







这是一篇用多任务模型预测CVR的文章。
主要解决两个问题:
1、样本偏差(SSB)
2、数据稀疏(DS)
一、背景
之前的解决方法:
1、 建立不同特征的的分层估计,并结合逻辑回归模型视图解决数据稀疏问题;但是,依赖于先验知识来构建层次结构,这在数千万用户和项目的推荐系统中很难应用。
2、过采样方法:过采样方法复制了很少罕见样本,有助于减轻数据的稀疏性,但对采样率敏感。
3、AMAN:采用随机抽样策略选择未点击的曝光作为负样本。它可以通过引入未观测到的例子在一定程度上消除SSB问题,但结果会低估CVR的预测。
4、无偏方法:过拒绝抽样拟合观测数据的真实基础分布,解决了CTR建模中的SSB问题。然而,当采用剔除概率的除法对样本进行加权时,可能会遇到数值不稳定的问题。
二、创新点
ESSM模型的创新点主要是通过多任务学习以及共享Embedding来解决CVR预估的困难性。
从新的角度考虑CVR问题,考虑到了用户行为的顺序模式。
三、模型
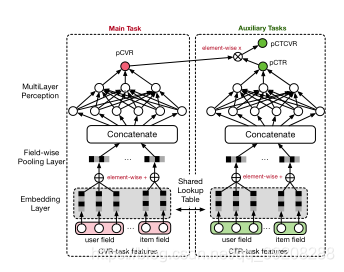
公式梳理:
1、PCTCVR的计算方式:
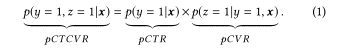
2、公式(1)的转化:
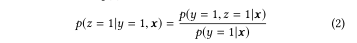
3、损失函数:
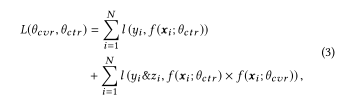
因为损失函数里边有θ(cvr),所以也相当于间接训练了CVR的参数
实验评估指标:
AUC:衡量二分类模型优劣的一种评价指标,越接近1,真实性越高。
四、总结
这篇文章利用多任务模型来预测CVR,解决了样本偏差和数据稀疏问题。对于样本偏差问题,采用共享间接训练CVR的方式解决,使其在全样本空间训练;对于数据稀疏的问题,将CTR的数据与CVR的数据共享,因此数据稀疏问题的得到解决。CTCVR可以通过公式(1)计算得出,进而转化成公式(2)。模型训练方式是,先预估出CTCVR再迂回训练处CVR。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









