










一、概述
RPN(region proposal net),该网络与检测网络共享整个图像的卷积特征。RPN是一个全卷积网络,可以同时在每个位置预测目标边界和目标分数。RPN通过端到端的训练,可以生成高质量的region proposals.
Faster RCNN,由两个模块组成。第一个模块是region proposal net,深度全卷积网络。第二个模块是使用proposal的Fast RCNN检测器。
二、RPN
RPN以任意大小的图像作为输入,输出一组矩阵的object proposals,每个proposal都有一个目标得分,使用的是全卷积网络。
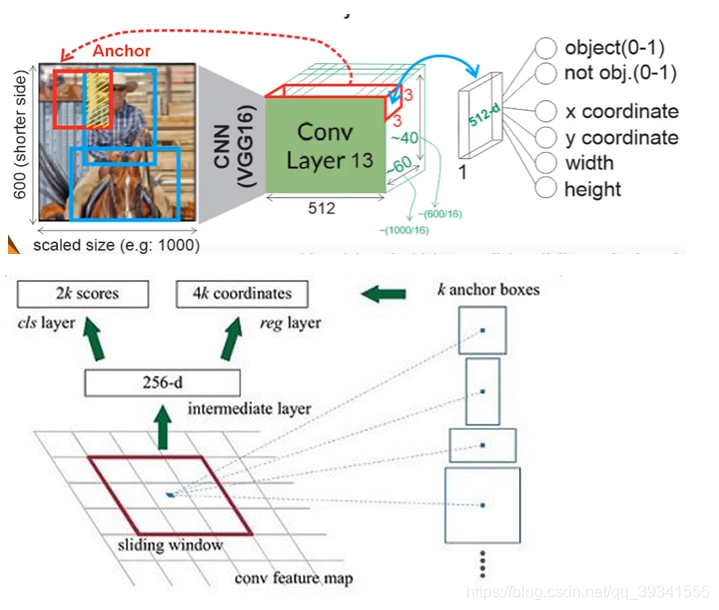
为了生成region proposal,在最后的共享卷积层输出的feature map上以n*n空间窗口作为输入。每个滑动窗口映射到一个低维特征(zf-256、vgg512),这个特征被输入到两个兄弟全连接(边框回归器reg和边框分类层cls)。
-
Anchors
在滑动窗口位置,可同时预测多个region proposal,其中每个位置生成的proposals的最大数目表示为k,因此,reg层具有4K个输出,编码k的边框坐标,即(x,y,w,h)* k个。cls层输出2k个分数,估计每个proposal是目标或不是目标的概率。
k个proposals是根据anchors的参数来定义的。anchors位于滑动窗口的中心,并与尺寸和长宽比相关。在默认情况下,使用了3个尺寸和3个宽高比,即每个滑动窗口位置可以产生K = 9个anchor。对于一个feature map为W*H,那么总共有 9 * W * H个anchor。
对于anchor,就可以理解为,它是在特征图上对每个特征点,生成k个(9)region proposal。其内部包含的特征,就是框中目标的特征。 -
平移不变性 如果图像中平移目标,proposal也相应平移。
-
多尺寸Anchor
多尺寸预测有两种流行的方法,第一种是图像/特征金字塔(FP),对图像在多尺寸上进行缩放,并针对每个尺寸计算feature map(耗时)。
第二种使用多尺寸的滑动窗口,使用不同大小的滤波器。
anchors金字塔,使用单一尺寸的图像和feature map,并使用单一尺寸的滤波器,通过不同比例(2:1,1:1,1:2)和不同尺寸(128,256,512)。
-
RPN训练
RPN的训练,每一个anchor分配一个二值类别标签。(正/负)
pos: 与ground-trash具有高交并比的anchor,即 与gt iou > 0.7的anchor,标1.
neg:一个anchor与所有gt iou < 0.3,标为0.每个mini-batch数据都是从单张图像中产生的正负anchor,如果使用所有的anchor 的损失函数,会使得偏向负样本,所有,在原图中随机采样256个anchors,计算一个mini-batch的损失,其中采样的正负比1:1.
三、交替训练
四步训练(整个cnn提取特征过程是共享的)
- 训练RPN,通过预训练模型初始化,并精调。
- 使用RPN生成的proposals,用fast rcnn训练检测网络。
- 使用检测网络,初始化RPN,固定共享的卷积层,只对RPN特有的层进行精调。
- 保持共享卷积层固定,只对fast rcnn的独有层精调。
四、细节
使用单尺寸图像训练和测试RPN 和 fast rcnn。缩放图像,使得最短边=600,在重新缩放的图像上,最后卷积层上(zf,vgg)的感受野是16像素。(小感受野也可能提高精度)。
对于anchor,使用了3种尺寸(128 = 16 * 8,256=16 * 16,512=16 * 32)即感受野的8倍,16倍,32倍,以及3种长宽比,1:2,1:1,2:1。这些超参数并不是针对特点数据专门选择的。对于生成的proposals,那些跨越图像边界的proposal(anchor),在训练时,会忽略掉。在预测时,会将这些裁剪到图像边界。
一些RPN proposal 相互高度重叠,出现多余的冗余。使用cls分数进行NMS,阈值设为0.7,将超过的全部去除。使得每张图像最终留下大约2k个region proposal,然后使用留下的2k个RPN proposal,对fast rcnn进行训练。但在测试时val(不是预测),评估不同数量的proposals(300).
学习到的RPN提高了region proposal的质量,也提高了整体的目标检测的精度。
五、总结
RCNN,Fast RCNN,Faster RCNN比较
RCNN: 首先生成约2k个region proposal,针对每个region proposal生成feature map,通过feature map分别训练类别分类器和边框回归。
Fast RCNN:首先生成约2k个region proposal,针对整张图进行训练feature map,将所有的region proposal投射到feature map上,形成proposal feature map,使用proposal feature map 一站式训练分类和边框回归。
Faster RCNN:针对整张图生成feature map,使用feature map通过RPN生成约2K个region proposals,将所有region proposal投射到feature map上形成proposal feature map,使用proposal feature map 一站式训练分类器和图像边框回归。
RPN
用意:旨在通过conv layer的feature map,训练出含有目标的region proposal。
实现步骤:
- CNN最后一层卷积层,输出的map为60 * 40 * 512的feature map上,做3 * 3卷积,对于60 * 40的每个特征点,找到其感受野在原图上的中心位置,并覆盖9个anchor,最终会生成2w个anchor(60 * 40 * 9).
- 去除超出原图图像区域的anchor,剩余约6k个anchors。
- 对于前景最高得分Anchor,通过NMS删除与其IOU > 0.7的anchor,剩余约2k个anchors。
- 训练:
网络自变量:2000个anchor样本,512维feature
网络因变量:anchor中有无目标,anchor位置(x,y,w,h)中心点位置,宽,高
正样本:与gt IOU > 0.7,
负样本:与gt IOU < 0.3
batsh_size:256,128正-128负,正样本少于128,负样本来补全(满256)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









