







OK,好久不见,各位,最近挺忙,欢迎回来。
让我们开始第二章节,异常判断。
2024.5.7更新:
发现大家经常会出现一些基础的问题,这样吧,大家将问题私信给我,我会给大家一一解答,并且将整理问题及其解决方法到本教程最后一篇文章中。
目录
一 Nano Edge AI Studio 简单概述
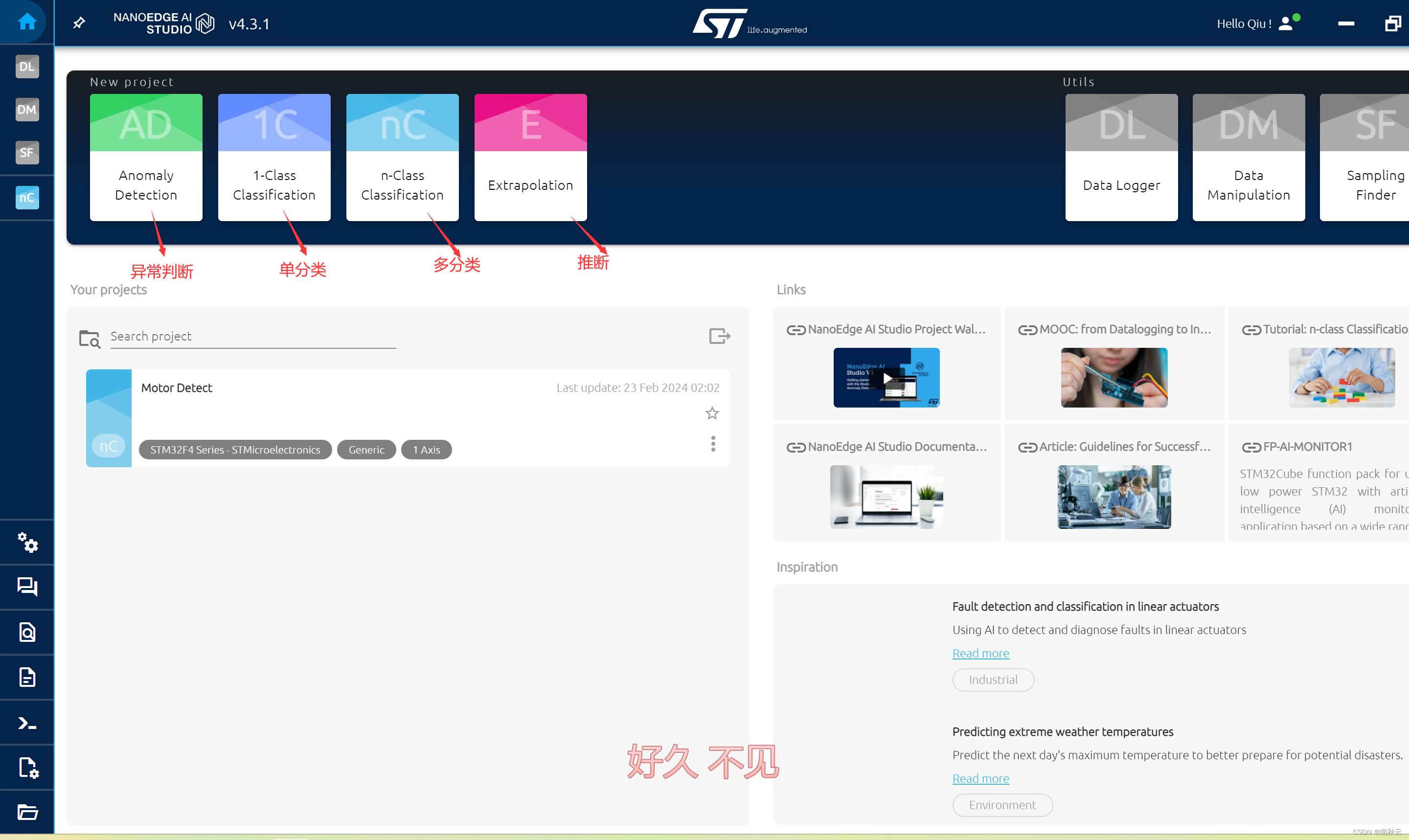
NanoEdge AI Studio主要可以实现的功能主要分为四种:
1.异常判断:异常判断的是指模型对正常数据与异常数据进行训练、学习后,生成的模型可以识别生成的边缘AI可以判断数据是正常还是错误。
这里可能有人要问,为什么不使用阈值判断,不是更简单吗?其实很简单,当数据多维时,根据阈值判断数据状态其实是个很难的设定。同时,当阈值变化后,程序里的判断只能通过手动更改进行数据判断,其实挺麻烦。而机器学习可以在MCU进行数据学习优化,避免了数据多维和阈值问题。
2.单分类:单分类的是指,将数据进行导入,进行机器学习后,可以判断出设备的正常或者异常。这里与异常判断不同的是,这里会将所有非正常的数据判断为异常,而异常判断却可以分析出当前数据与正常数据的相似度。
3.多分类:多分类是指模型可以进行多个状态的数据分析、训练,最终训练出的模型可以分析出当前数据对应各个状态数据的相似度。
4.推断:这里的意思是,模型可以对过往的数据进行分析,训练,生成的模型可以根据近期的数据近似分析出下一个时刻可能的数据。
二 异常判断
1.工程选择
2.进行工程设置
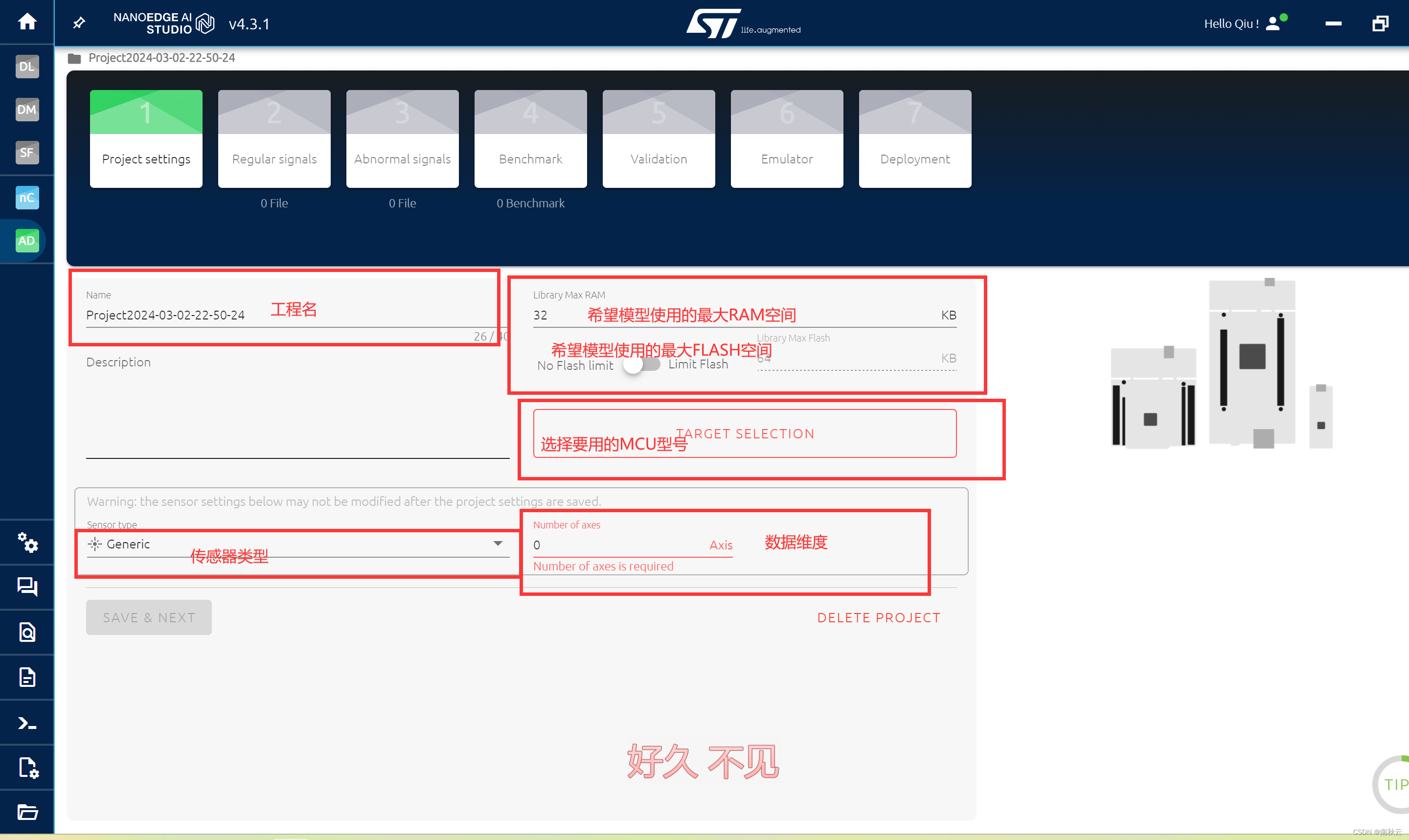
这里的工程名、RAM、FLASH大家根据需求写就好。我这里简单写一下MCU选择和数据设定。
2.1 MCU选择
点击TARGET SELECTION 进行MCU选择
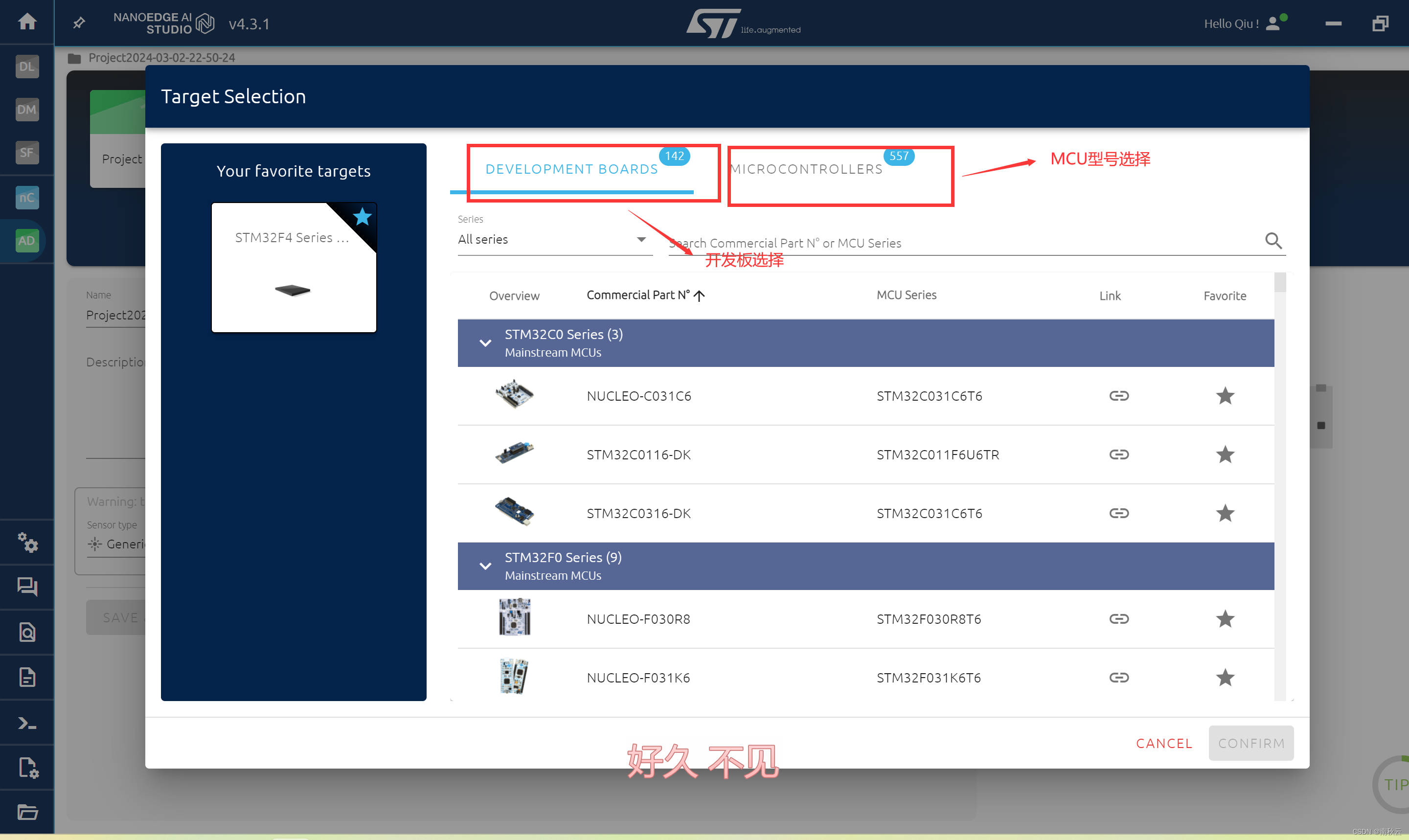
这里的话开发板是指NanoEdge AI Studio配套的开发板。
如果想要实现的模型要在开发板上跑的话就选择,想要使用自己的开发板,就选择MICROCONTROLLERS 进行MCU型号选择。
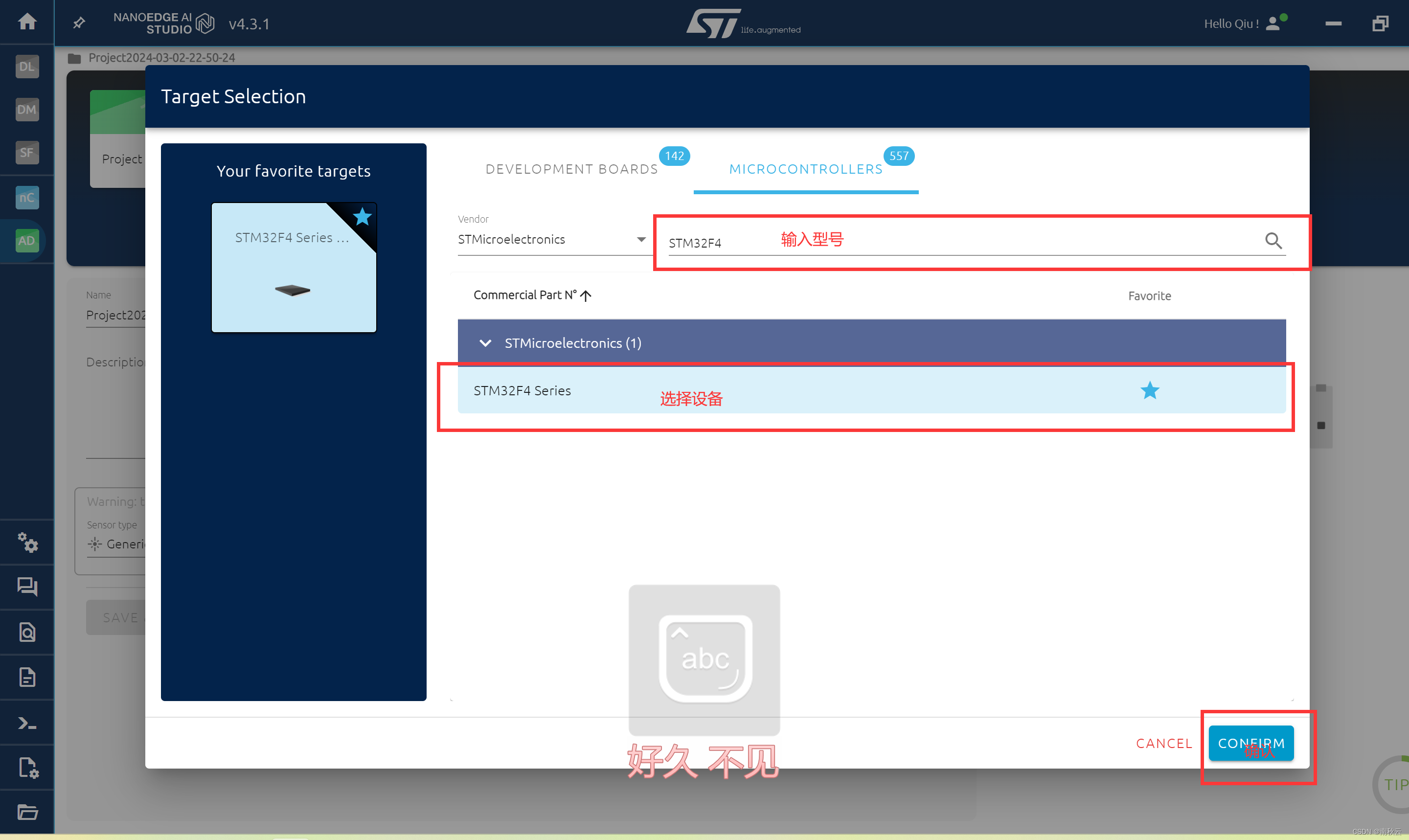
我这里选择STM32F4系列,这个工具的好处就在于支持STM全系列芯片,很棒。
选择完成后点击CONFIRM 进入下一步

2.2 数据设定
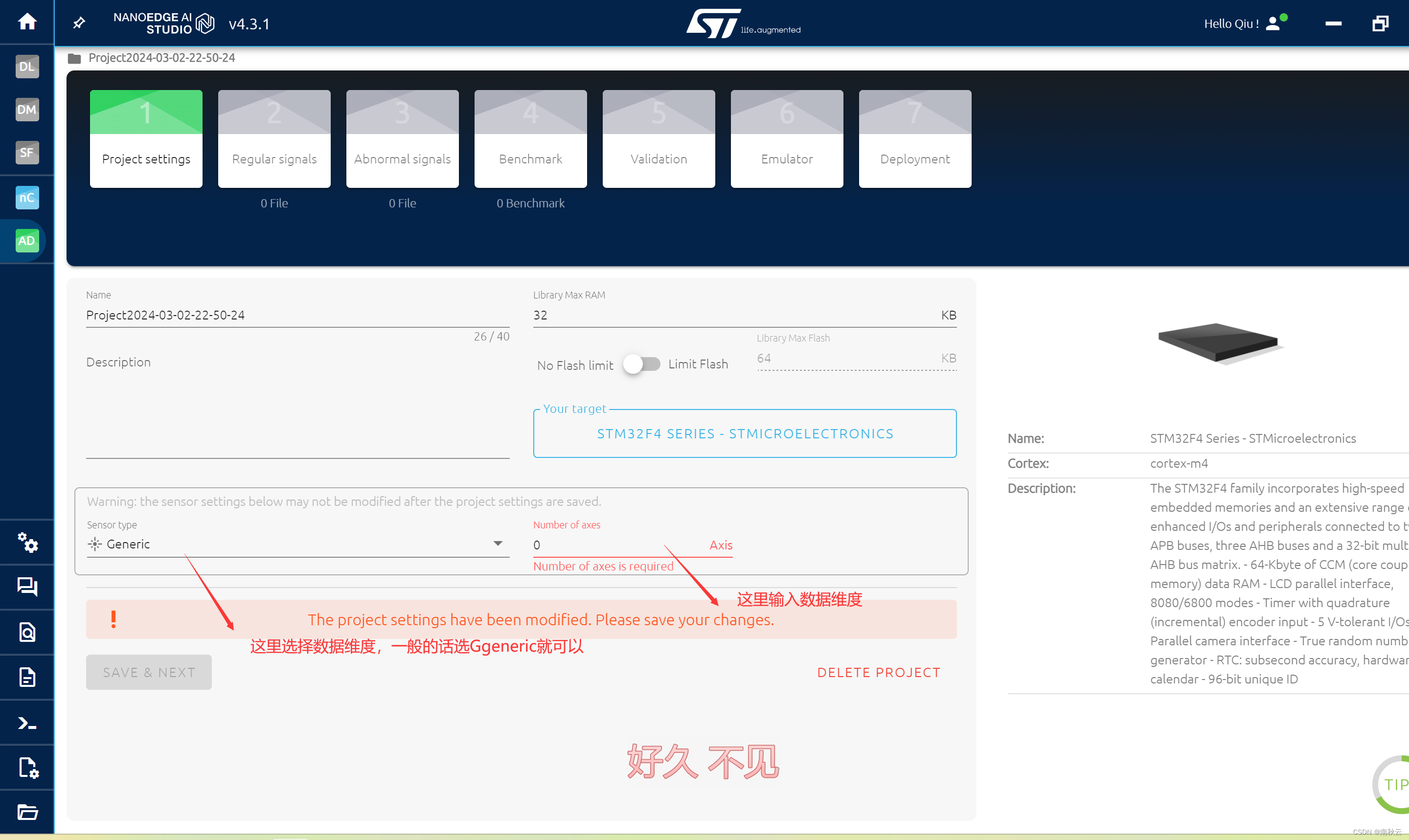
数据维度的意思是多个种类不同数据要训练,比如三轴传感器,输出X、Y、Z信息,那么我们要对X、Y、Z三维的数据进行训练,就代表着数据是三维的。
我这里选择1维,大家自己选择就好,过程都是一样的。
保存,进入下一步。
3.输入数据

这里点击ADD SIGNAL,有三种方法:
1.文件导入,就是导入CSV文件。
注意这里对于CSV文件有个要求,
(1).每行数据按照X、Y、Z进行排列。
(2).每行中每个维度的数据至少要有16个,你有一个维度,那么你只需要X1、X2、X3...X16。
假如你有3个维度:X、Y、Z,那么按照排列顺序,你必须X、Y、Z。且一行至少要有X1、Y1、Z1、X2、Y2、Z2、X3、Y3、Z3....X48、Y48、Z48.
