






 本文详细介绍了如何使用Mycat实现数据库的分库分表和读写分离,基于主从配置进行设置,通过配置和测试,确保系统的高效运行。
本文详细介绍了如何使用Mycat实现数据库的分库分表和读写分离,基于主从配置进行设置,通过配置和测试,确保系统的高效运行。
前两篇文章分别讲解了分库分表 和主从配置
下面来介绍 分库分表+读写分离(基于主从配置)
简单的架构图:
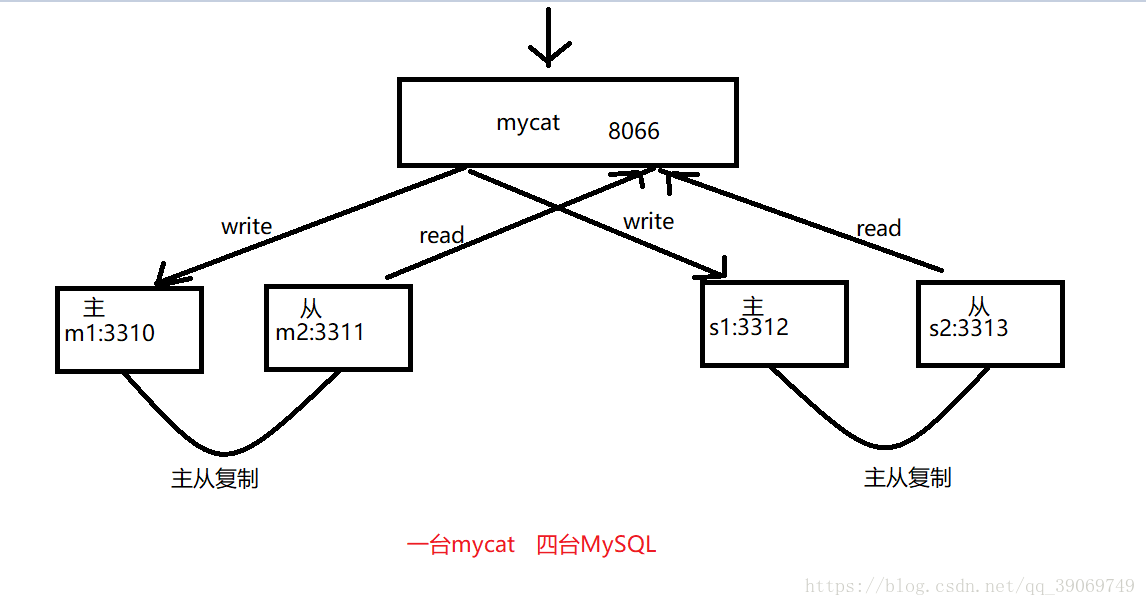
配置:
cd进入到mycat的conf目录下 查看 server.xml rule.xml schema.xml 三个配置文件
server.xml 与之前的配置基本没有变化
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useSqlStat">1</property>
<property name="useGlobleTableCheck">0</property>
<property name="sequnceHandlerType">2</property>
<property name="processorBufferPoolType">0</property>
<property name="handleDistributedTransactions">0</property>
<property name="useOffHeapForMerge">1</property>
<property name="memoryPageSize">1m</property>
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<property name="systemReserveMemorySize">384m</property>
<property name="useZKSwitch">true</property>
</system>
<user name="root">
<property name="password">123456</property>
<property name="schemas">m2</property>
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">m2</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
rule.xml 为了配合测试 新增了根据hash分片规则
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="sharding-by-murmur">
<rule>
<columns>order_id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是 0-->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片-->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟
节点,默认是 160 倍,也就是虚拟节点数是物理节点数的 160 倍-->
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
</mycat:rule>
schema.xml 新增加了一张order表
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 设置表的存储方式.schema name="TESTDB" 与 server.xml中的 TESTDB 设置一致 -->
<schema name="m2" checkSQLschema="false" sqlMaxLimit="100">
<table name="users" primaryKey="id" dataNode="node_db01,node_db02" rule="mod-long" />
<table name="order" primaryKey="id" dataNode="node_db01,node_db02" rule="sharding-by-murmur"/>
</schema>
<!-- 设置dataNode 对应的数据库,及 mycat 连接的地址dataHost -->
<dataNode name="node_db01" dataHost="dataHost01" database="m2" />
<dataNode name="node_db02" dataHost="dataHost02" database="m2" />
<!-- mycat 逻辑主机dataHost对应的物理主机.其中也设置对应的mysql登陆信息 -->
<dataHost name="dataHost01" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="m1" url="127.0.0.1:3310" user="root"
password="123456">
<readHost host="m2" url="127.0.0.1:3311" user="root"
password="123456"/>
</writeHost>
</dataHost>
<dataHost name="dataHost02" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="s1" url="127.0.0.1:3312" user="root"
password="123456">
<readHost host="s2" url="127.0.0.1:3313" user="root"
password="123456"/>
</writeHost>
</dataHost>
</mycat:schema>
这里提一点 比较前面分库分表的配置 我们这里改动的配置又以下几点:
1.新增一张按照hash分片的order表
DROP TABLE IF EXISTS `order`;
CREATE TABLE `order` (
`id` int(11) NOT NULL,
`order_id` varchar(64) DEFAULT NULL,
`name` varchar(64) DEFAULT NULL,
`price` decimal(10,0) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.为了实现分库分表+读写分离 配置了俩个dataHost节点 节点中均有writeHost和readHost节点配置读路径与写路径
3.balance属性改为了3
负载均衡类型,目前的取值有 3种:
1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost上。
2. balance="1",全部的readHost与 stand by writeHost 参与 select语句的负载均衡,简单的说,当双
主双从模式(M1->S1,M2->S2,并且 M1与 M2互为主备),正常情况下,M2,S1,S2都参与 select语句的负载
均衡。
3. balance="2",所有读操作都随机的在writeHost、readhost上分发。
4. balance="3",所有读请求随机的分发到wiriterHost对应的readhost执行,writerHost 不负担读压
力,注意balance=3只在1.4及其以后版本有,1.3没有。
4。switchType属性改为了 -1(自己选择哦)
-1 表示不自动切换
1 默认值,自动切换
2 基于MySQL主从同步的状态决定是否切换
心跳语句为 show slave status
3 基于MySQL galary cluster的切换机制(适合集群)(1.4.1)
心跳语句为 show status like ‘wsrep%’.
到此,mycat配置已经完了 使用cmd进入bin目录 运行startup_nowrap.bat
测试
首先将conf目录下的log4j2.xml中level级别改为debug 方便查看sql执行的节点
1.使用mavicat连接mycat
2.插入两条数据
INSERT INTO `order`(id,order_id,name,price) VALUES(1,'123abc','木头',13.1)
INSERT INTO `order`(id,order_id,name,price) VALUES(3,'321efd','木头',13.1)
我们查看 debug信息


