







 本文介绍了使用Python爬虫爬取名著小说的步骤,从找到目标网站开始,解析目录URL,再到提取每一章节的URL及内容。通过requests和BeautifulSoup库,成功获取了小说的全部目录和内容,实现了一个简单的网络小说爬虫。
本文介绍了使用Python爬虫爬取名著小说的步骤,从找到目标网站开始,解析目录URL,再到提取每一章节的URL及内容。通过requests和BeautifulSoup库,成功获取了小说的全部目录和内容,实现了一个简单的网络小说爬虫。
周末闲来无事,本来想看一看书的,结果也没看进去(RNG输的我真是糟心。。。)
于是就用python写了一个爬虫,来爬取小说来看,防止下次还要去网上找书看。
我们先找一个看名著的小说网
我们打开http://www.mingzhuxiaoshuo.com/ 名著小说网来,首先看到的是这样的
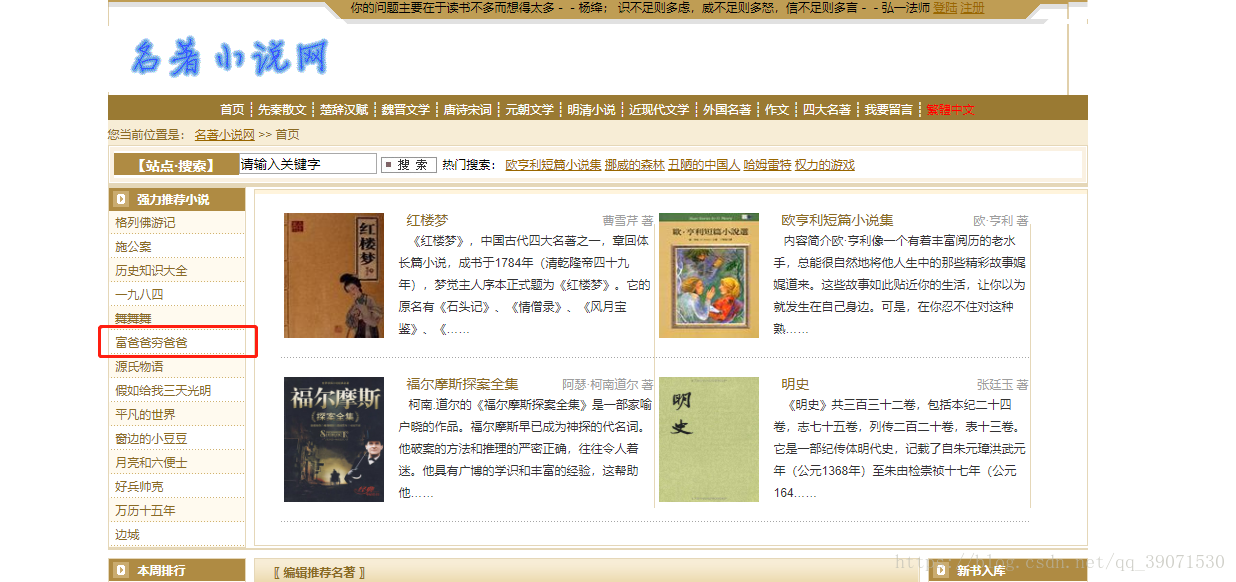
我们如上图选一个大家耳熟能详的书,《富爸爸穷爸爸》,我们点开来,点击在线阅读
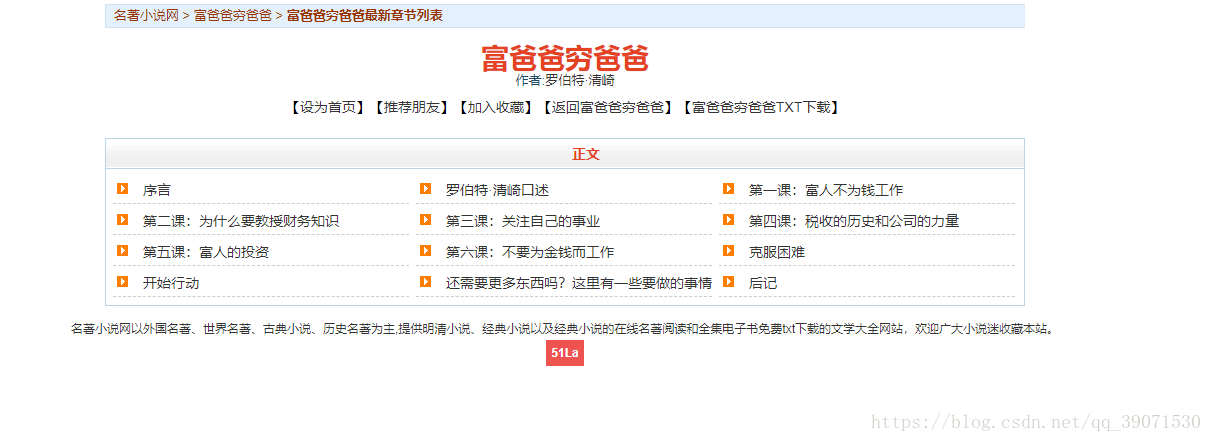
出现了这本书的目录,http://www.mingzhuxiaoshuo.com/waiguo/154/,这个url是我们首先爬取的网页,我们先将每一章节的url爬取出来。
我们打谷歌的开发工具 F12,去找本网站的目录规律
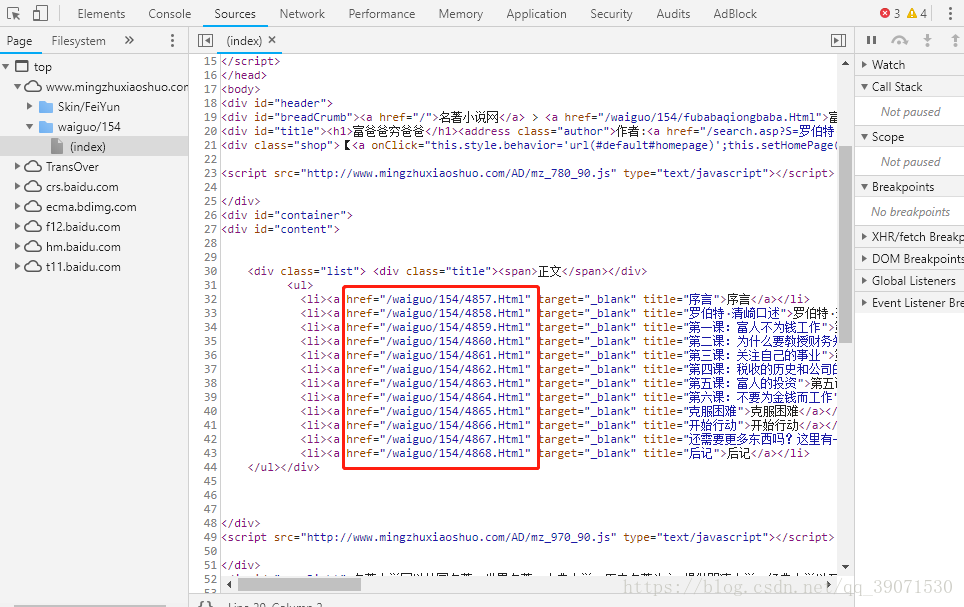
我们发现每一个目录都有一个href,我们
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3714
3714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