(2).一行最多有中每个维度最多有256个。
(4).数据最好在30条以上。
2.USB导入,这个意思是比如说你有一个传感器,你可以用USB连接NE AI Studio,直接将数据导入这个软件中。就省去你去进行数据采集,前提传感器输出的数据不需要清洗。
3.不知道,也没搜到资料,才疏学浅了。
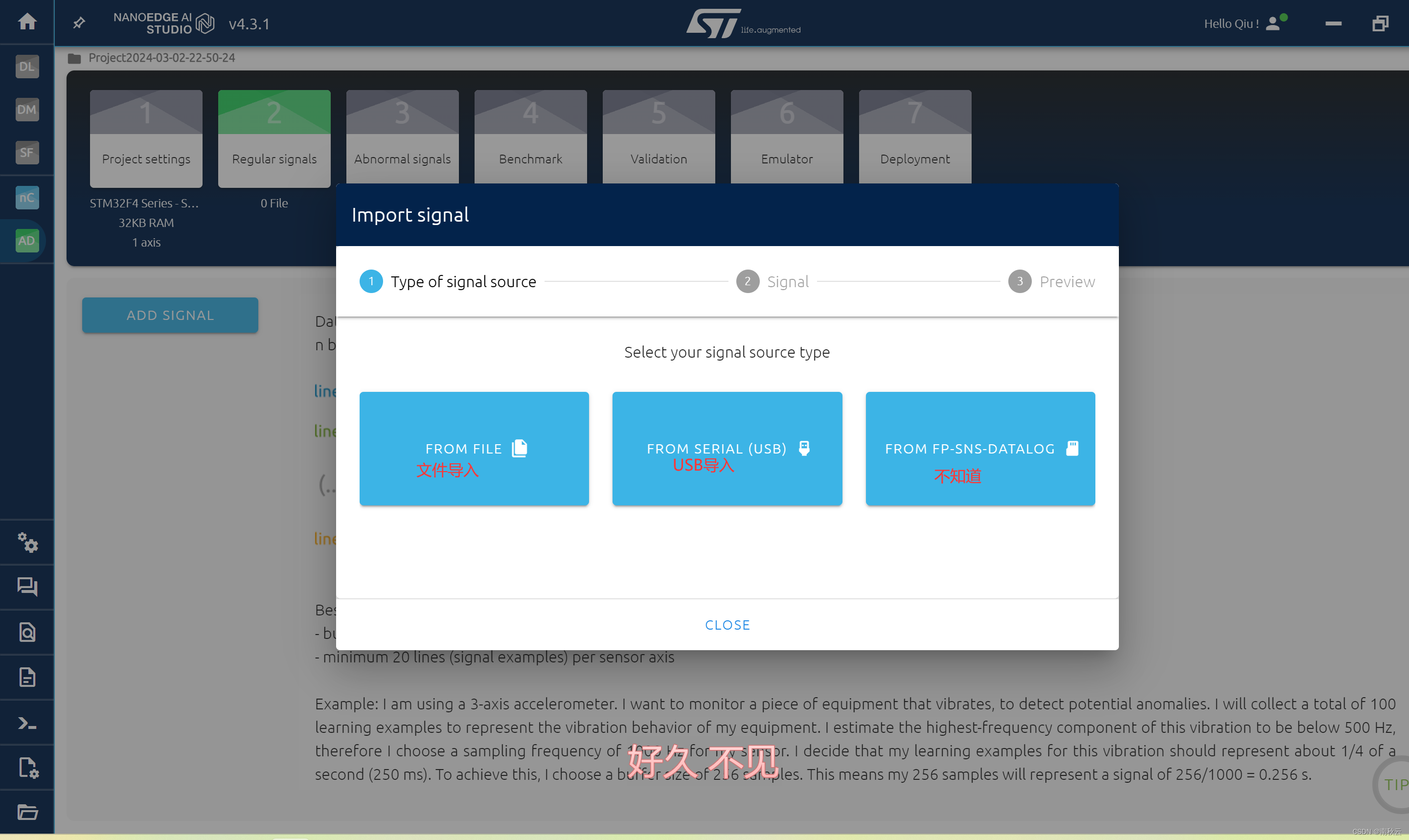
这里我们选择从文件导入
导入完成后选择CONTINUE,进行下一步,数据预览
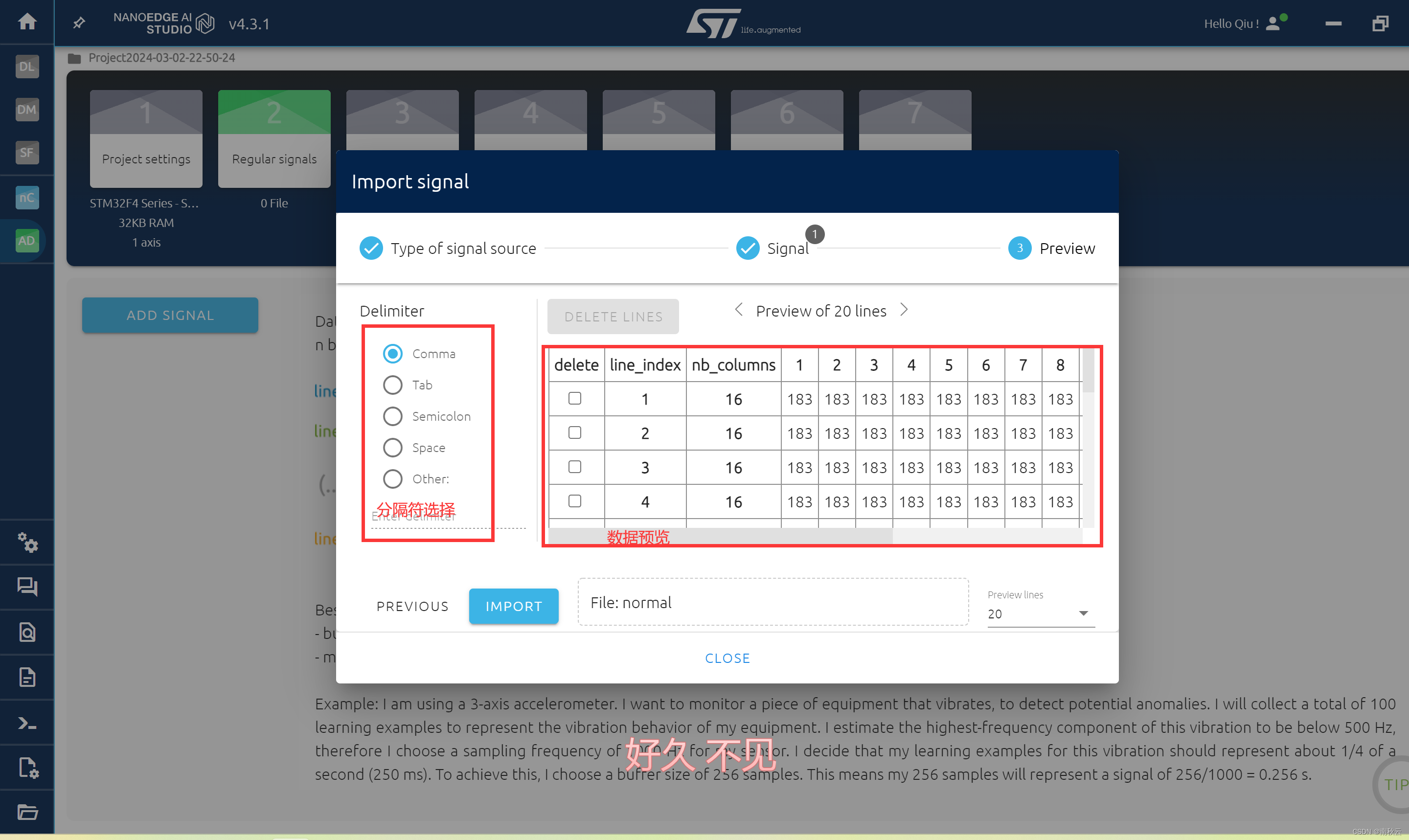
选择IMPORT进行数据导入
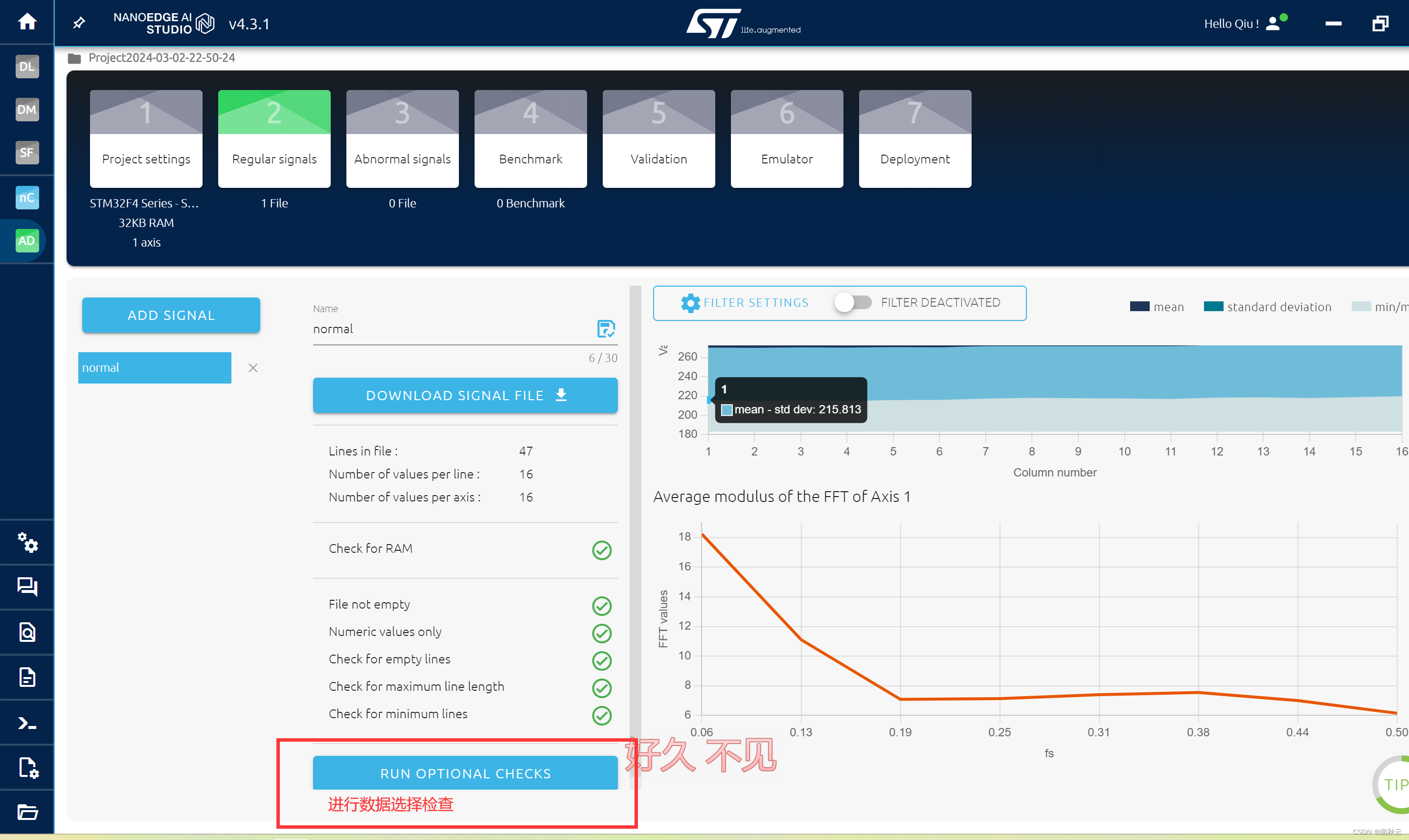
这里我们选择RUN OPTIONAL CHECKS将对数据进行检查。
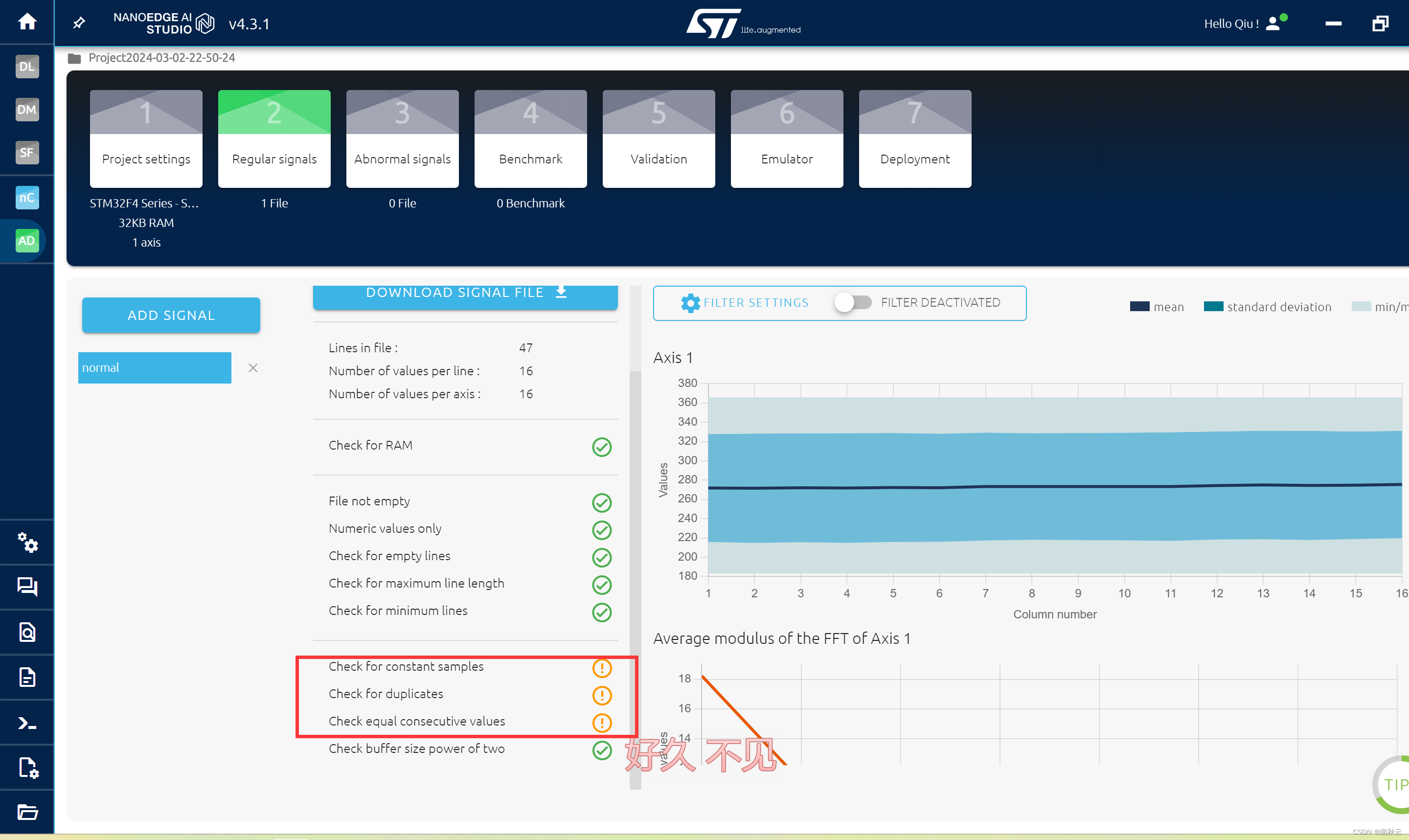
这里会提示一些数据的情况,不用太担心。
同上一步一样,这里导入异常数据。
