







一、TCP/UDP:
同:
都属于传输层协议,传输层协议只关心传输数据,而不关心数据的封装
异:
1、TCP是可靠性传输协议,点对点的传输,有连接状态,可能会发生粘包和拆包
2、UPD不可靠,广播性质的传输,无连接状态,不会发生粘包和拆包
为什么:
1、可靠性:
TCP是基于流来传输的,发送端发送数据,会先将数据发送到系统内核,
再通过网络发送到接收端内核,接收端收到后,会发送ack到发送端,
发送端收到后才会情况内核缓存。
而UDP发送到接收端之后,没有确认机制,直接情况内核缓存,可能会数据丢失。
2、粘包和拆包:
发送端粘包:
TCP协议,有个ng优化算法,间隔时间短,数据量小的包会合并后发送
这样就造成了多个数据包收尾相连,也就是所谓的粘包
接收端粘包:
接收方接收速度低于发送端发送数据的速度,下次接收的时候,就会从缓存区去
取上次遗留的数据,导致粘包。
总结:
实际上tcp就没有数据包这个概念,tcp是基于流传输的。
所谓的粘包,就是接收端不知道发送端每次发送多少kb的数据,
按照自己设定的频率来读取,
可能就会发生这次读取不完的数据,还留在缓存区,
下次按照固定的频率读取的时候,会读取一部分
缓存区的遗留数据,一部分新数据。
如果这些数据是有数据结构的,那么肯定就会出问题。
解决办法(拆包):
发送端发送数据的时候,加一个数据头,规定每次发送多少字节
接收端读取的时候,就按照这个字节数来区分。
或者在每段数据接收后,加上一个特殊字符,接收端用这个字符来
区分。
二、Socket
Socket属于抽象层,位于应用层和传输层之间。
实际上就是,我们要使用tcp和udp,就通过socket来实现。
socket属于一种特殊的文件,网络套接字(发送端和接收端的ip+端口+连接协议组合)
大概步骤:
BIO方式:
1、服务端通过serverSocket监听对象,绑定具体的ip加端口
2、客户端通过Socket连接具体的ip加端口
3、 服务端监听到了之后,通过serverSocket.accpet创建一个和客户端
对应的Socket,就由这个Socket和客户端进行相互读写。
4、客户端的socket.send发送,服务端的socket.read
5、accpet(创建对应连接)和read是阻塞的。也就是说在服务器启动之后,
accpet没有监听到客户端连接的时候,服务器端的socket程序是阻塞
(不会往下执行),连接上了但是客户端没有发送数据,又会在read这里阻塞。
这种阻塞IO,如果有多个客户端要进行连接,就只有通过多线程的方式。
但是一个连接一个线程,太浪费资源了,因为一般大部分连接都处于空闲
状态,没有进行收发数据。
所以有没有什么办法单线程实现socket非阻塞呢?
NIO方式:
核心思想:
一个list,专门装Socket对象,对这个装socket的list进行轮询处理,
不断的socket.read,读取到数据就进行处理。
每次serverSocket.accpet,监听到有客户端连接,就创建一个socket对象,
将这个对象设置为非阻塞。
然后将这个对象加入到list里面。
这样每次客户端连接过来,都会到list里面,然后轮询list,这样就实现了
非阻塞IO。
但是这样做的缺点就是java程序里面要运行list轮询,
可能大部分都是无数据发送的socket对象,造成cup资源浪费。
SocketChanel:
所以java提供了一套nio的api,提供SocketChanel获取到的对象可以设置
为非阻塞,然后通过Selector将之前的list交给操作系统去轮询。
基础概念
1、Channel(通道):
比如传统IO中的Stream
(单向的,InputStream只能读,OutputStream只能写),
Channel是双向的
通过ServerSocketChanel监听客户端发起的TCP连接
SocketChannel以TCP来向网络连接的两端读写数据
DatagramChannel以UDP协议来向网络连接的两端读写数据
FileChannel从文件读或者向文件写入数据
2、Buffer(缓冲区):
NIO中所有数据的读和写都离不开Buffer
传统IO读取的数据时放在byte数组当中,
在NIO中,读取的数据只能放在Buffer中,
同样地,写入数据也是先写入到Buffer中
3、Selector:
用来轮询每个注册的Channel,一旦发现Channel有注册的事件发生,
便获取事件然后进行处理。
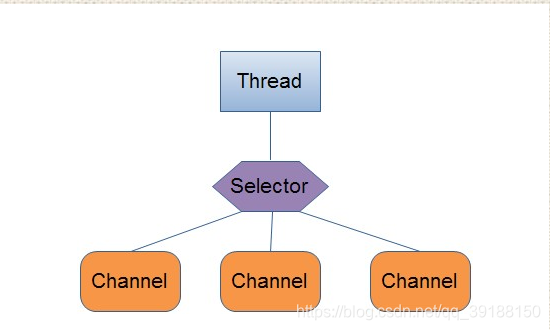
用单线程处理一个Selector,
然后通过Selector.select()方法来获取到达事件(read/write),
在获取了到达事件之后,就可以逐个地对这些事件进行响应处理。
三、select和epoll模型
Linux中有三种常见的I/O多路复用技术select、poll和epoll.
解决大量I/O操作(如网络通信)时的阻塞问题。
I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,
一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
1、select:
单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024。
套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成
调度,不管Socket是不是活跃的,都遍历一遍。这会浪费很多CPU时间。
2、poll
本质上和select没有区别,只不过他没有监控描述符大小限制,是基于链表实现的。
3、epoll
没有描述符大小限制,初始化的时候就一次性将监控的描述符copy到内核,不用每次
监控到了再copy到内核,这些描述符(read\write)是带有回调方法的,
不用轮询了,因为描述符准备就绪后,会将这些准备就绪的加入到队列,直接迭代
这些就绪的描述符。
总结差别:
select和poll本质是轮询处理,轮询所有的连接,查到了活跃的连接,就调用对应的方法。
epoll是只关注活跃的连接,而跟连接总数无关,
给套接字注册个回调函数,活跃时自动完成相关操作避免了轮询
1、表面上看epoll的性能最好,但是在连接数少并且连接都十分活跃的情况下,
select和poll的性能可能比epoll好,毕竟epoll的通知机制需要很多函数回调。
连接数少,大部分活跃的情况下,证明轮询次数少,无用循环也少,比较适合select和poll。
连接数大,大部分不活跃的情况,适合epoll
linux默认是epoll,jdk会自动选择那种方式来处理,
可以通过修改参数来变换。

















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









