







 这篇论文笔记介绍了中山大学学者如何运用深度强化学习(DRL)进行多标签图像识别。网络结构包括VGG16卷积层,通过LSTM选择关注区域并进行分类。在强化学习框架下,agent根据state选择action,调整attention并获取reward。最终通过多次迭代,融合各区域得分确定标签分布。
这篇论文笔记介绍了中山大学学者如何运用深度强化学习(DRL)进行多标签图像识别。网络结构包括VGG16卷积层,通过LSTM选择关注区域并进行分类。在强化学习框架下,agent根据state选择action,调整attention并获取reward。最终通过多次迭代,融合各区域得分确定标签分布。
是中山大学的学者所做的工作。
1.要做的事情
使用DRL做多标签的图像识别‘
2.网络结构
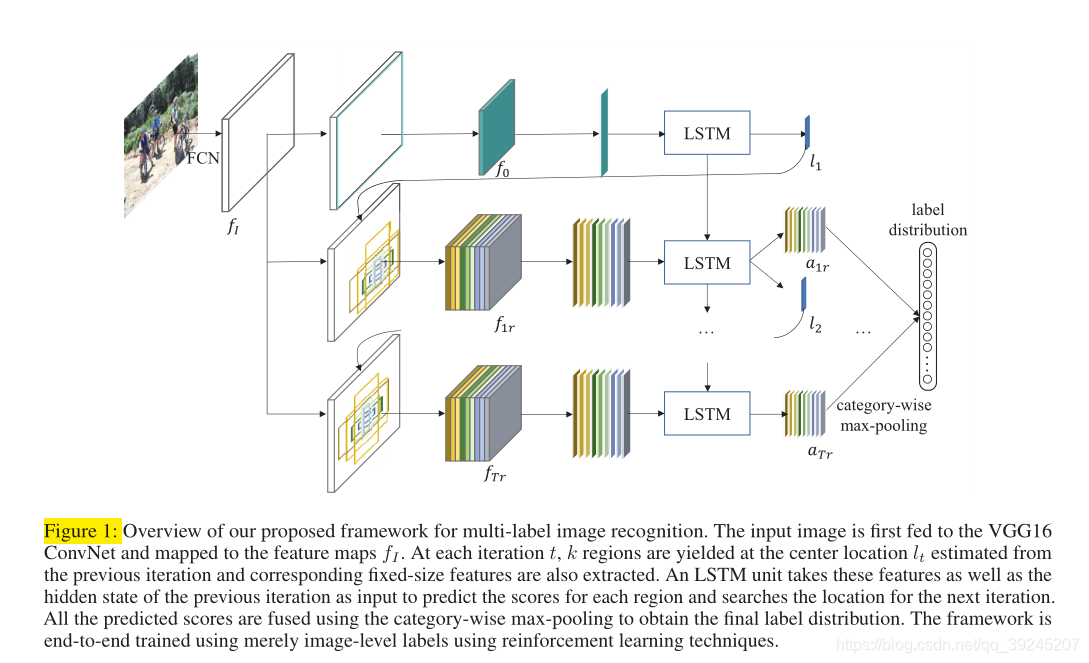
states:current region 的特征;
reward:分类的正确与否;
action:寻找attention local,且在attention区域进行分类;
3. 过程
首先,将原始图片输入进一个VGG16的卷积层的网络(如下图),得到feature map ![]() 。
。
然后经过全连层后,随机给定一个中心坐标,输入到f0中,得到与location有关的图,输入到LSTM中,得到 l 和hidden layer。如下图所示:
LSTM的输出是location,其隐藏层的输出是作为下一个LSTM的输入,air是预测每个region的分类的得分。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









