由于下采样倍数高,特征图的感受野比较大,相应的其适合检测的目标尺寸也是大尺寸对象。
- 为了实现细粒度的检测(v2),第79层的特征图开始做上采样,然后与第61层特征图融合,这样得到了91层,较细粒度的特征图,同样经过了n个卷积层,得到相对于图像16倍下采样的特征图。它具有中等尺度的感受野,适合检测中等尺度的特征。
- 最后,第91层上采样,与第36层特征图融合,得到相对输入图像6倍下采样的特征图,它的感受野最小,适合小目标。
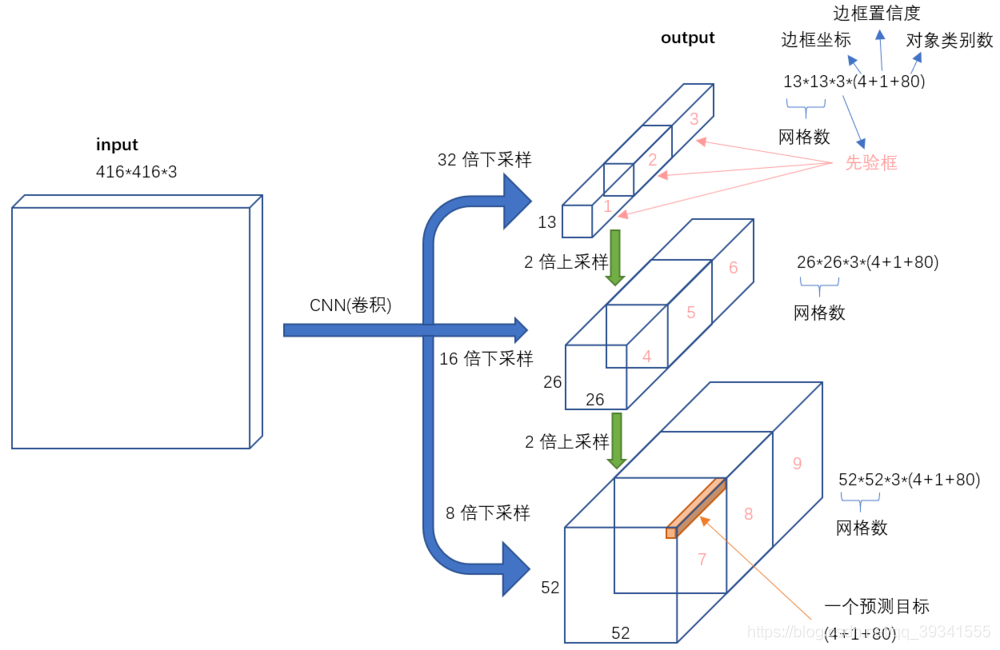
四、9种尺度的先验框(Anchor boxes)
随着检测特征图尺寸的变换,Anchor boxes尺寸也相应的调整。在YOLOv2中,采用k-mean聚类方式得到Anchor boxes尺寸大小。YOLOv3也采用这样方式,为了每一个尺寸 设计了3个anchor boxes尺寸。共聚类出9种尺寸的Anchor boxes,用于检测3种大小的目标。

五、 对象分类softmax改为logistic
预测对象类别时,不使用softmax,改为使用logistic的输出进行预测。当一个区域框中,含有多个目标时,可进行多类别预测。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