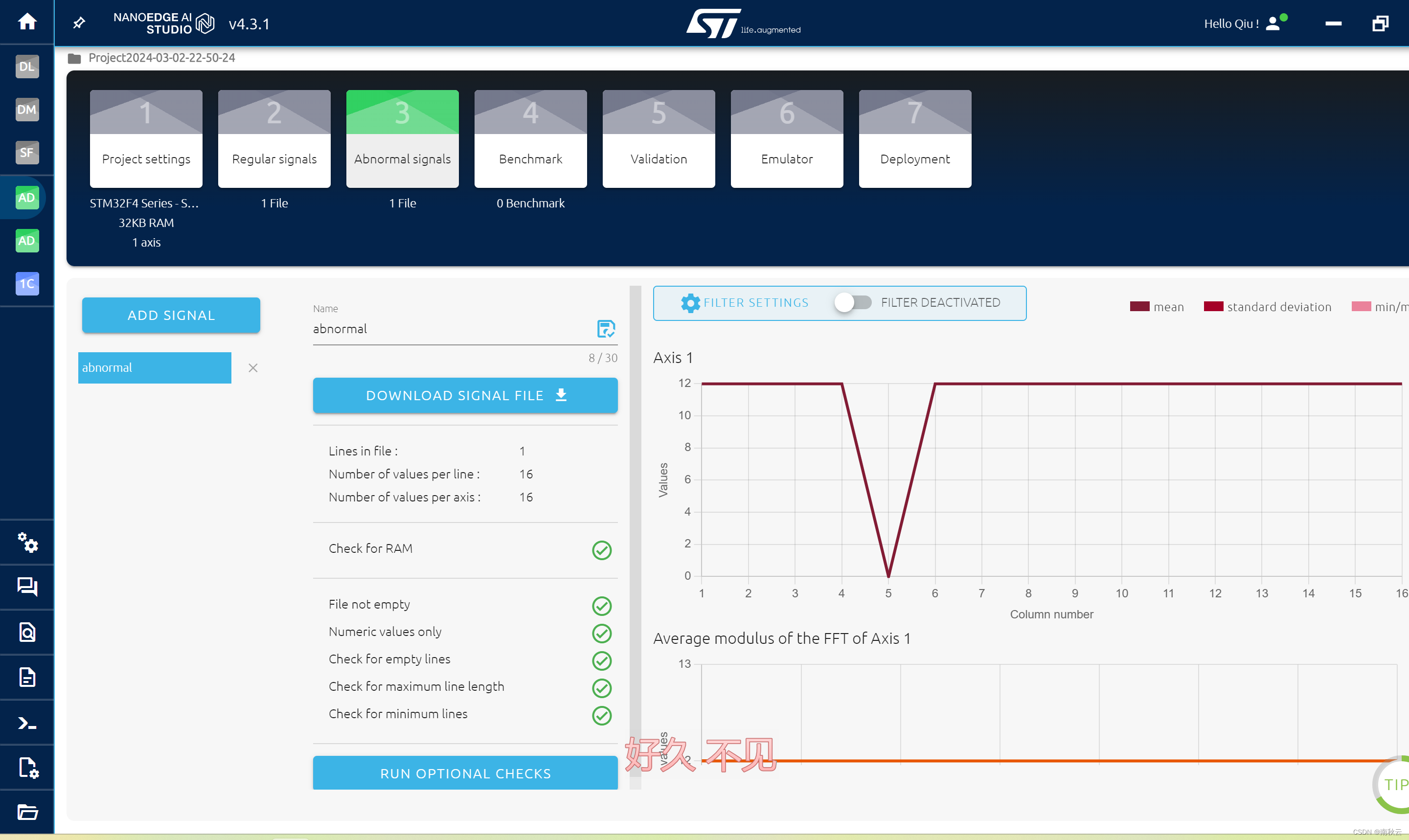
4.模型训练
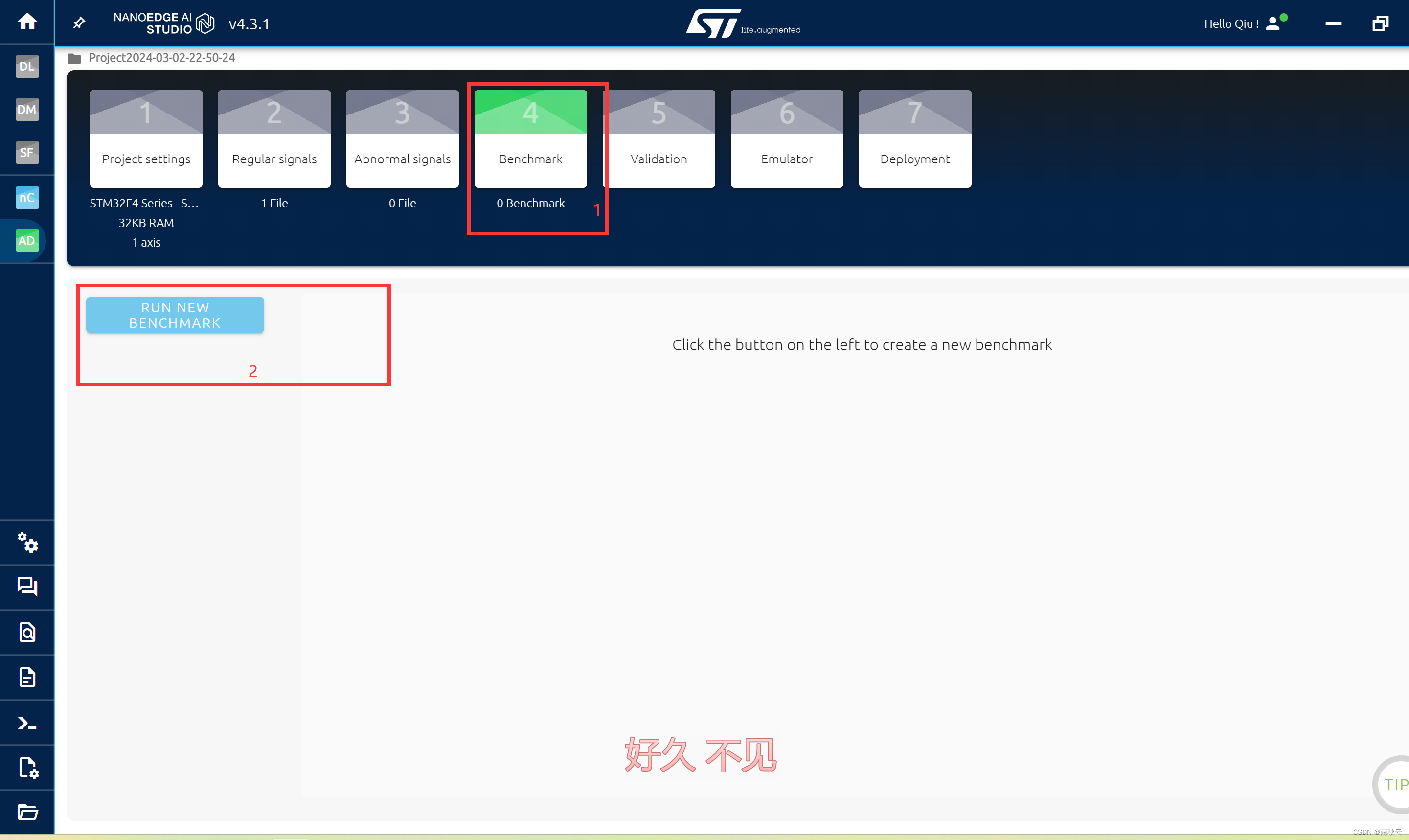
这里选择RUN NUW BENCHMARK进行模型训练
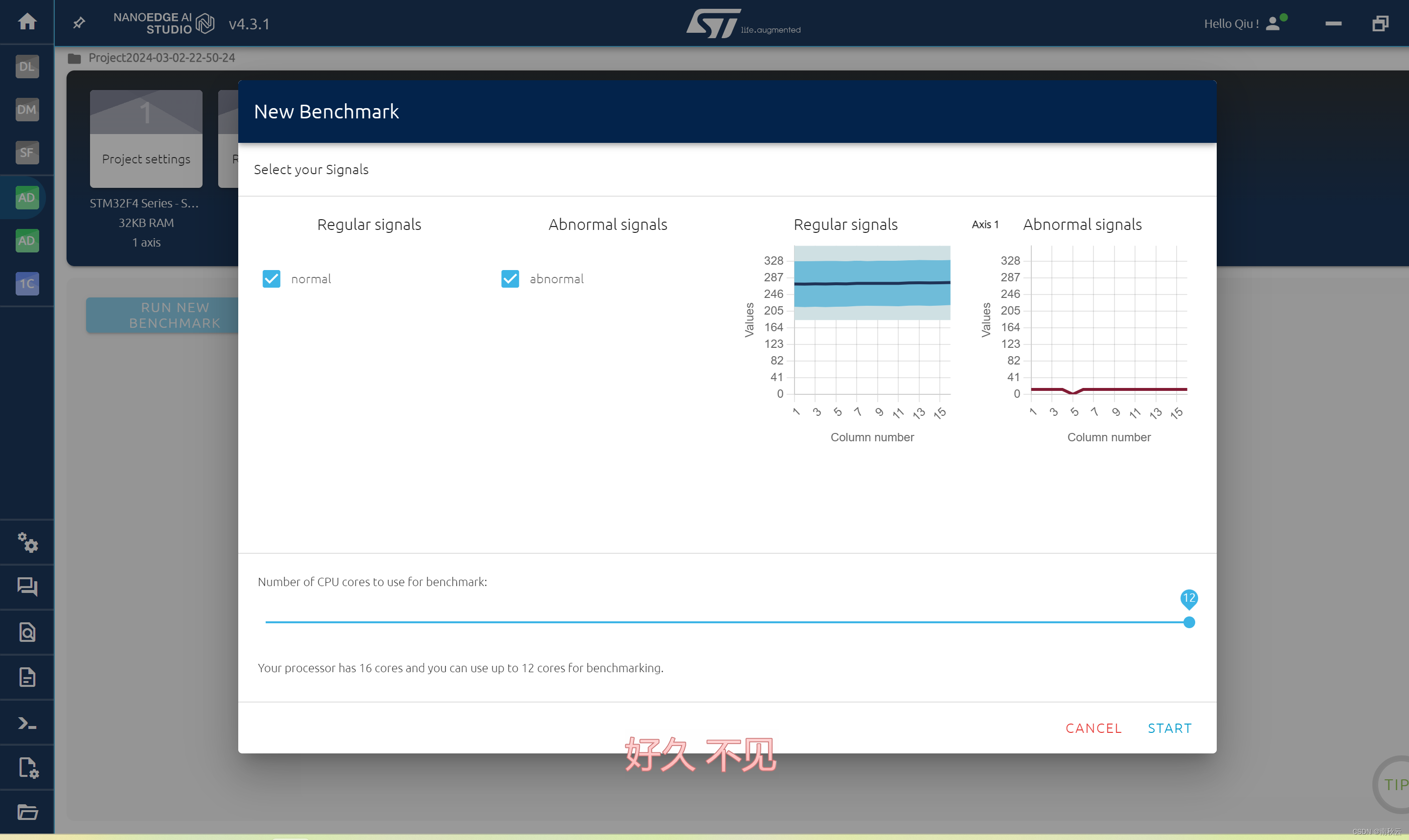
选择START 开始
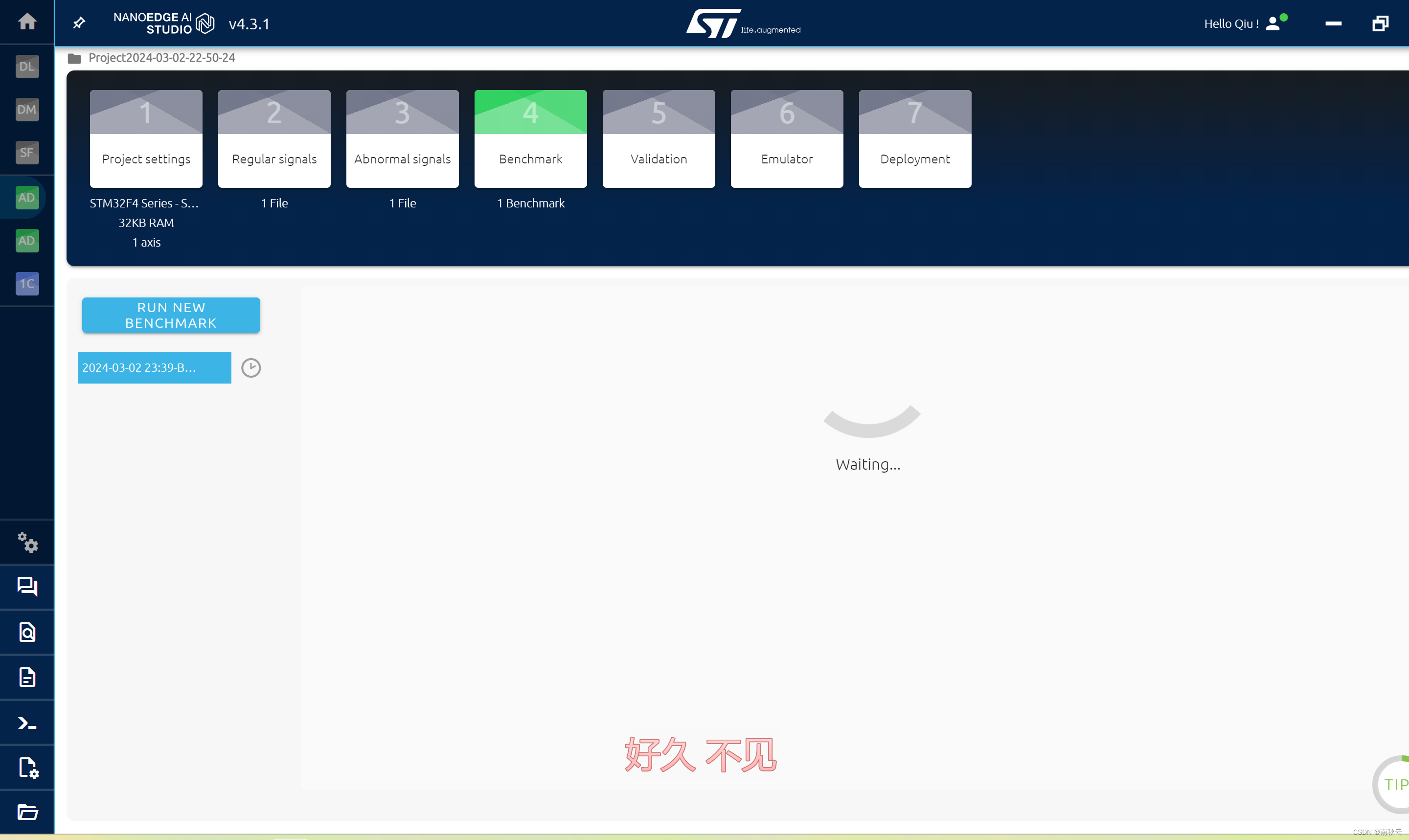
等待一下,它会自动从算法搜索符合咱们需求的算法。
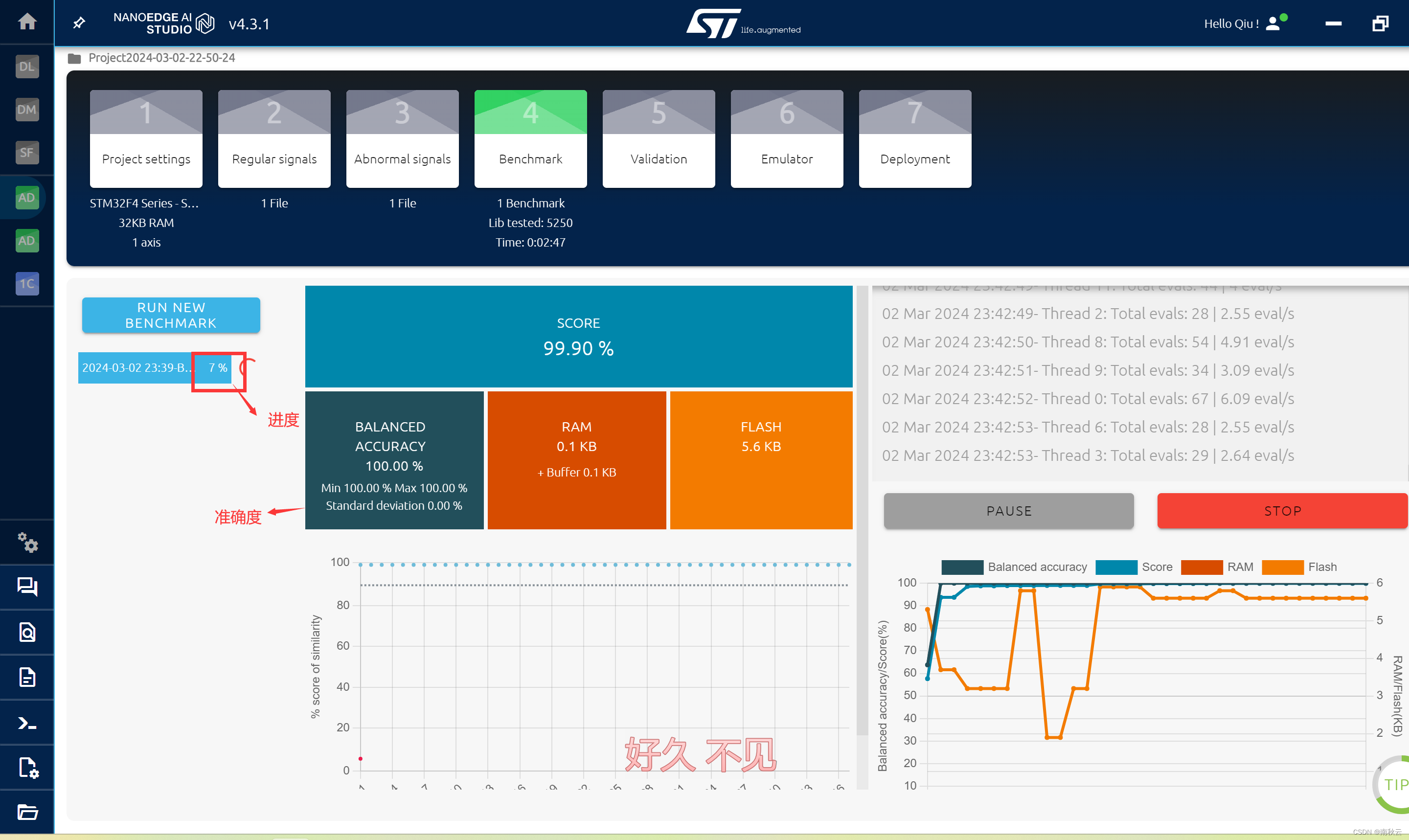
可以看到,模型准确度还是很高的。
我这里训练结果还挺高的,就直接STOP了,你们可以等待训练完成。
如果准确度不高,可以在RUN NEW BENCHMARK选择一个新的模型进行训练,然后在训练完成的模型里选择符合你要求的。
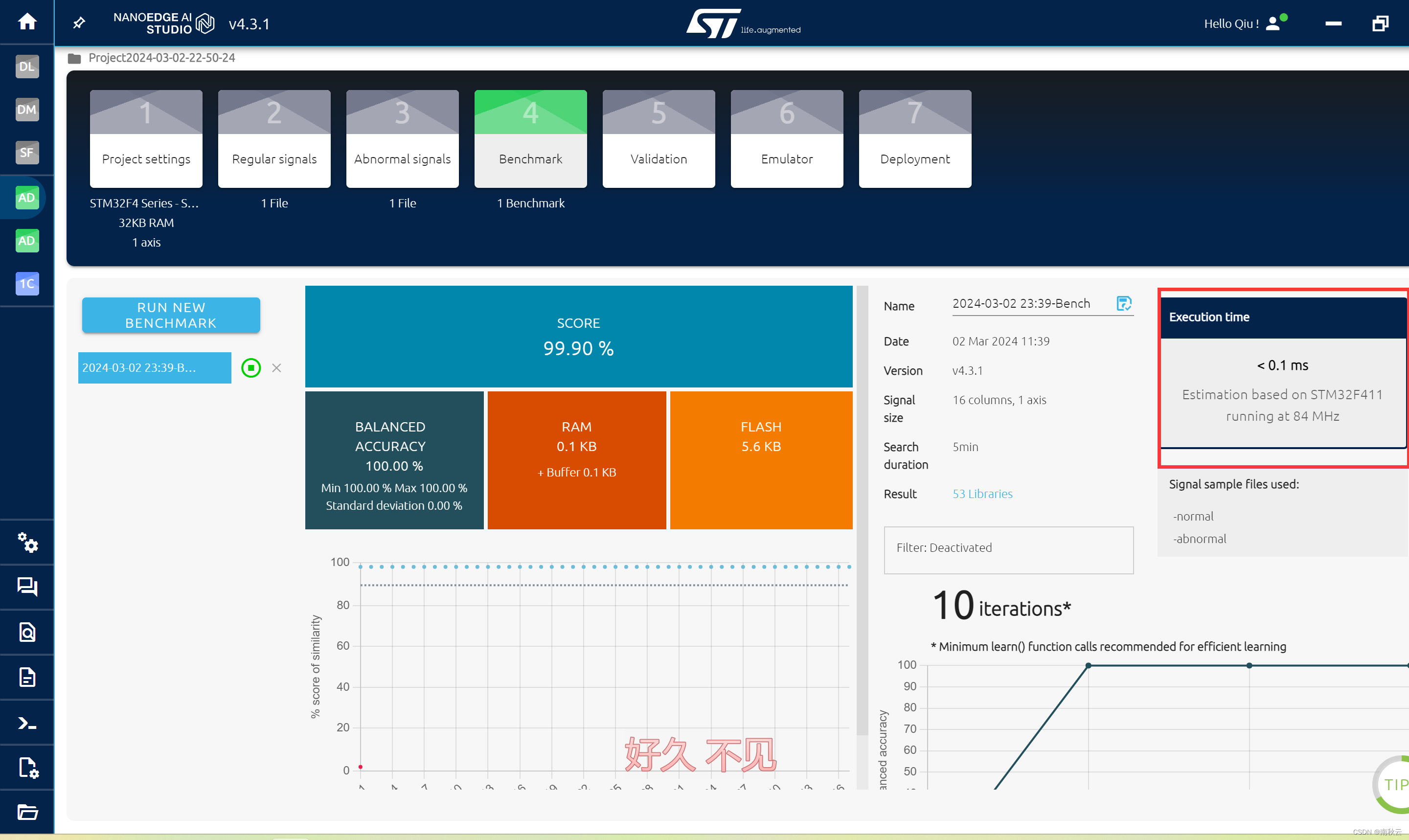
训练结果还不错,给STM点个赞,很棒!
