




前言
在学习elasticsearch的时候,很早之前就查过filter和query的不同。那时候,看来之后也没有完全理解。今天抽空整理一下。做一下记录。
1. query与filter
1.1 关注点
- query查询关注查询语句中的条件是否被包含在所要查询的文档。有一个词包含即时符合条件。
- filter查询关注查询语句和所要查询的文档内容是否匹配。只有完全匹配才可以
1.2 相关度得分
- query查询对结果有相关度评分机制,并且按照分数进行排序。
- filter查询没有评分机制
1.3 性能比较
- query查询需要计算分数,并且需要排序。因此,性能不如filter。
- filter查询有bitset和caching机制。更快。。。
2 filter查询
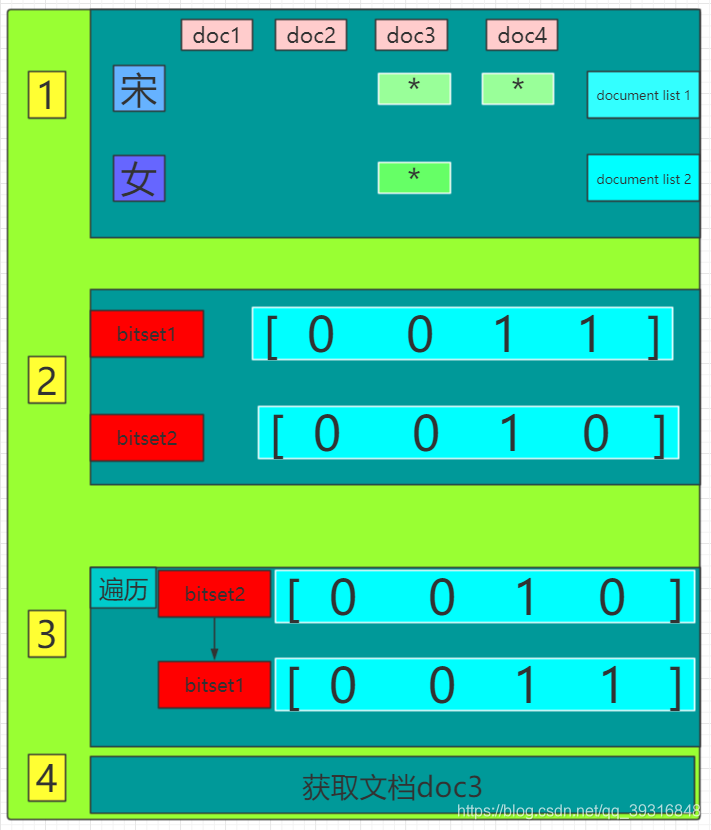
2.1 filter的bitset机制
-
fileter在过滤检索过程中,会在倒排索引中查找检索串,获取
document list -
为每个在倒排索引中搜索到的结果,构建一个
bitset(一个二进制数组),数组每个元素都是0或1,用来标识一个doc对一个filter条件是否匹配,如果匹配就是1,不匹配就是0(为什么要这样做? 答:尽可能用简单的数据结构去实现复杂的功能,可以节省内存空间,提升性能) -
遍历每个过滤条件对应的
bitset,优先从最稀疏(先过滤掉尽可能多的数据)的开始搜索,查找满足所有条件的document
以3.3.2进行说明
图解说明:
2.2 filter的caching机制
-
caching bitset,在最近的256个filter中,有某个filter超过了一定的次数,次数不固定,就会自动缓存这个filter对应的bitset
-
segment(上半季),filter针对小segment获取到的结果,可以不缓存,segment记录数<1000,或者segment大小<index总大小的3%
-
segment数据量很小,此时哪怕是扫描也很快;segment会在后台自动合并,小segment很快就会跟其他小segment合并成大segment,此时就缓存也没有什么意义,segment很快就消失了
-
如果document有新增或修改,那么cached bitset会被自动更新
-
以后只要是有相同的filter条件的,会直接来使用这个过滤条件对应的cached bitset
3. 小示例
3.1 查询背景
使用诗词查询,将诗词存入elasticsearch中,字段包含诗人姓名,朝代,性别,诗词
使用kibana开发工具(也可以自己使用curl、postman之类工具)
POST /poem/doc/_bulk
{ "index": { "_id": 1 }}
{"poet":"王维","dynasty":"唐","sex":"男", "message" : "红豆生南国,春来发几枝。愿君多采撷,此物最相思"}
{ "index": { "_id": 2 }}
{"poet":"李白","dynasty":"唐", "sex":"男","message" : "床前明月光,疑是地上霜。举头望明月,低头思故乡"}
{ "index": { "_id": 3 }}
{"poet":"李清照","dynasty":"宋", "sex":"女","message" : "生当做人杰,死亦为鬼雄。至今思项羽,不肯过江东"}
{ "index": { "_id": 4 }}
{"poet":"苏轼","dynasty":"宋", "sex":"男","message" : "十年生死两茫茫,不思量,自难忘。千里孤坟,无处话凄凉。纵使相逢应不识,尘满面,鬓如霜。"}
3.2 使用query查询
3.2.1 查询诗集中包含生死的文档
GET poem/_search
{
"query": {
"match": {
"message": "生死"
}
}
}
结果:

查询语句会查询message中包含生或死的诗句
3.2.2 查询性别中包含女的文档
GET poem/_search
{
"query": {
"match": {
"sex": "女"
}
}
}
结果:

3.2.3 小结
- 可以看出query查询关注的点,是文档是否包含要查询的内容
- 查询结果返回有相关度评分,并按照相关度进行排序
3.3 使用filter查询
3.3.1 查询文档中朝代是唐的文档
GET poem/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"dynasty": "唐"
}
}
}
}
}
结果:

3.3.2 查询文档中朝代是宋并且性别是女的文档
GET poem/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"must": [
{
"term": {
"dynasty": "宋"
}
},
{
"term": {
"sex": "女"
}
}
]
}
}
}
}
}
结果:

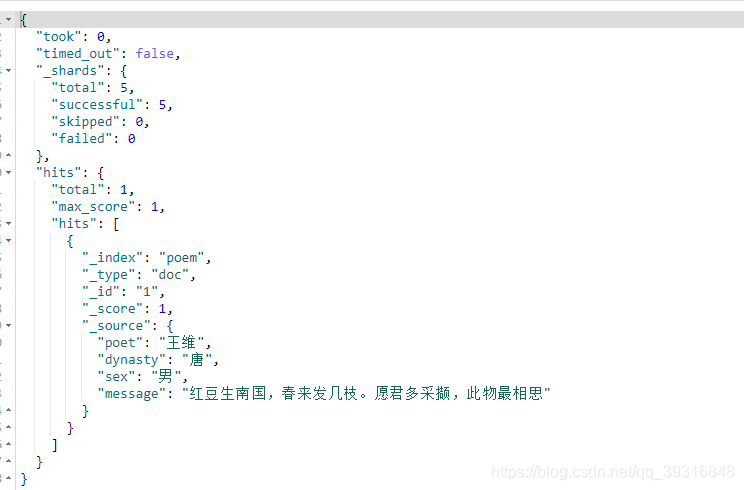
3.3.3 查询文档中诗集文字
GET poem/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"message.keyword": "红豆生南国,春来发几枝。愿君多采撷,此物最相思"
}
}
}
}
}
结果:
3.3.4 小结
- filter查询没有相关度评分,不进行排名(数据量小看不出caching的作用,有兴趣的可以自己尝试哟)
- filter更适合精确匹配,term查询字段必须是keyword,诗词的message的mapping默认是text(分词)

















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









