




 本文介绍了使用Python3.7和Selenium库来获取网页元素的属性值和文本内容,特别是通过XPath选择器。以www.hao123.com网站的'七日天气'链接为例,详细阐述了定位元素、提取属性和文本的方法,包括XPath的使用和Firefox的XPath插件辅助。文章提供了相关XPath教程链接以及Python代码示例。
本文介绍了使用Python3.7和Selenium库来获取网页元素的属性值和文本内容,特别是通过XPath选择器。以www.hao123.com网站的'七日天气'链接为例,详细阐述了定位元素、提取属性和文本的方法,包括XPath的使用和Firefox的XPath插件辅助。文章提供了相关XPath教程链接以及Python代码示例。
【工具安装】
https://blog.youkuaiyun.com/qq_39295735/article/details/84558545
【xpath用法】
http://www.cnblogs.com/hhh5460/p/5079465.html
https://www.cnblogs.com/hanmk/p/8997786.html
xpath获取同级元素 http://www.cnblogs.com/VseYoung/p/8686383.html
【测试步骤】
1、用www.hao123.com这个门户网站进行测试,如何用xpath方便提起标签中的属性值和标签的文本内容。测试对象是首页上方的“七日天气”这个链接地址和文字。
首先通过firefox的xpath插件先定位到该标签的相关信息,操作顺序见截图标注。
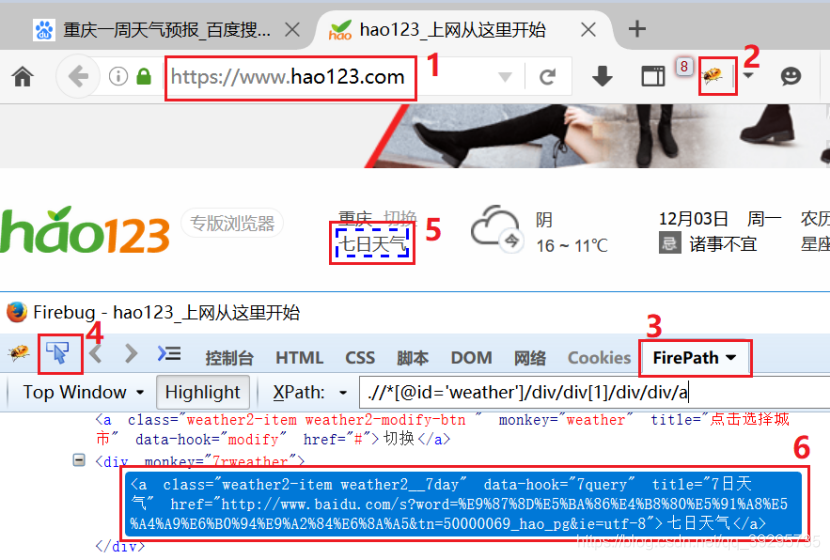
2、提取跳转链接的xpath表达式是:
<1> 定位到这个标签:xpath = '//a[text()="七日天气"]'
<2> 获取标签中的属性值和文本:content.get_attribute('href') 和 content.text

【python代码】
#!/usr/bin/python3
#-*- coding: utf-8 -*-
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
driver = webdriver.Firefox()
driver.get("https://www.hao123.com/")
content = WebDriverWait(driver, 30).until(lambda x:x.find_element_by_xpath('//a[text()="七日天气"]'))
print(content.get_attribute('href'))
print(content.text)

















 1273
1273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