5.验证
这一步你可以导入一些数据给模型,看训练结果。

选择算法库
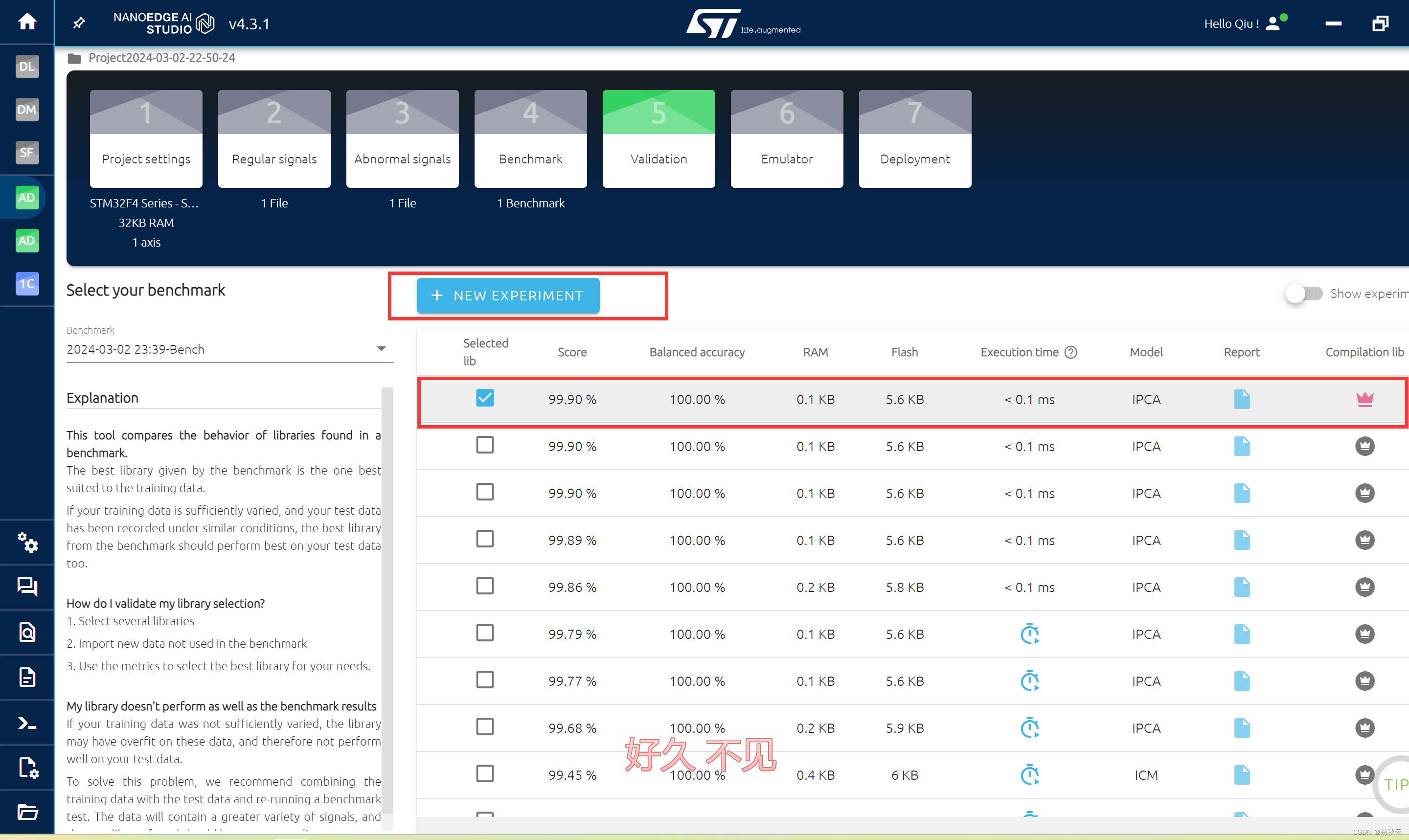
点击NEW EXPERIMENT
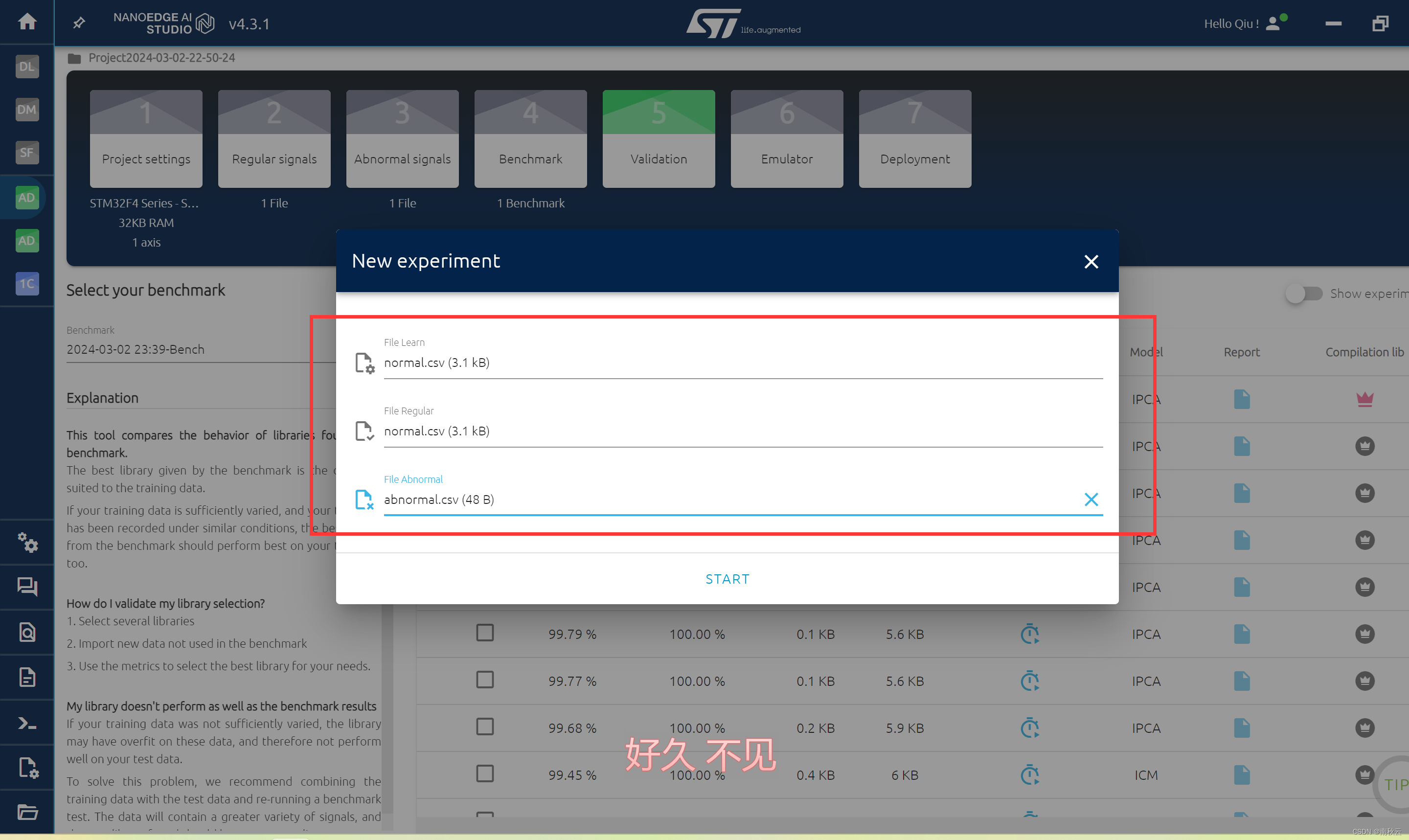
导入数据,这里learn是指在MCU上需要学习的数据。
normal是指正常数据
abnormal是指异常数据
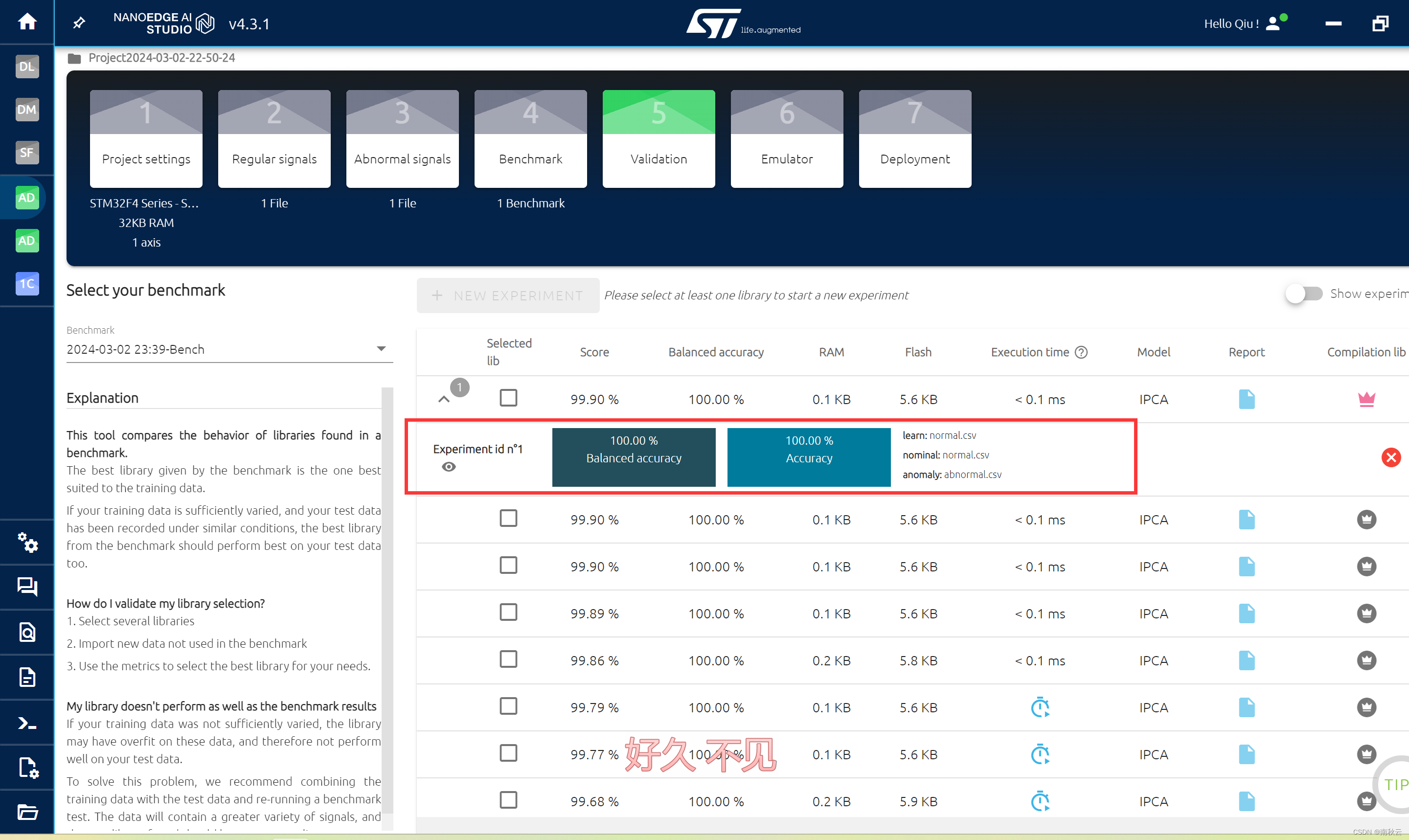 查看结果,几乎完全正确。
查看结果,几乎完全正确。
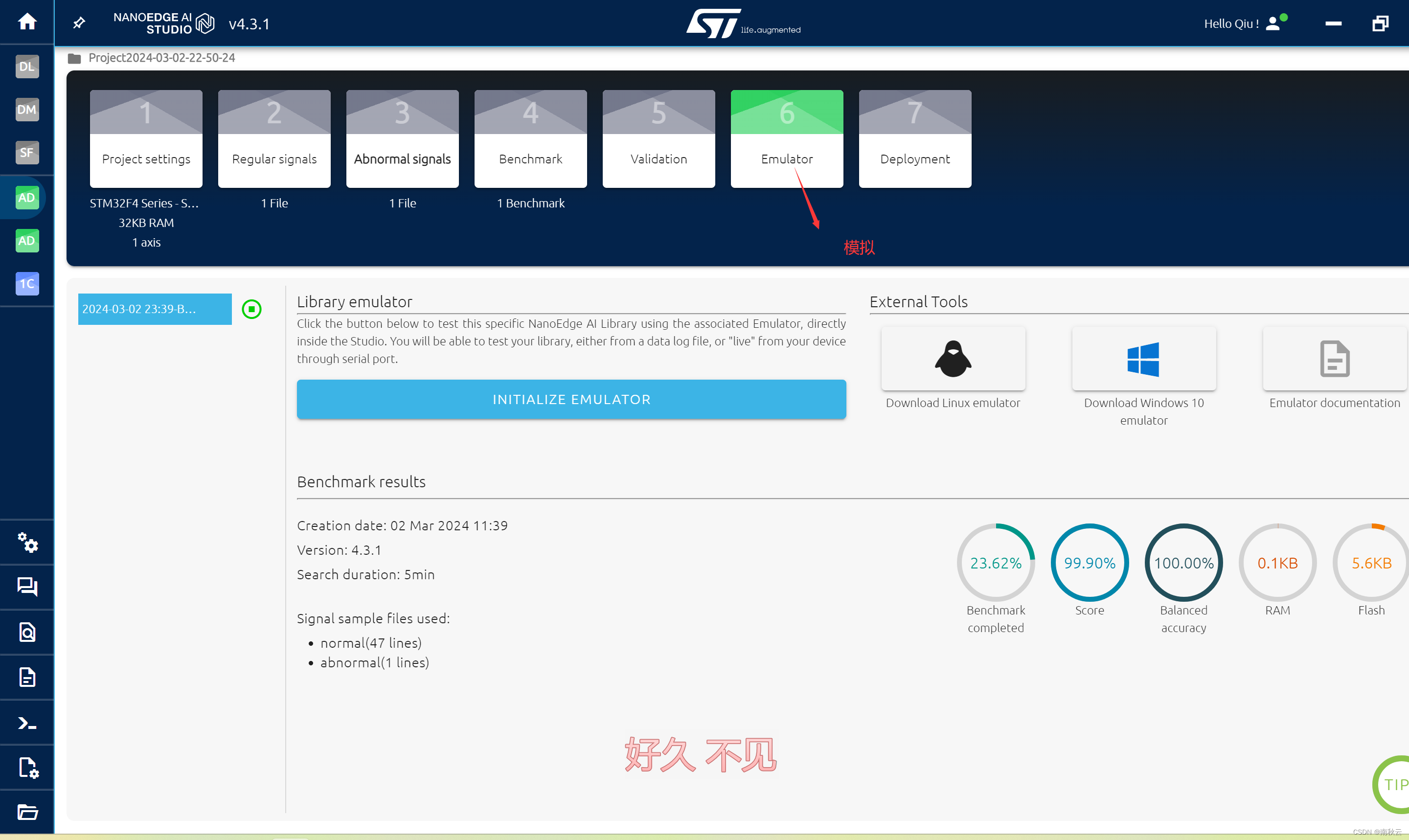
这一步是指在PC上运行当前训练完成的模型,看数据的模型的运行情况。
点击 INITIALIZE EMULATOR
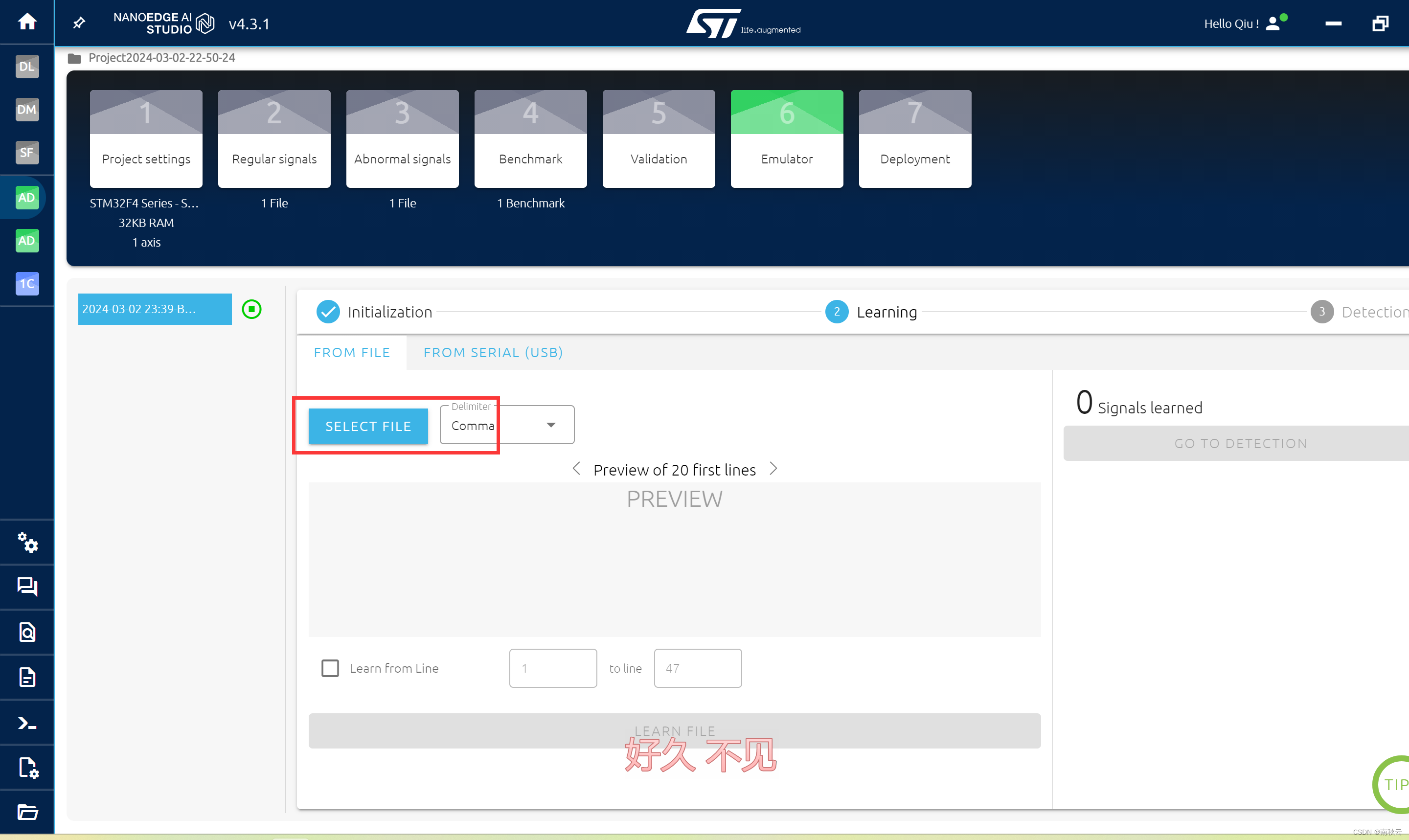
导入数据。
