







 本文介绍了解决使用curl采集网站时遇到的中文乱码问题,通过分析响应头和采用适当的编码转换方法,最终成功解决了中文显示问题。
本文介绍了解决使用curl采集网站时遇到的中文乱码问题,通过分析响应头和采用适当的编码转换方法,最终成功解决了中文显示问题。
今天在使用curl采集网站信息时输出界面中文是乱码的,于是我添加 第一行添加常规方法header("Content-Type: text/html;charset=utf-8");结果证明没有用。于是看了一下对应网站响应头。
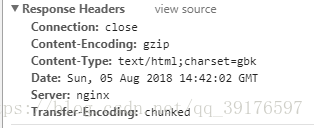
content-type是gbk,不对啊,难道要转到utf-8( ),好吧试试。
),好吧试试。
echo mb_convert_encoding($out, "utf-8", "GBK");没效果,那我用这个
echo iconv("GBK", "UTF-8", $out);,依然没效果。咦,啥情况,于是再看响应头,发现有个content-encoding,这个从字面上看好像和编码有关系,这个有啥用呢,这是一个内容编码,详见请看 HTTP 协议中的 Content-Encoding,我感觉找到原因了。搜索一番,有人讲可以使用curl_setopt($ch, CURLOPT_ENCODING,'gzip');不过我没效果,查找一番后,
function http_get($URL) {
$agent = $_SERVER['HTTP_USER_AGENT'];
if( !$agent ){
return false;
}
$c = curl_init();
curl_setopt($c, CURLOPT_RETURNTRANSFER, 1);//这个是不直接在页面输出
curl_setopt($c, CURLOPT_USERAGENT, $agent);//这个注释点好像不影响
curl_setopt($c, CURLOPT_HTTPHEADER,array('Accept-Encoding: gzip, deflate'));
curl_setopt($c, CURLOPT_ENCODING, 'gzip,deflate');//这个是解释gzip内容.................
curl_setopt($c, CURLOPT_URL, $URL);
curl_setopt($c, CURLOPT_TIMEOUT,2);
$contents = curl_exec($c);
$contents = mb_convert_encoding($contents, 'utf-8', 'GBK,UTF-8,ASCII');
$httpCode = curl_getinfo($c,CURLINFO_HTTP_CODE);
curl_close($c);
return ['data'=>$contents,'http_code'=>$httpCode];
}
















 1505
1505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