我们可以看到分库分表是没有问题的 写入的节点都是我们定义好的wirteHost
查询
SELECT * FROM `order`;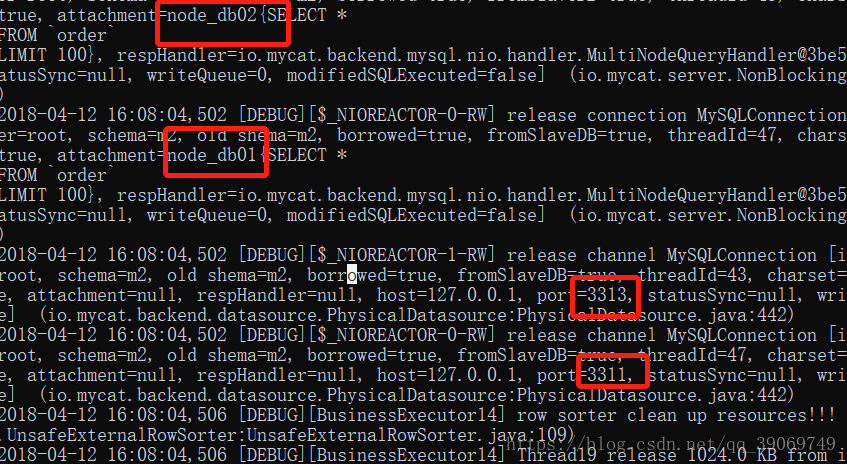
我们可以看到 查询的时候 走的是我们定义的readHost中的节点
如此 大功告成!!!

















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