这里的数据格式和2.导入数据是一样的。
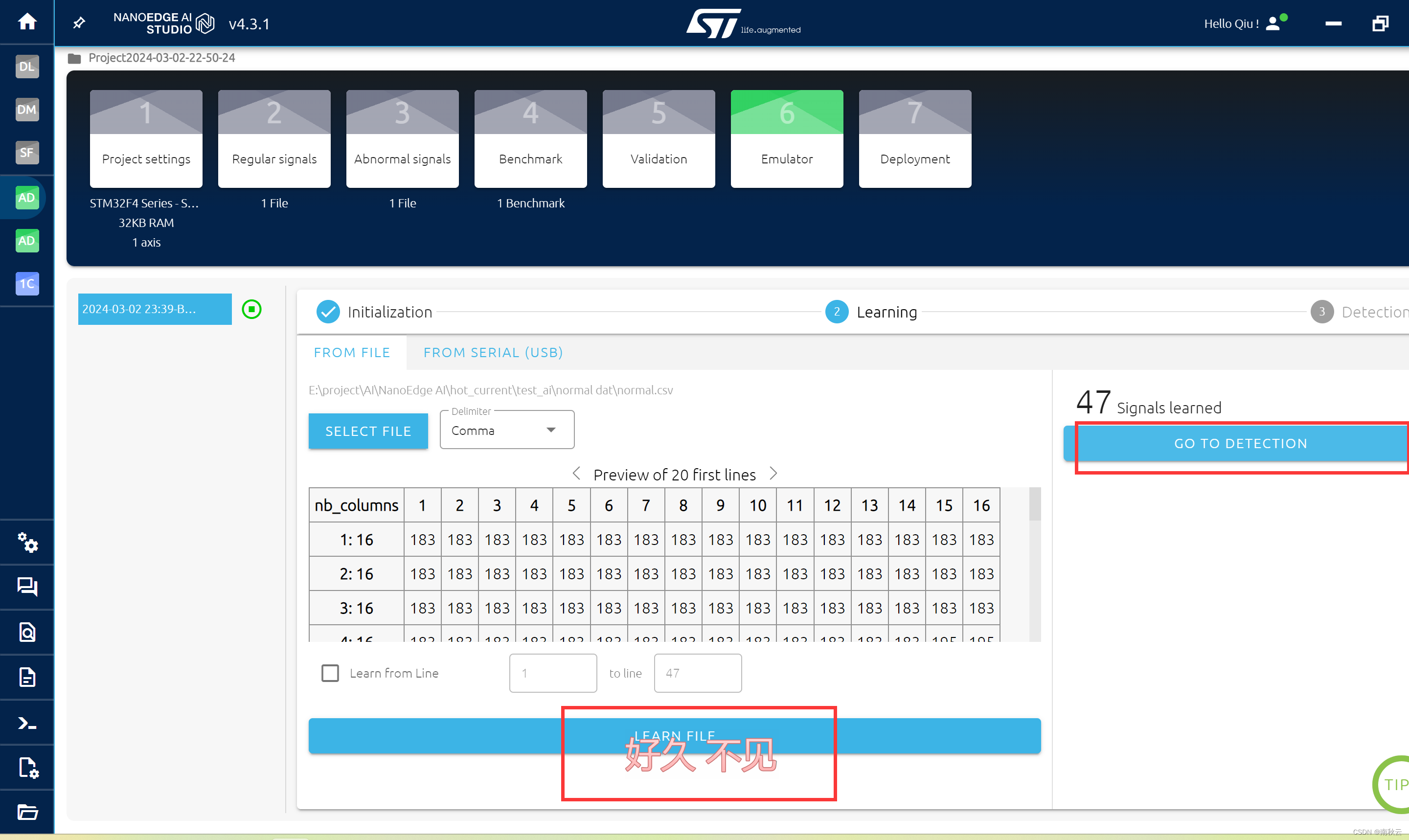
选择LEARN FILE和GO TO DECTECTION
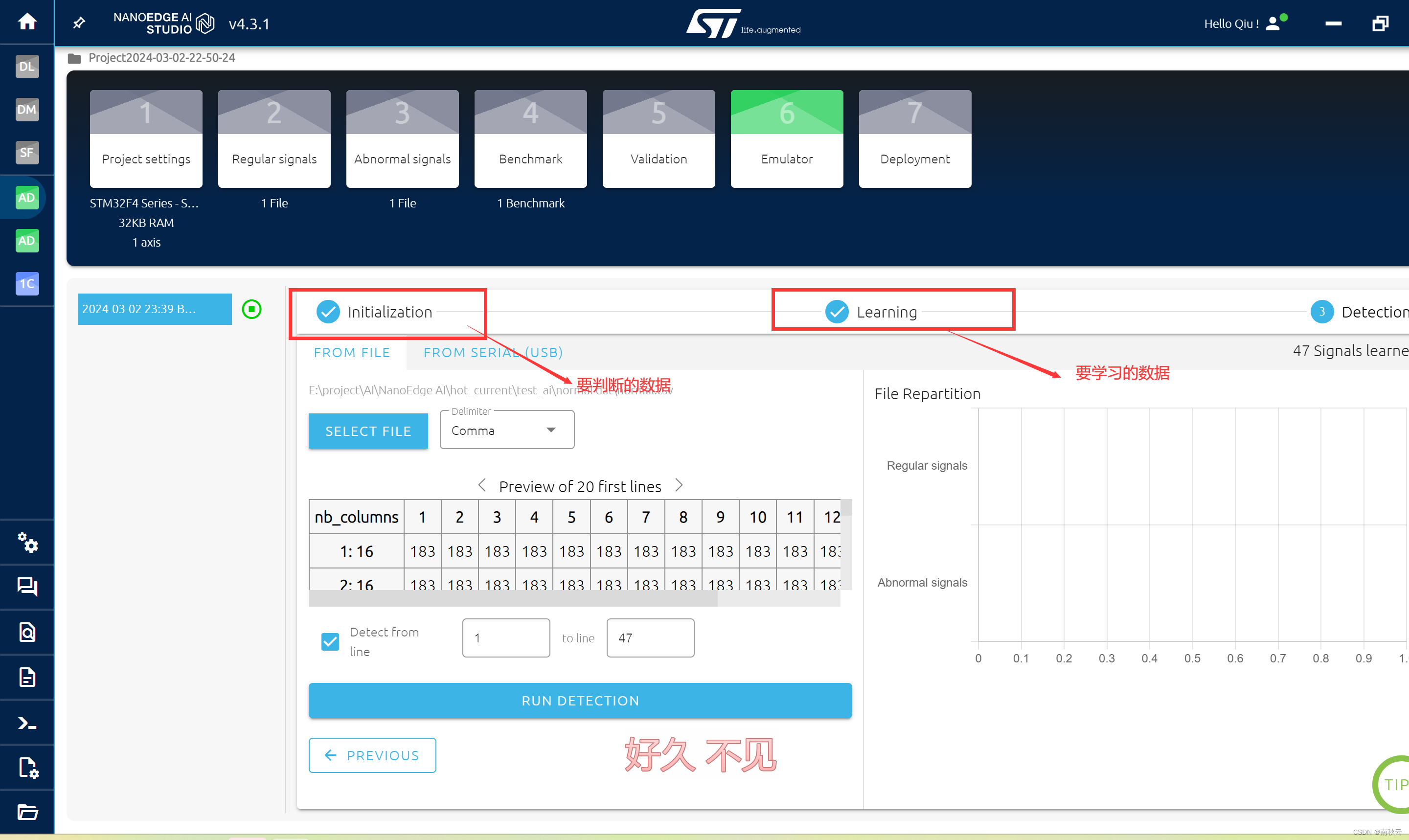
添加要学习的数据,和上一步一样的操作。
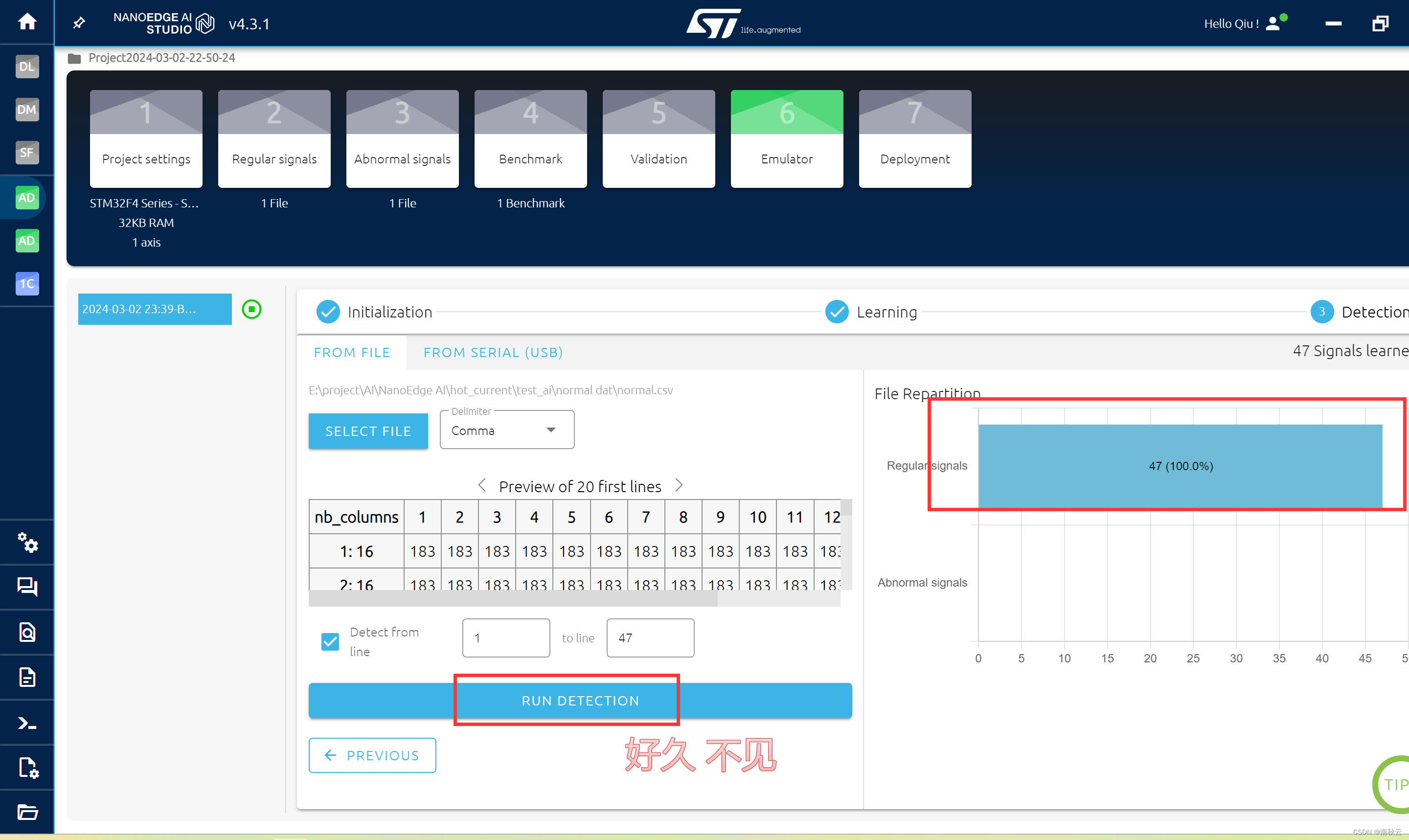 点击RUN DECTECTION进行数据判断,可以看到判断正确。
点击RUN DECTECTION进行数据判断,可以看到判断正确。
6.生成模型
写到这里的时候刚好是十二点,累成狗,也不知道为啥这么热爱这个专业,明明写代码写到梦里都在找BUG解决方案,还是这么热爱。哎,天生就是劳碌命。
前进吧,继续写。
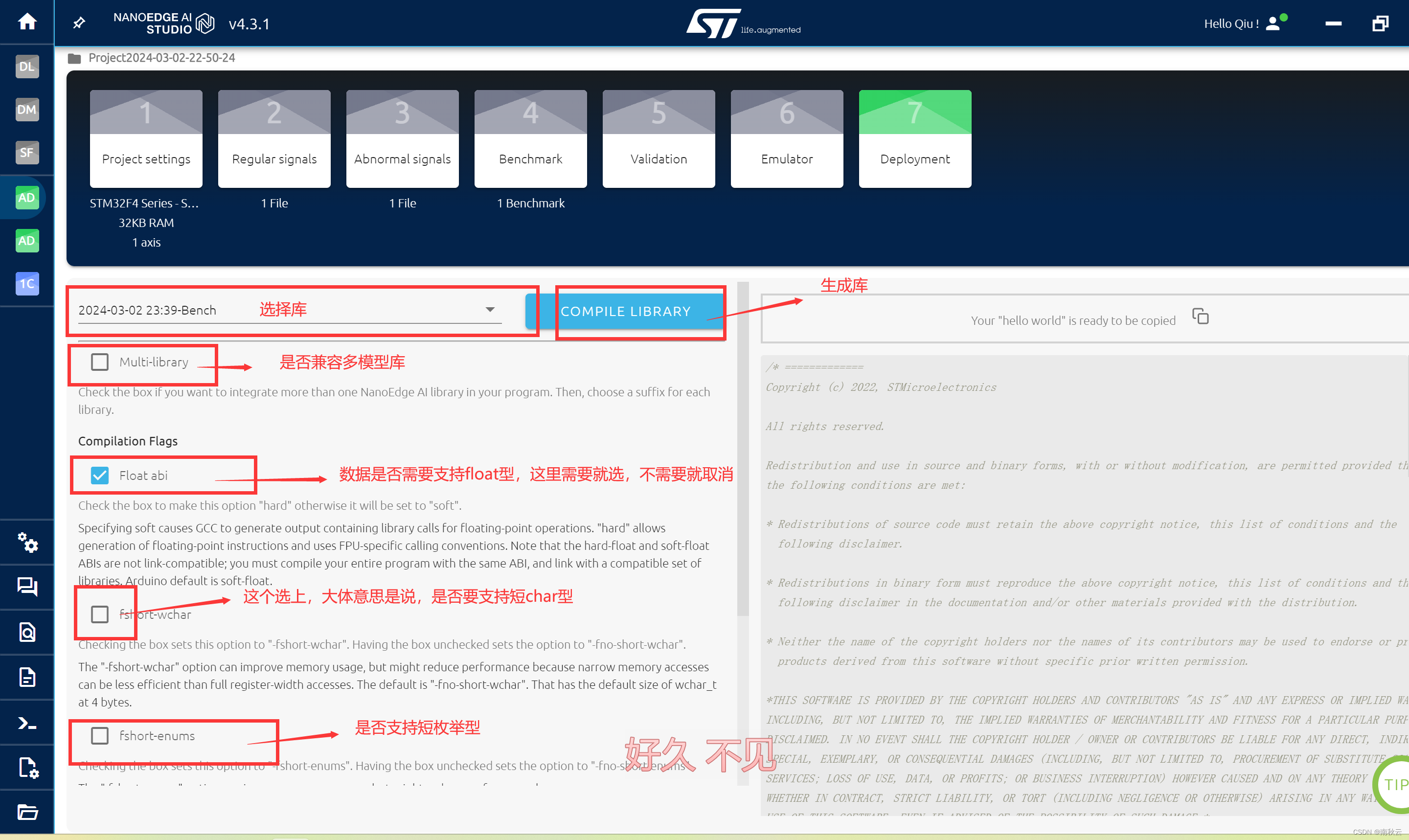
