







 本文介绍了在使用Python3的urllib模块爬取中文网址时遇到的UnicodeEncodeError,提供了解决方案:一是单独对中文部分进行编码,二是设置safe参数确保不编码特定字符。通过实例代码展示了两种方法的使用。
本文介绍了在使用Python3的urllib模块爬取中文网址时遇到的UnicodeEncodeError,提供了解决方案:一是单独对中文部分进行编码,二是设置safe参数确保不编码特定字符。通过实例代码展示了两种方法的使用。
参考:[Python3填坑之旅]一·urllib模块网页爬虫访问中文网址出错
目录
六、其他UnicodeEncodeError: 'ascii' codec 问题
一、报错内容
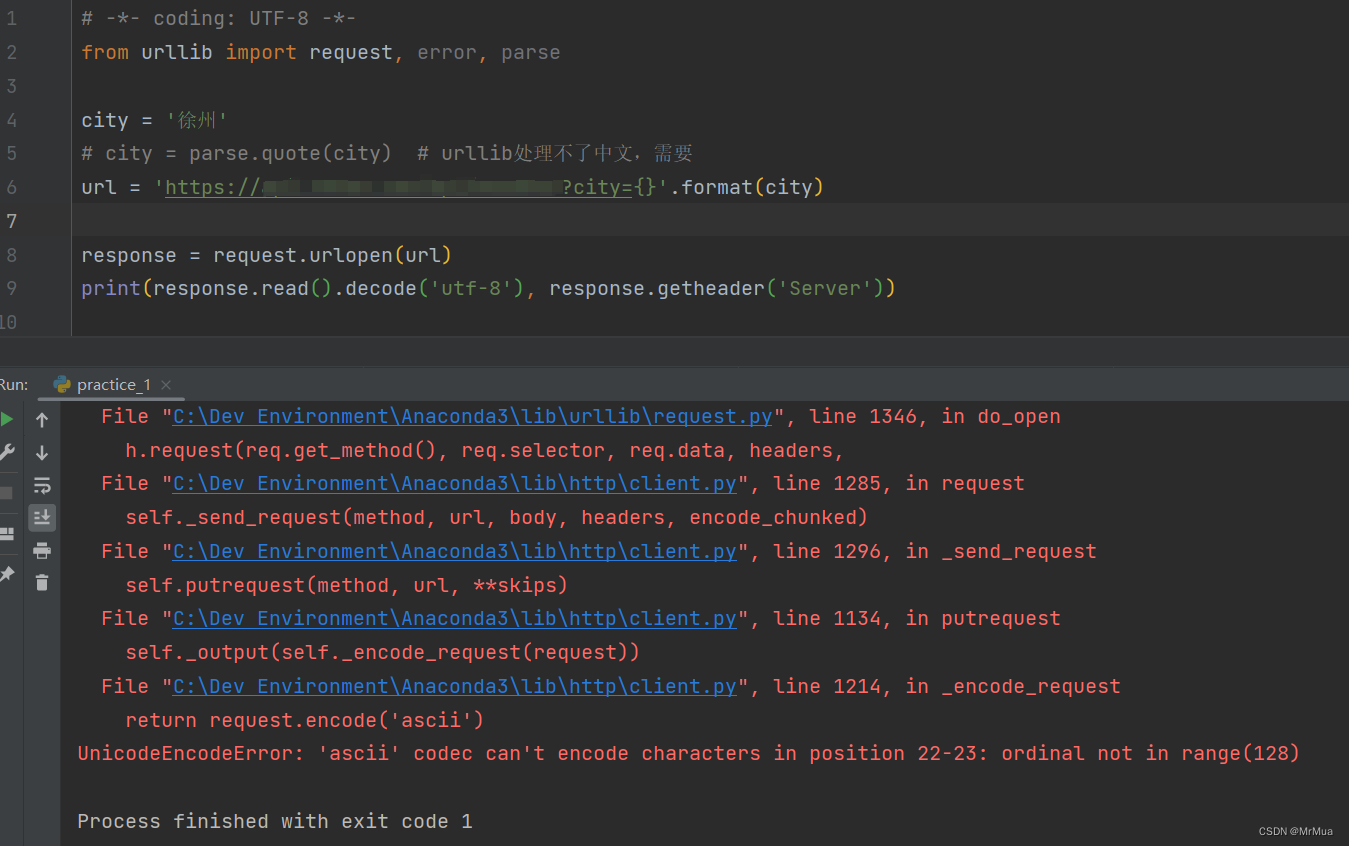
UnicodeEncodeError: 'ascii' codec can't encode characters in position 22-23: ordinal not in range(128)
二、报错截图
三、解决方法
字母、数字和 '_.-~' 等字符一定不会被转码。 在默认情况下,此函数只对 URL 的路径部分进行转码。 可选的 safe 形参额外指定不应被转码的 ASCII 字符,其默认值为 '/'。--Python官方文档
1、urllib解析含中文的url时,单独编码中文部分,最后拼接
# -*- coding: UTF-8 -*-
from urllib import request, error, parse
city = '徐州'
city = parse.quote(city) # urllib处理中文,需要编码
url = 'https://***.***.com/api?city={}'.format(city)2、直接对url整体中的中文进行编码,默认不对/字母编码,但会对url中的:=?空格等编码
url = 'https://***.***.com/api?city=徐州'
