







 本文对比分析了HashSet和TreeSet两种集合类的实现原理、存储方式、序列化机制、克隆机制、保证元素相同的方式及元素顺序。深入探讨了它们在Java编程中的应用差异。
本文对比分析了HashSet和TreeSet两种集合类的实现原理、存储方式、序列化机制、克隆机制、保证元素相同的方式及元素顺序。深入探讨了它们在Java编程中的应用差异。
一.继承实现关系
都继承了
AbstractSet
都实现了
Cloneable, java.io.Serializable
二.存储方式
HashSet:

TreeSet:

三.序列化机制
两者内部都有readObject和writeObject方法
源码中两者都有一个不同的backing:
自己写序列化的原因也是因为避免序列化了缓存中没有实际存储元素的空间
四.克隆机制
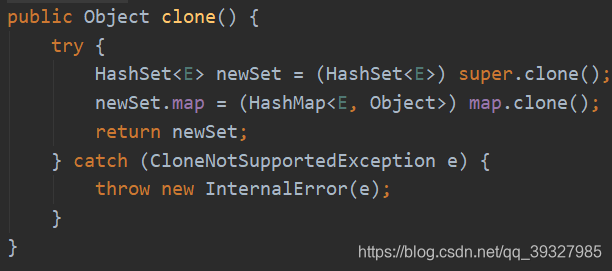
HashSet:将Set强转为Map,调用的是Object中的clone,属于浅拷贝,如果要实现深拷贝,可以序列化或者遍历HashSet中的每个值然后一个个的clone并且重写目标类的clone方法。
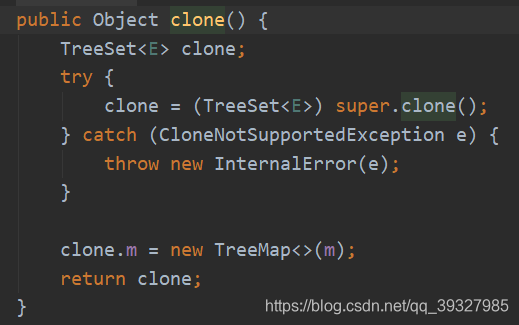
TreeSet:也是浅拷贝差不多。
五.保证元素相同的方式
HashSet:通过对象的hashCode和equals方法来完成对象唯一性的判断。
如果对象的hashCode值不同,则不用判断equals方法,就直接存到HashSet中。
如果对象的hashCode值相同,需要用equals方法进行比较,如果结果为true,则视为相同元素,不存,如果结果为false,视为不同元素,进行存储,因为哈希码已被占用,所以采用链接的方式链接。
TreeSet:根据比较方法的返回结果是否为0,如果是0,则是相同元素,不存,如果不是0,则是不同元素,存储。

六.元素顺序
HashSet不能保证元素存储顺序,也不能在内部进行排序
TreeSet:
1.自然排序:
1.让元素自身具备比较性,
2.实现Compareable接口,覆盖其CompareTo方法
2.自然排序:
1.当元素自身不具备比较性时,或者具备的比较性不是所需要的。
2.这时就要让集合自身具备比较性,在初始化时,就有了比较方式。

















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