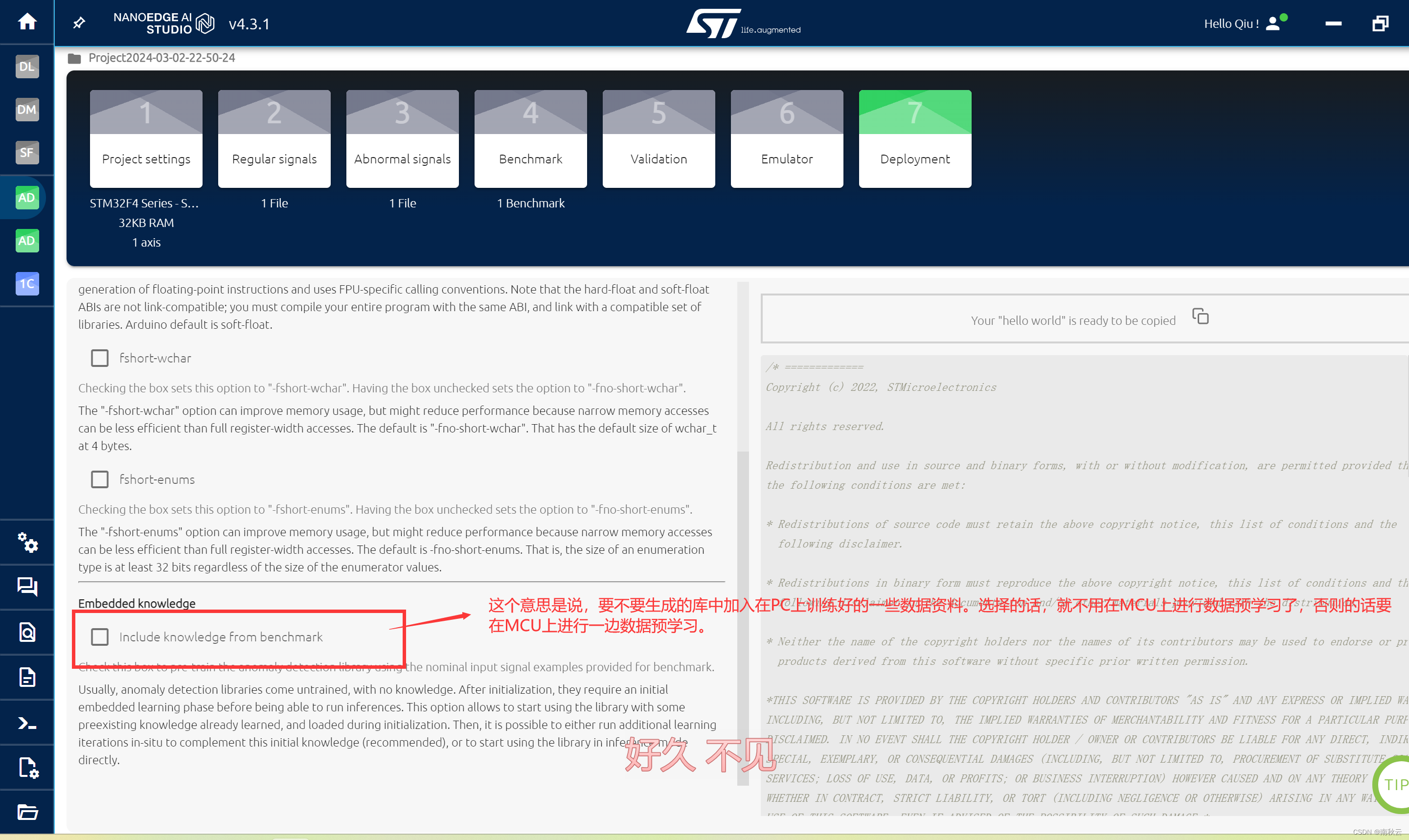
按需选择好。
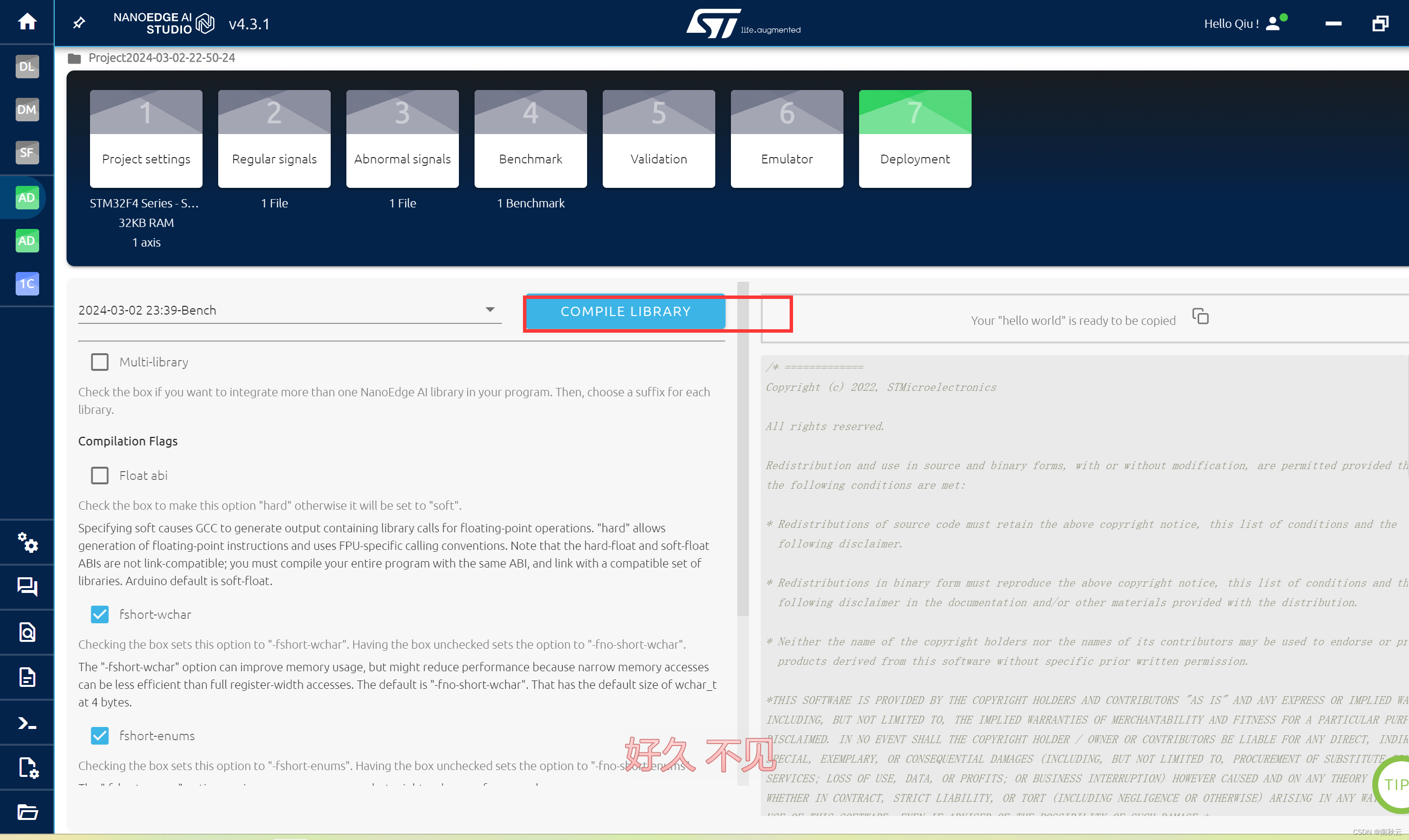
设定好后,点击COMPILE LIBRARY生成模型库。
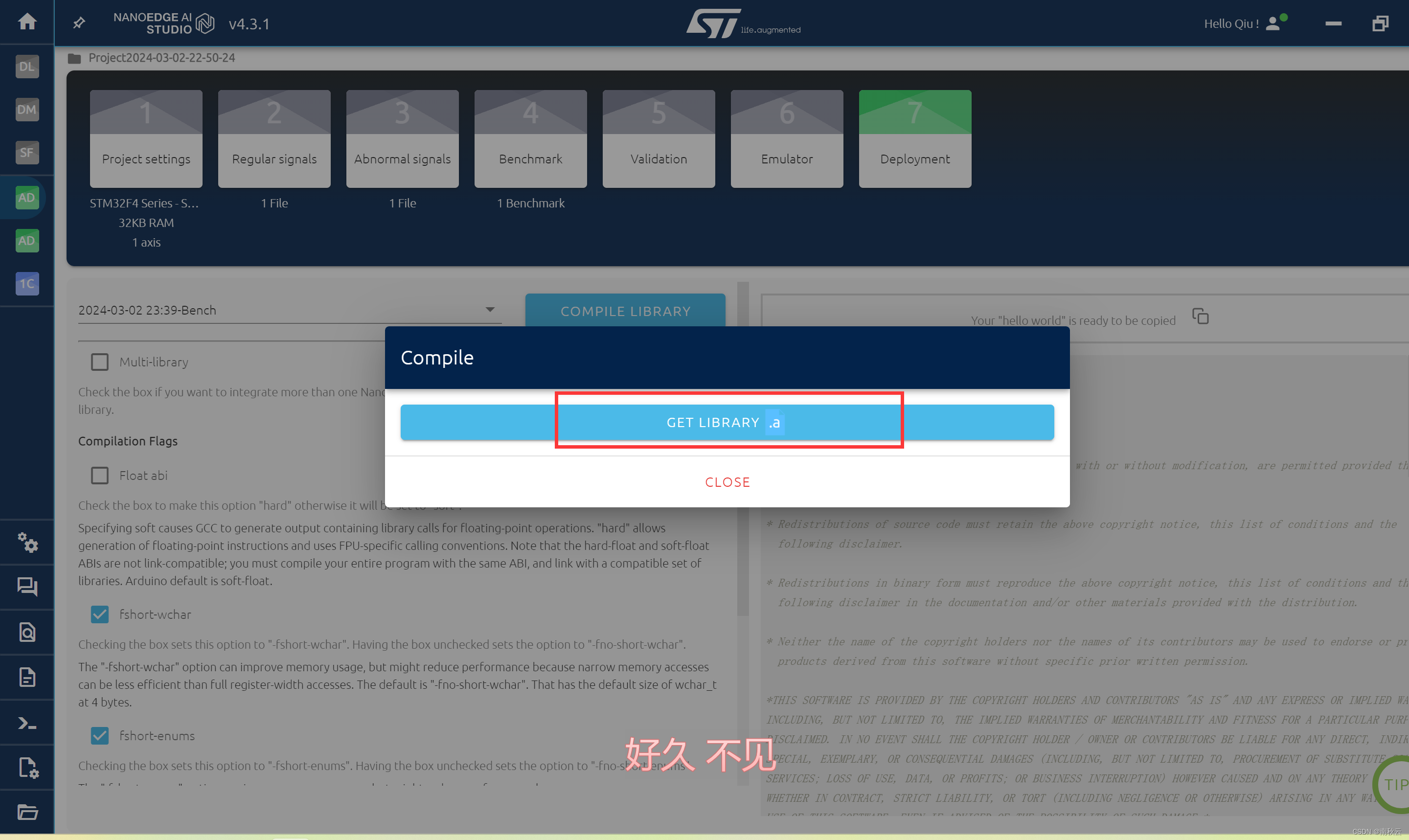
保存模型。
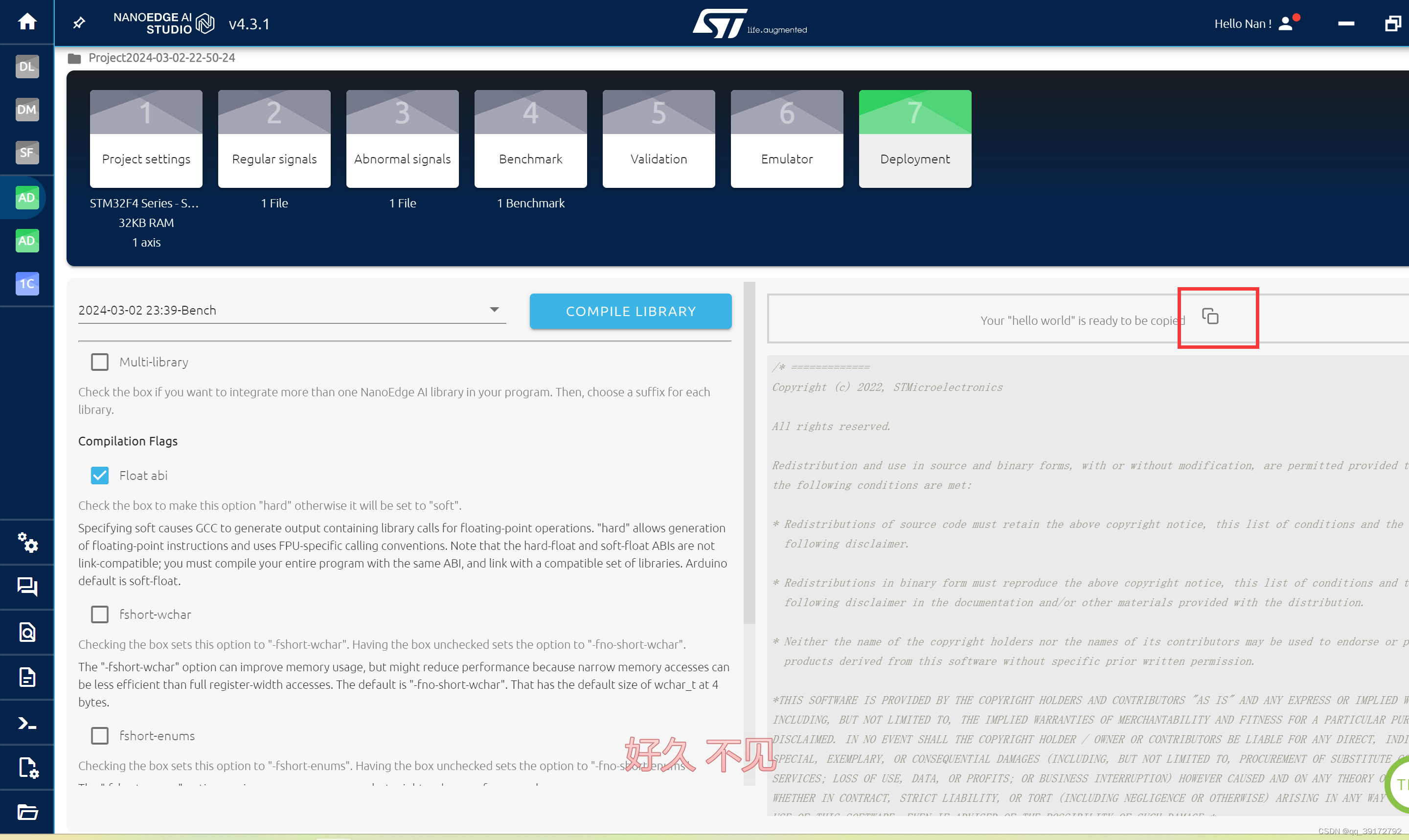
这个复制走,这里教你怎么用这个库。
7.布置模型
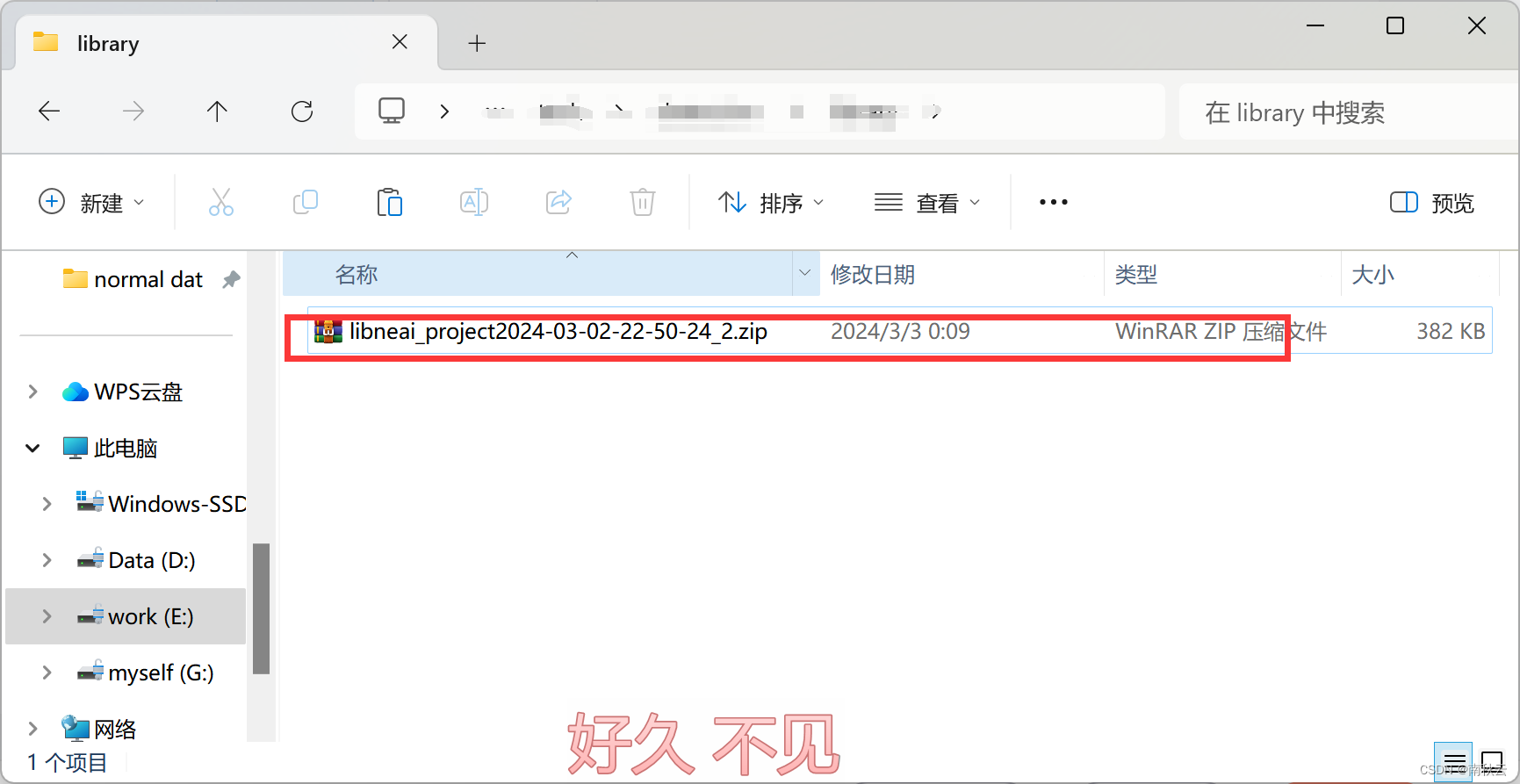
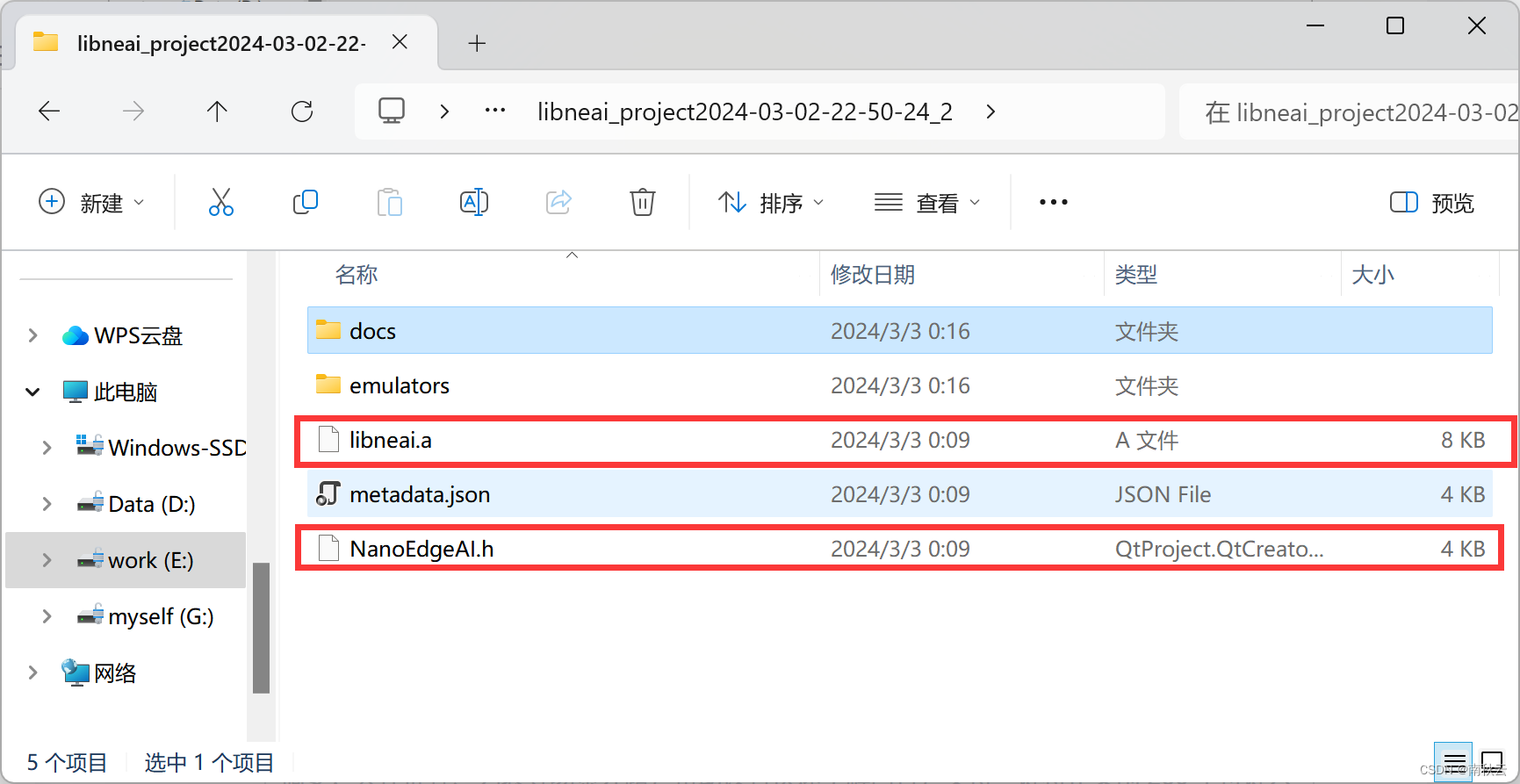
解压模型,将这俩复制到你的工程下面。
keil 导入库这俩文件。
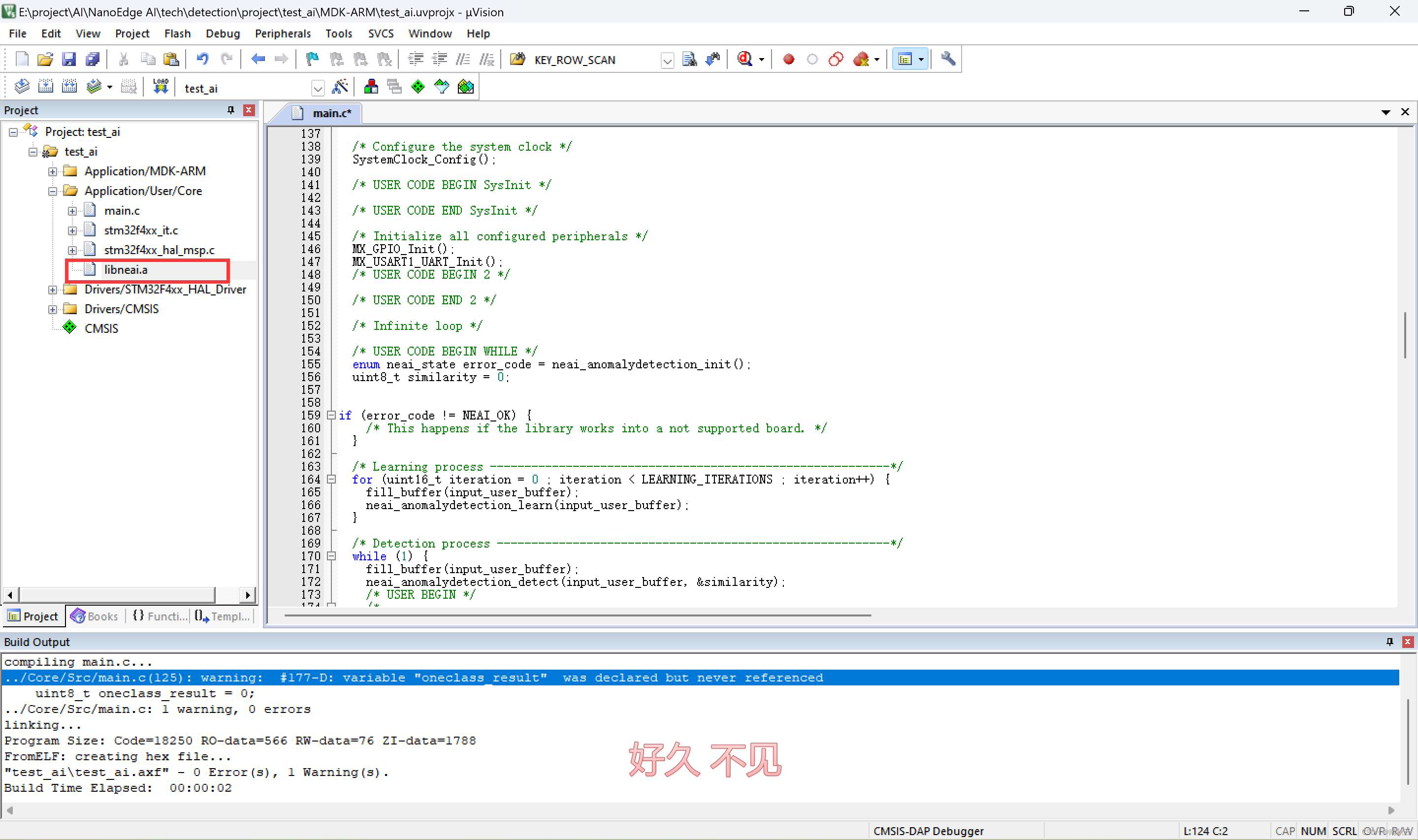
这里可能会对库文件报错,解决方法是右击选择Options for File “libneal.a”