url = parse.quote(url, safe='/:=?') # urllib处理中文,需要编码四、实例代码
1、单独处理中文编码
# -*- coding: UTF-8 -*-
from urllib import request, error, parse
city = '徐州'
city = parse.quote(city) # urllib处理中文,需要编码
url = 'https://***.***.com/api?city={}'.format(city)
response = request.urlopen(url)
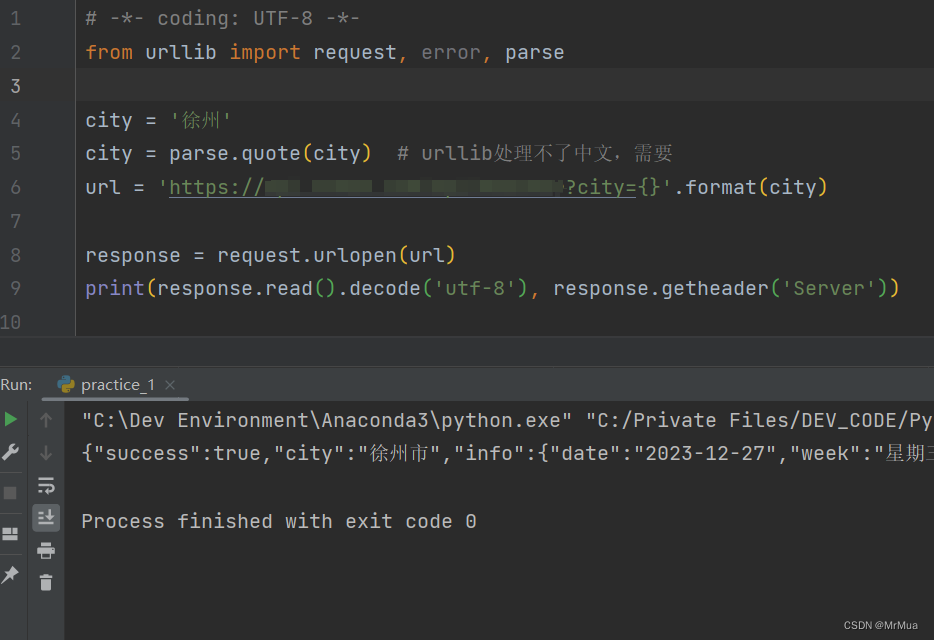
print(response.read().decode('utf-8'), response.getheader('Server'))2、处理整体url
# -*- coding: UTF-8 -*-
from urllib import request, error, parse
url = 'https://***.***.com/api?city=徐州'
url = parse.quote(url, safe='/:=?') # urllib处理中文,需要编码
response = request.urlopen(url)
print(response.read().decode('utf-8'), response.getheader('Server'))五、运行截图
六、其他UnicodeEncodeError: 'ascii' codec 问题
参考:
https://blog.youkuaiyun.com/u011331731/article/details/89400702

















 5861
5861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









