







 时间轮算法是一种高效的任务调度机制,通过模拟时钟来安排延迟执行的任务。在Netty中,HashedWheelTimer是其实现,允许设置每个刻度的时间和轮的刻度数。文章举例说明了如何计算任务的执行位置,并展示了简单的代码实现。时间轮适用于心跳检测、会话超时管理和消息延迟推送等场景。对于大时间跨度的任务,可以使用多重时间轮来提高精度和效率。
时间轮算法是一种高效的任务调度机制,通过模拟时钟来安排延迟执行的任务。在Netty中,HashedWheelTimer是其实现,允许设置每个刻度的时间和轮的刻度数。文章举例说明了如何计算任务的执行位置,并展示了简单的代码实现。时间轮适用于心跳检测、会话超时管理和消息延迟推送等场景。对于大时间跨度的任务,可以使用多重时间轮来提高精度和效率。
原理
时间轮算法借助时钟的思想,可以将时间轮看作一个时钟,上面有刻度,每个刻度代表多少时间,每个刻度上放着若干个任务。

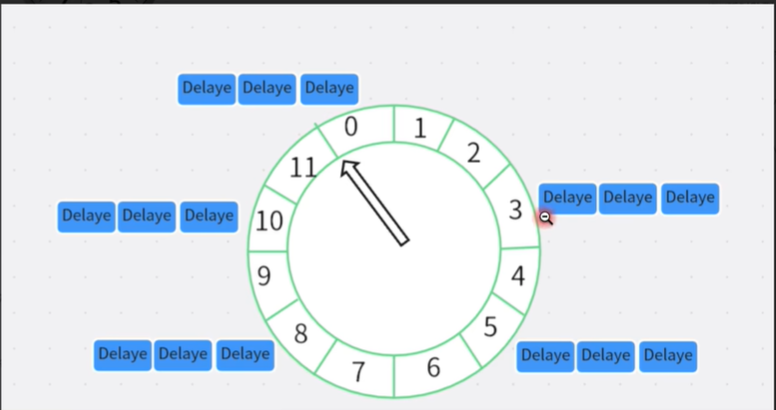
核心参数有如下几个:
tickDuration 每个刻度代表的时长
ticksPerWheel 时间轮一圈有多少个刻度
round 执行到我们的任务,需要多少圈
那么我们要延时执行一个任务,就只需要给出任务需要执行的时间,然后通过计算得出执行到我们任务需要的圈数,和具体的刻度。
举个例子:
首先指针指在0处。
tickDuration = 1s,
ticksPerWheel = 12。
此时一圈就是12秒,
如果我们添加了一个25秒的任务。
任务需要的圈数:25/12=2
最后一圈执行任务的刻度:25%2=1
那么我们的任务就会在第二圈的刻度1处执行我们的任务。
这就是时间轮算法的执行原理。
实现
那么怎么在代码中实现呢,首先我们导入下面的依赖
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.58.Final</version>
</dependency>代码实现如下:
import io.netty.util.HashedWheelTimer;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
/**
* 时间轮算法
*/
public class TestNetty {
public static void main(String[] args) {
// 创建一个默认线程 tickDuration:一圈多少秒,ticksPerWheel:一圈多少刻度
HashedWheelTimer hashedWheelTimer = new HashedWheelTimer(Executors.defaultThreadFactory(),1, TimeUnit.SECONDS,12);
System.out.println("任务开始执行时间"+new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date()));
hashedWheelTimer.newTimeout(timeout -> System.out.println("13秒后输出:" + new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date())), 13, TimeUnit.SECONDS);
hashedWheelTimer.newTimeout(timeout -> System.out.println("23秒后输出:" + new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date())), 23, TimeUnit.SECONDS);
hashedWheelTimer.newTimeout(timeout -> System.out.println("25秒后输出:" + new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date())), 25, TimeUnit.SECONDS);
hashedWheelTimer.newTimeout(timeout -> System.out.println("5秒后输出:" + new SimpleDateFormat("yyyy-MM-dd hh:mm:ss").format(new Date())), 5, TimeUnit.SECONDS);
}
}
执行效果:

优点
效率高
代码复杂度低
缺点
服务器宕机数据会消失,需要考虑持久化
使用场景
HashedWheelTimer本质是一种类似延迟任务队列的实现,那么它的特点如上所述,适用于对时效性不高的,可快速执行的,大量这样的“小”任务,能够做到高性能,低消耗。
应用场景大致有:
心跳检测(客户端探活)
会话、请求是否超时
消息延迟推送
业务场景超时取消(订单、退款单等)
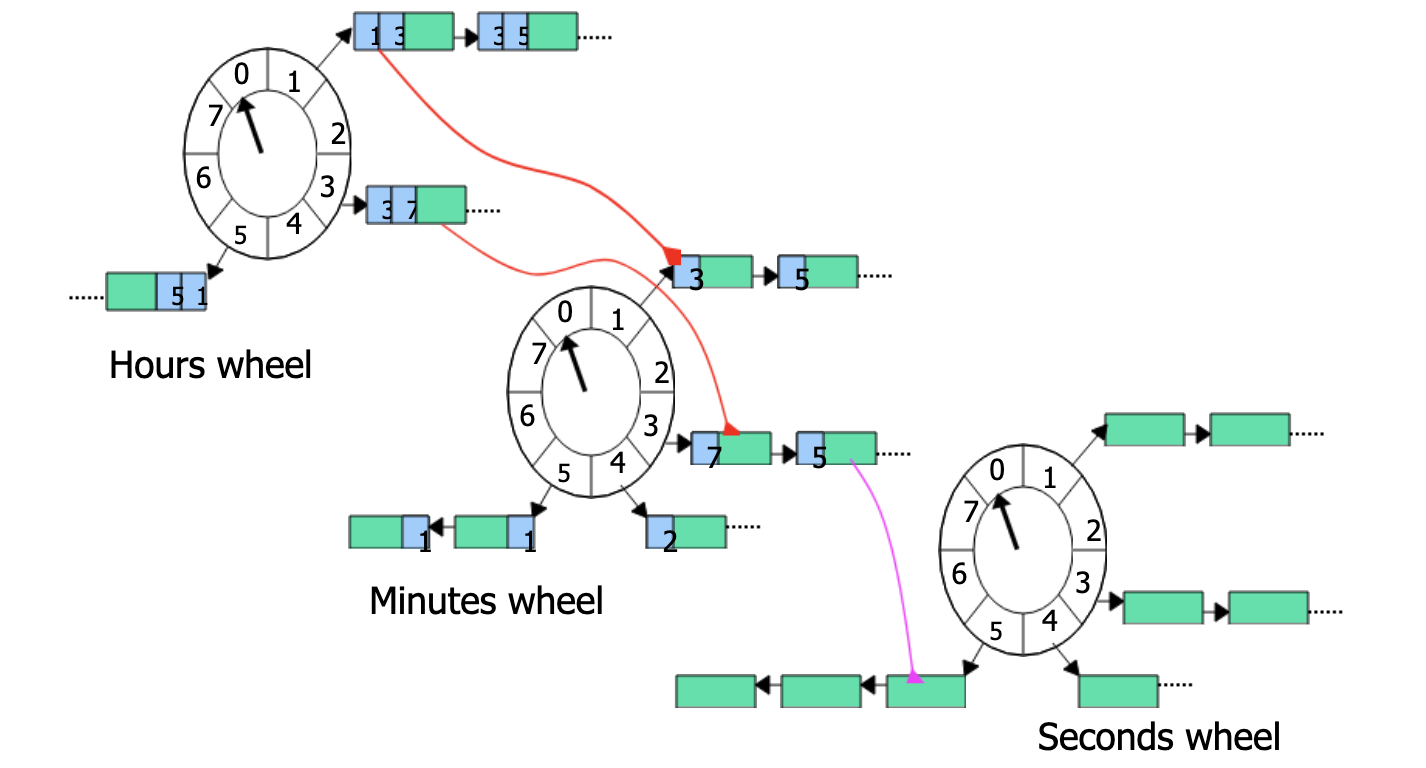
多重时间轮
当时间跨度很大时,提升单层时间轮的 tickDuration 可以减少空转次数,但会导致时间精度变低,层级时间轮既可以避免精度降低,又避免了指针空转的次数。如果有时间跨度较长的定时任务,则可以交给层级时间轮去调度。

















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