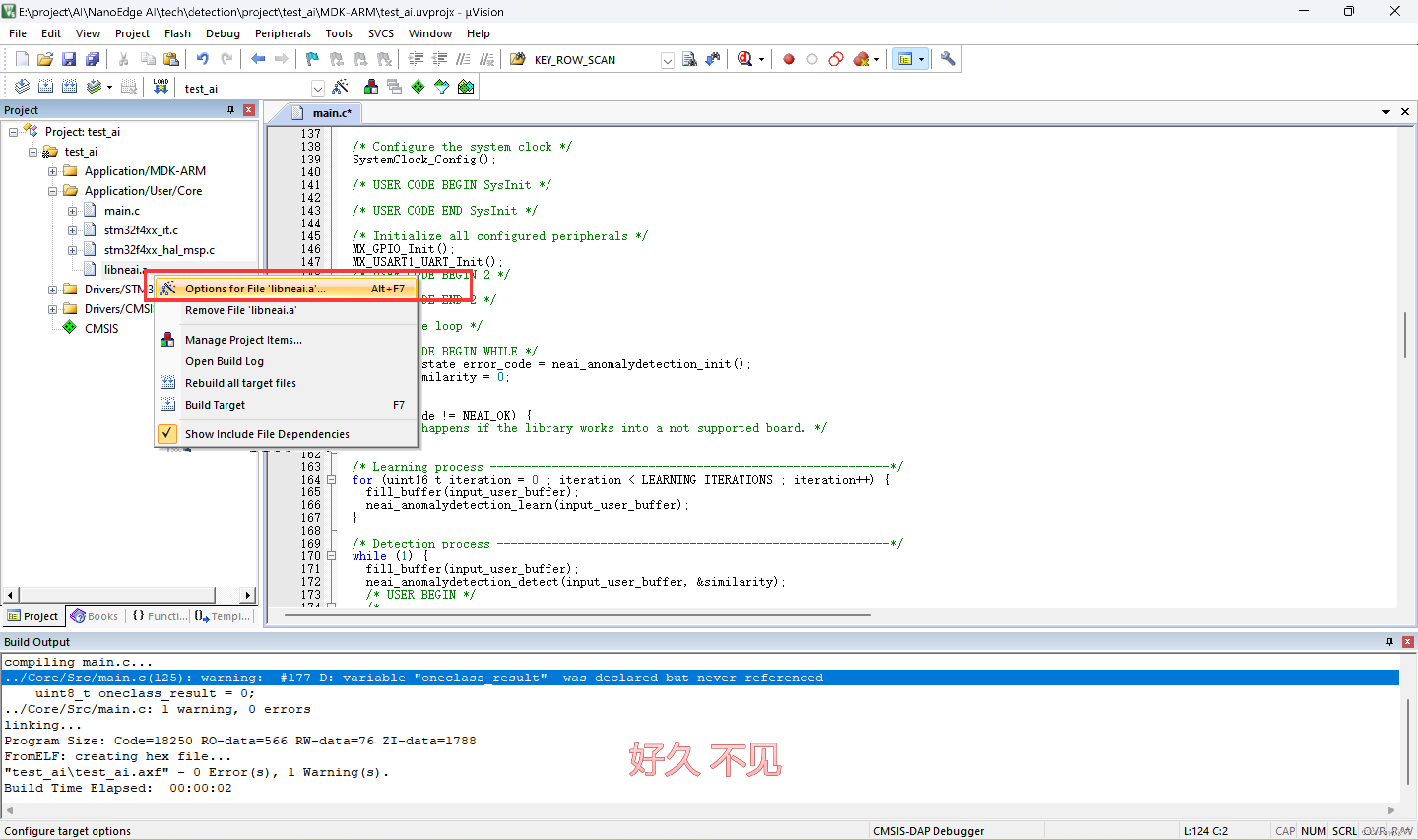
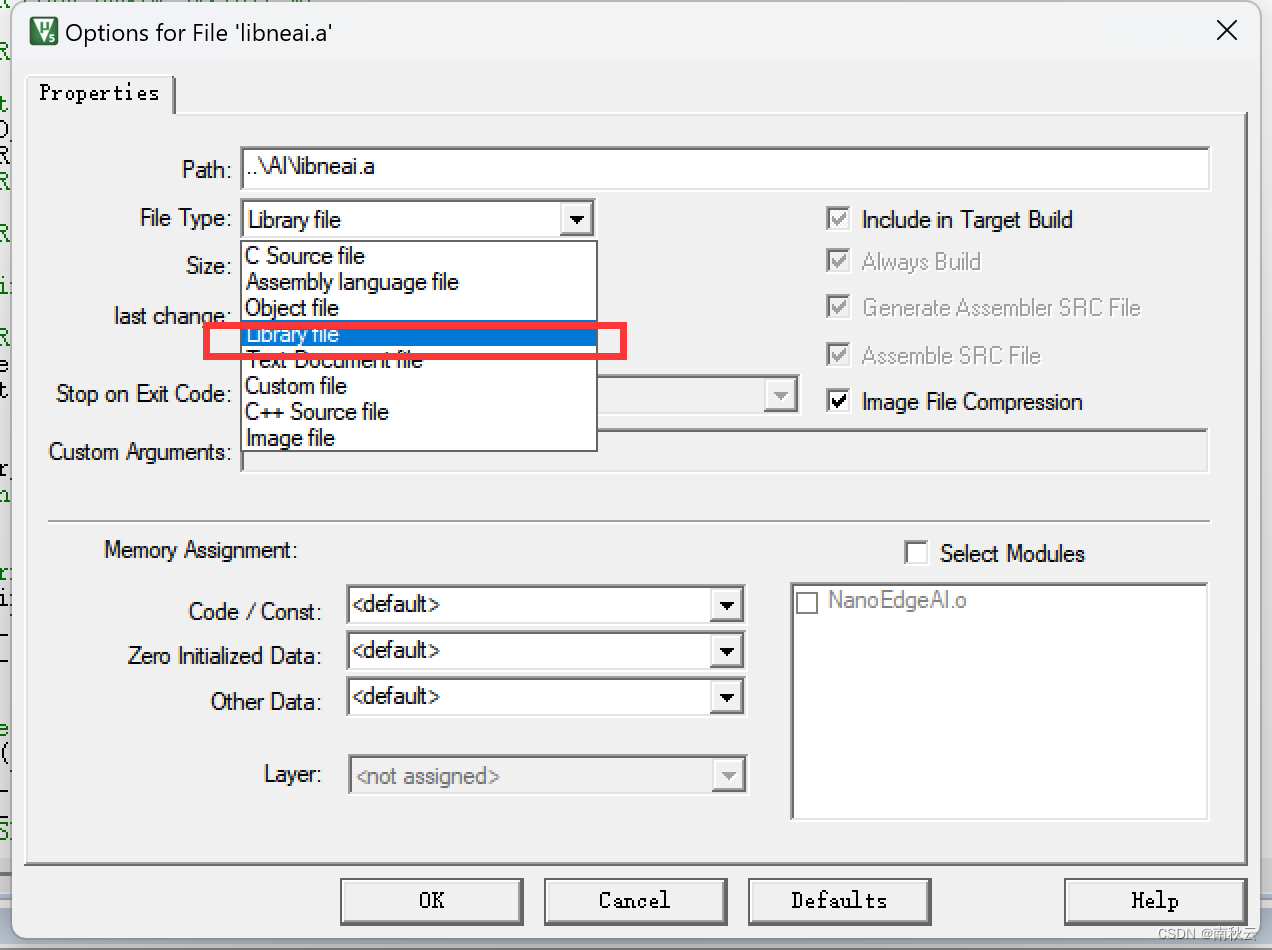
选择库文件。
OK,接下来教你怎么用这个库。
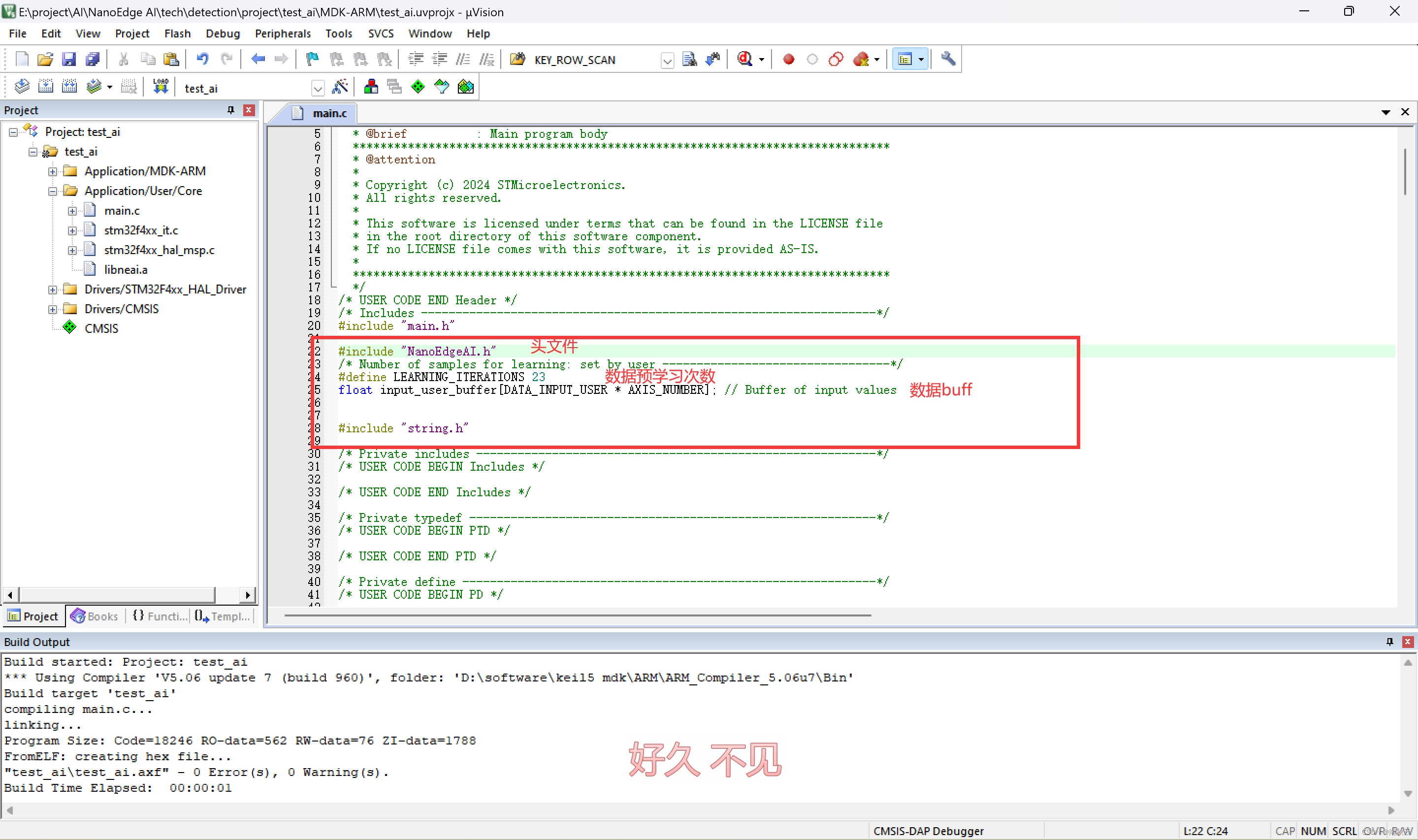
从这里面复制这些部分到keil
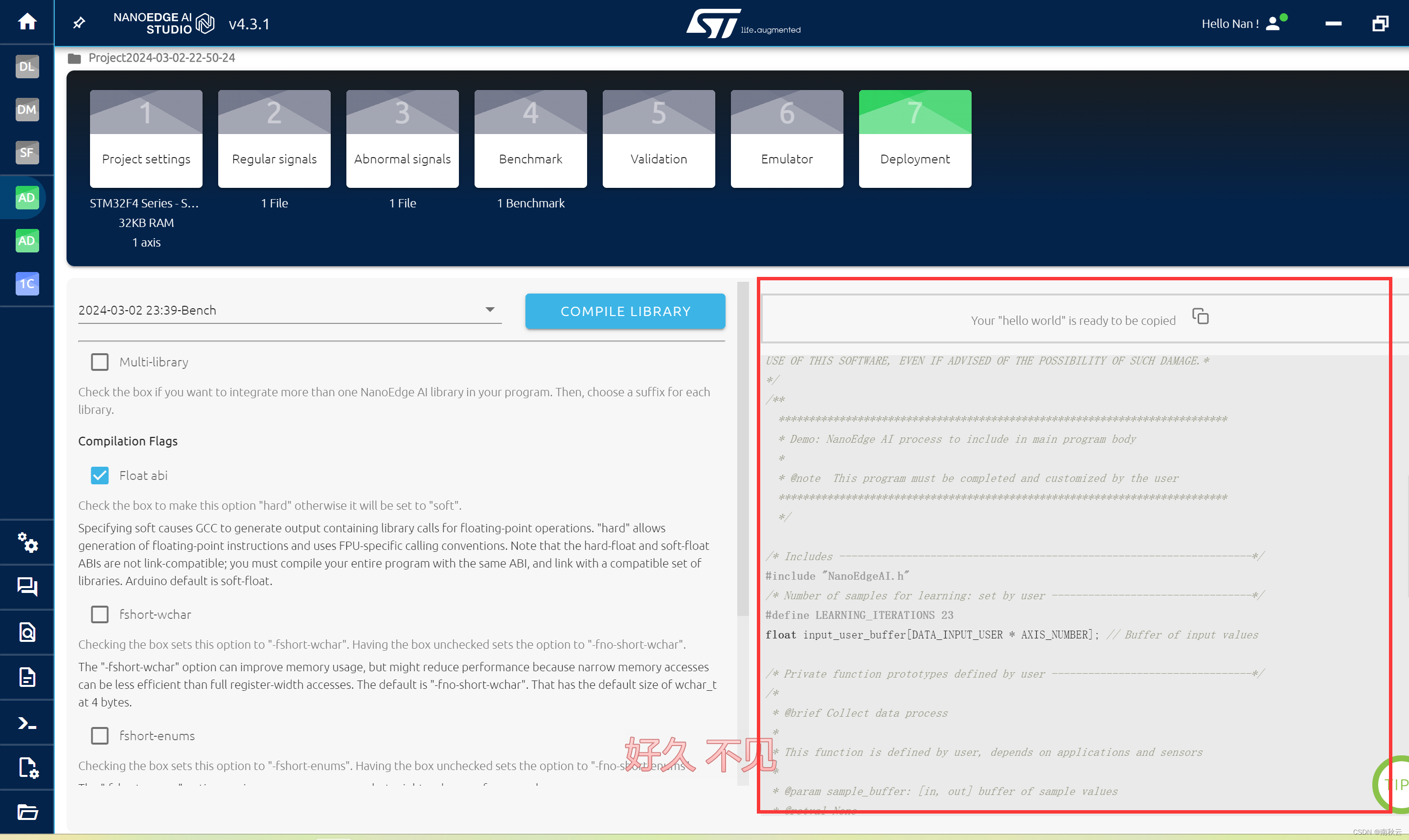
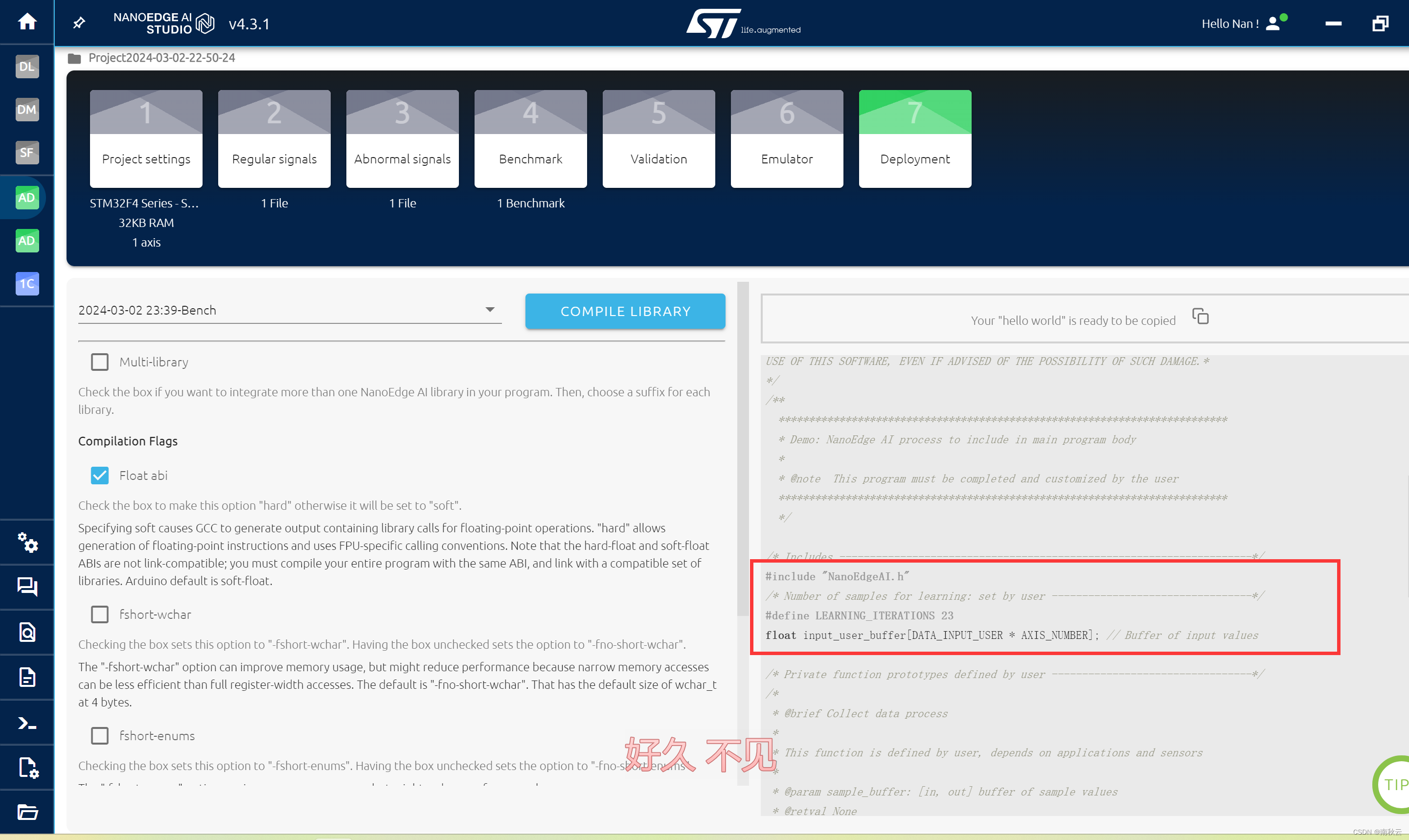
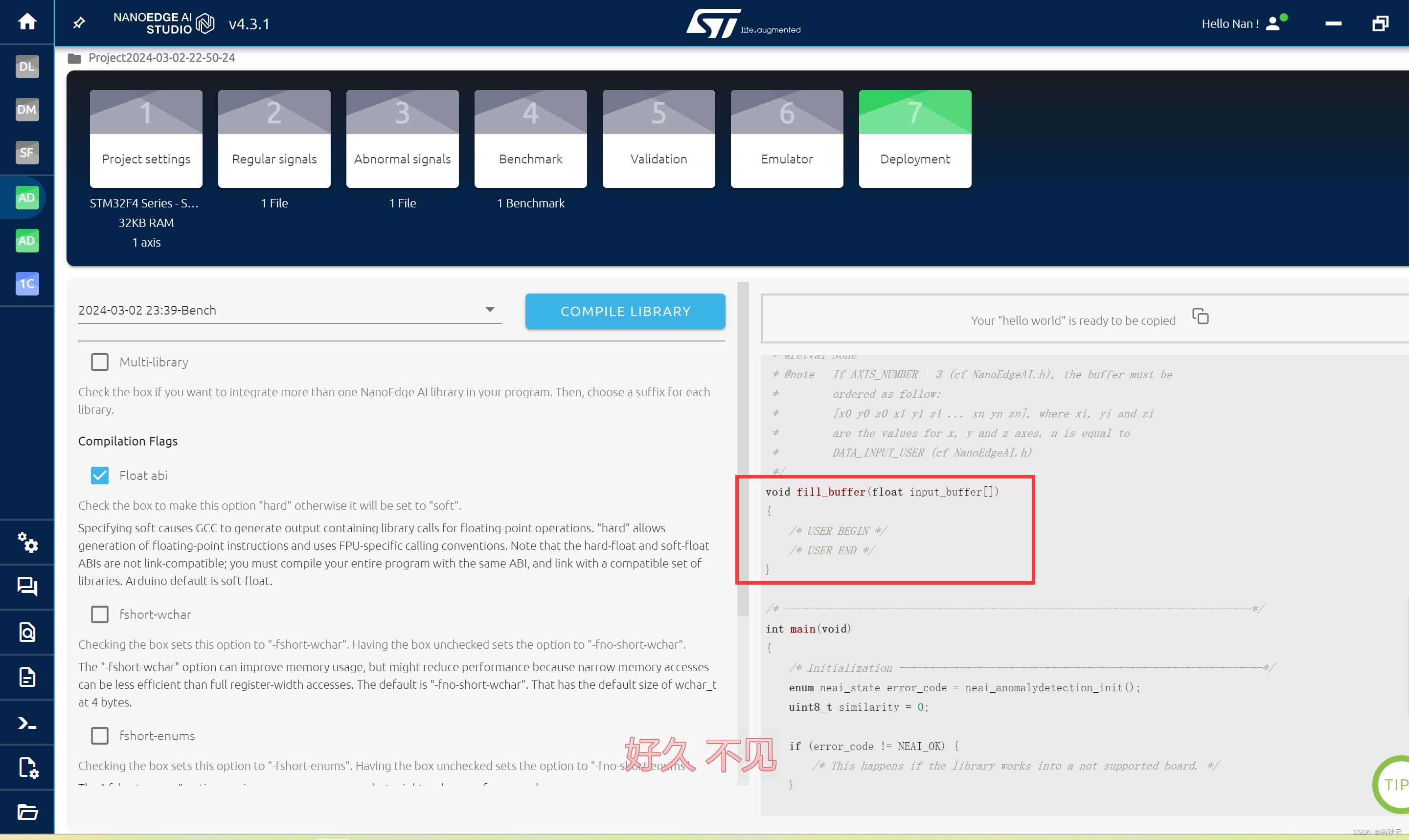
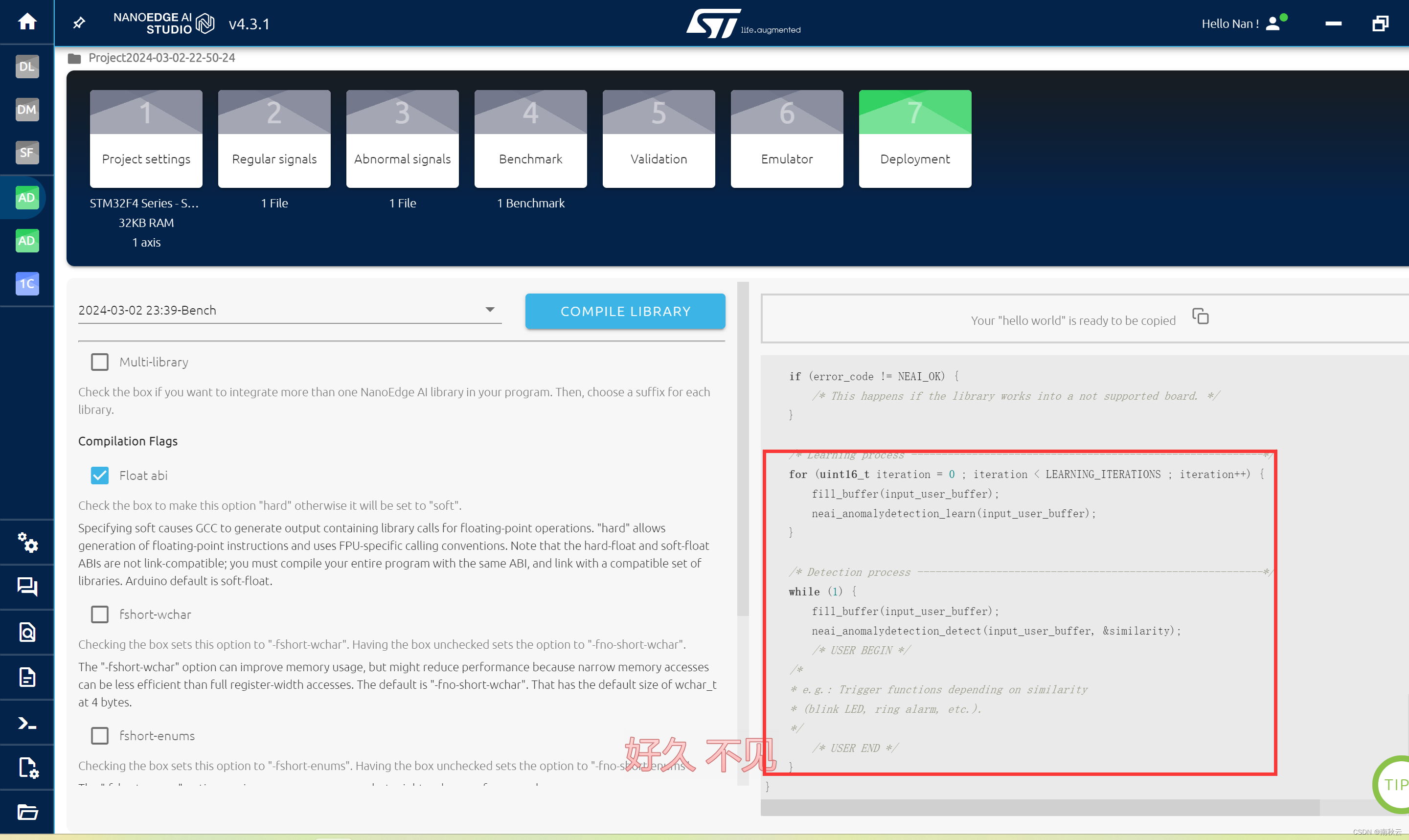
简单讲一下这些都是干嘛的。
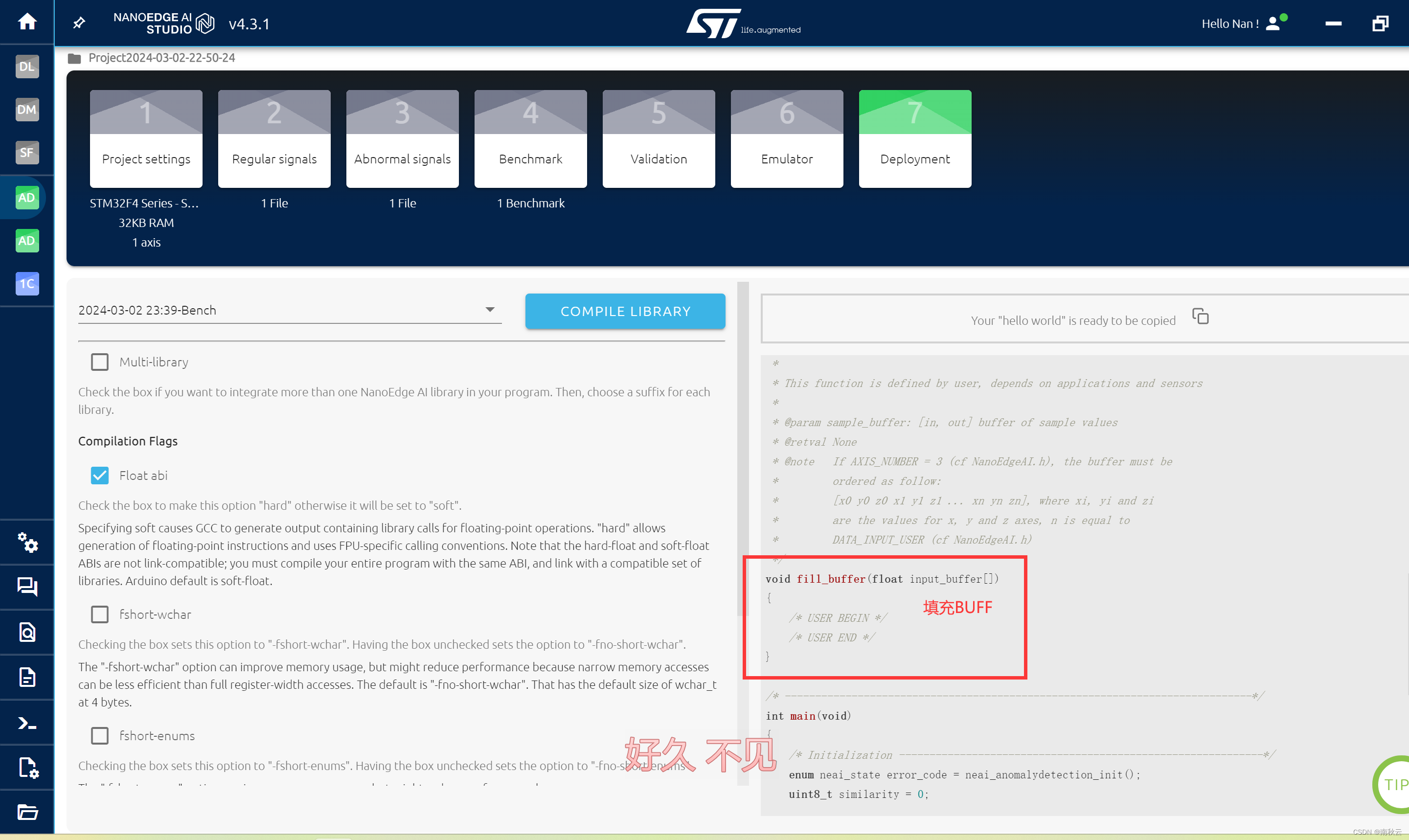
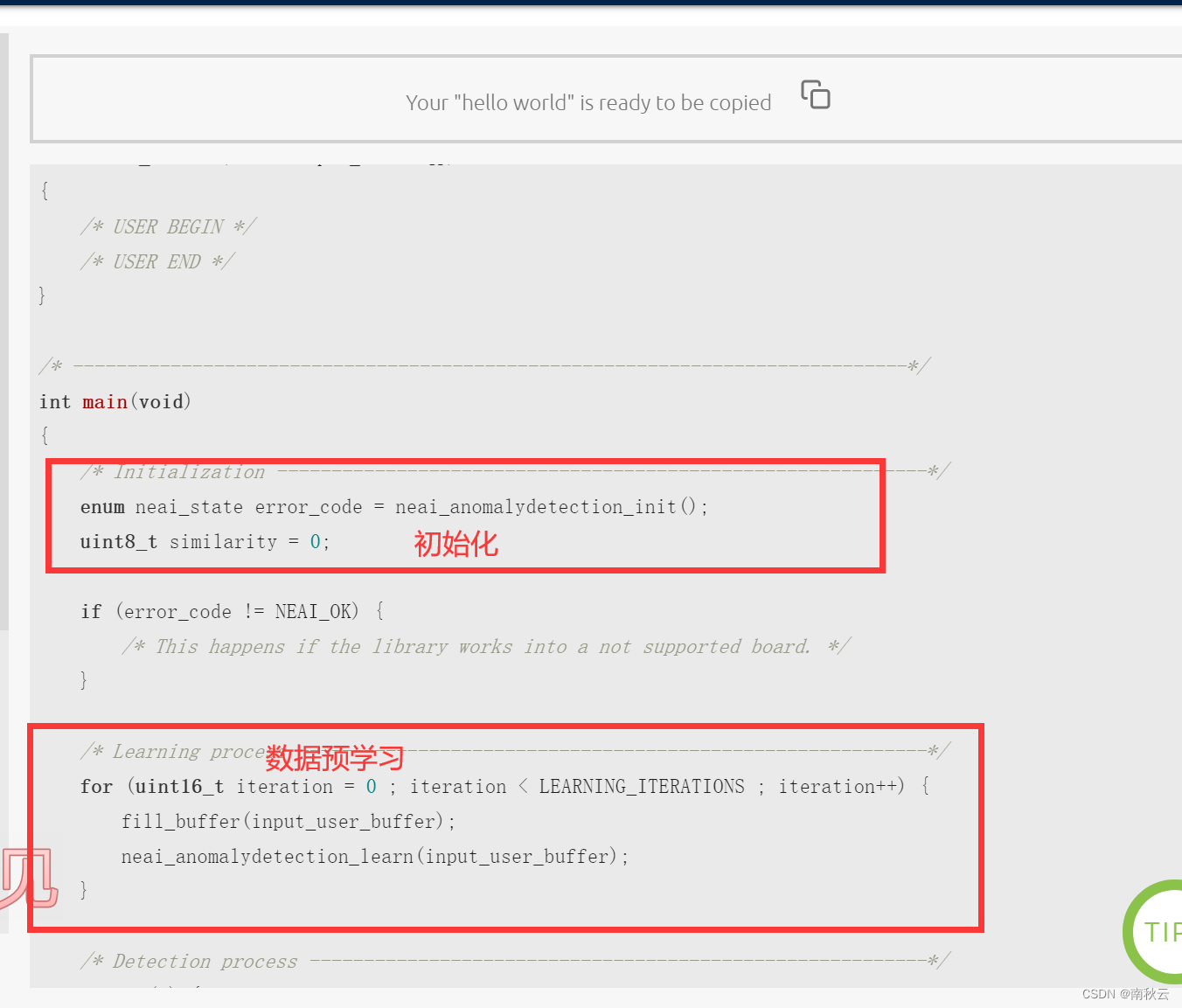
 简单讲讲整个过程是就是,先将数据填充到input_user_buffer中,对这个数据进行预学习。
简单讲讲整个过程是就是,先将数据填充到input_user_buffer中,对这个数据进行预学习。
然后后续将数据填充到input_user_buffer,然后对这个buff进行判断。
其中similarity会输出与正常数据的相似度。
注意,input_user_buffer的填充格式与csv格式相同
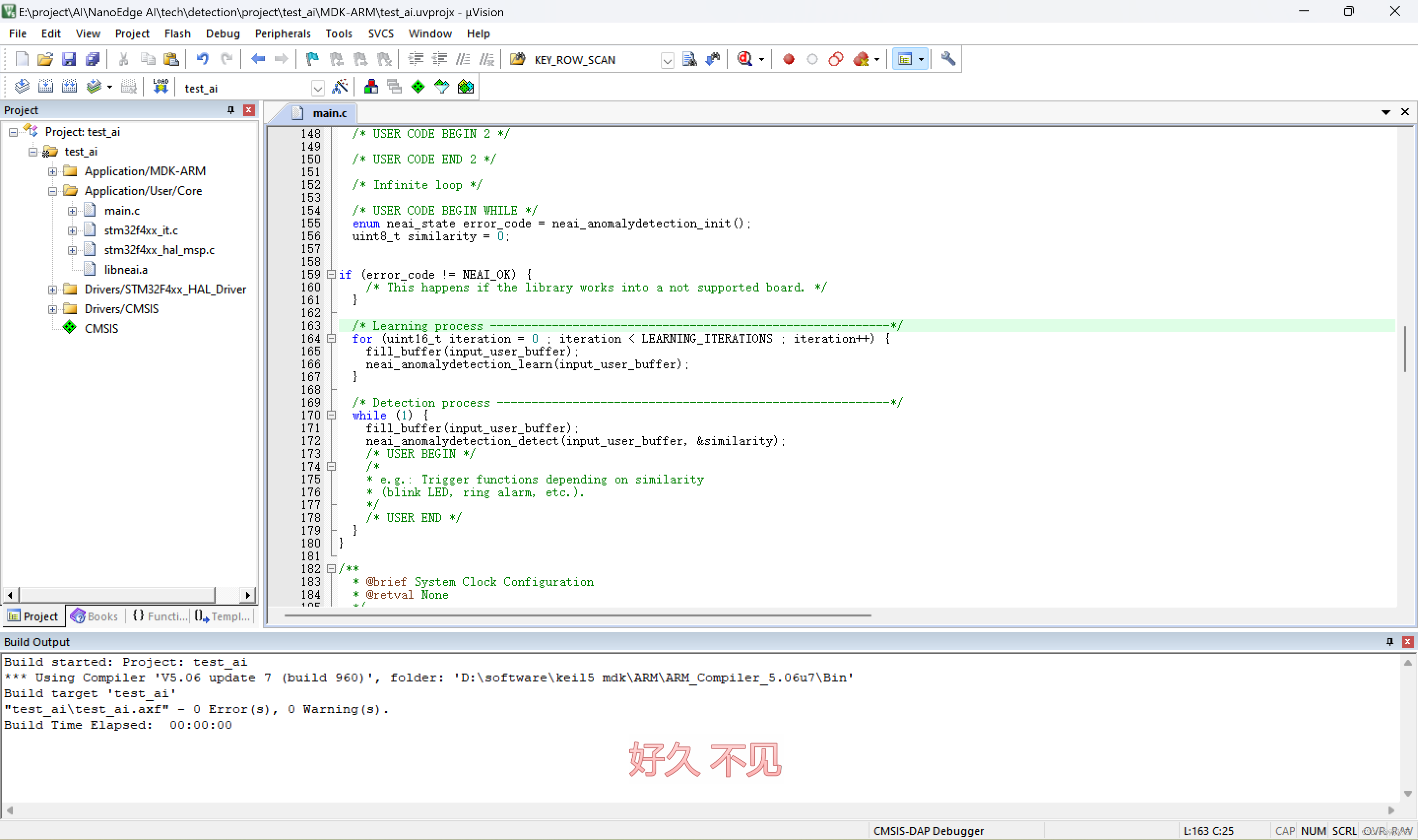
编译没问题,就下载到MCU,然后,try。



















 5955
5955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











