




 本文详细介绍了如何搭建Hadoop的伪分布式平台,包括Hadoop的安装、配置环境变量、修改配置文件、设置SSH无密码登陆、关闭防火墙、格式化文件系统以及启动和检查进程。通过这些步骤,读者可以成功在本地环境中运行Hadoop。
本文详细介绍了如何搭建Hadoop的伪分布式平台,包括Hadoop的安装、配置环境变量、修改配置文件、设置SSH无密码登陆、关闭防火墙、格式化文件系统以及启动和检查进程。通过这些步骤,读者可以成功在本地环境中运行Hadoop。
Hadoop 是什么?
- haddop是开源的分布式存储,和分布式计算平台
- Java编写的开源系统,能够安排在大规模的计算平台上,从而提高计算效率
- http://hadoop.apache.org
Hadoop核心组件:
- Hbase:Nosql数据库 Key-Value存储
- HDFS:分布式文件存储系统,存储海量数据
- MapReduce:并行处理框架,实现任务分解和调度,主要用来做数据的分析 (不是谷歌发明的,是谷歌用的)
Hadoop可以用来做什么?
- 搭建大型数据仓库,PB级数据存储、处理、分析、统计等业务
Hadoop基础理论:
- HDFS的文件被分成块进行存储,块的默认大小64MB,块是文件存储处理的逻辑单元,每个块默认大小64MB
- 每个区块至少分配到三台DataNode上(默认三台)
- HDFS中有两类节点,NameNode和DataNode。
- NameNode是管理节点,存放文件元数据,1. 文件与数据块的映射表,2.数据块与数据节点的映射表。
- DateNode是HDFS的工作节点,存放数据块。
Hadoop的安装
1.安装Hadoop
-官网找到Hadoop压缩文件
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.6/
我下载的是:hadoop-2.7.6.tar.gz
-执行:tar -zxvf 文件名.tar.gz -C 指定路径 //解压到指定路径
-配置环境变量:
vim /etc/profile 添加如下语句:
export HADOOP_HOME=hadoop安装目录
export PATH=$PATH:$HADOOP_HOME/bin
-保存,然后输入 source /etc/profile 使其生效
-命令行输入: hadoop
有东西输出说明hadoop安装成功,环境变量已经配置完成
**2.安装JDK**
-同上安装hadoop一样,解压之后配置环境变量
-vim /etc/profile 添加如下语句:
export JAVA_HOME=JDK安装目录
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
-保存,然后输入 source /etc/profile 使其生效
-命令行输入: java -version
有东西输出说明jdk安装成功,环境变量已经配置完成
3.修改相应的配置文件
-修改1:hadoop目录下的etc/hadoop/hadoop-env.sh 文件,将其中的JAVA_HOME改为jdk安装目录,我们的jdk安装目录为/home/navy/jdk1.8.0_162

-修改2:修改hadoop中etc/hadoop/目录下的core-site.xml文件。
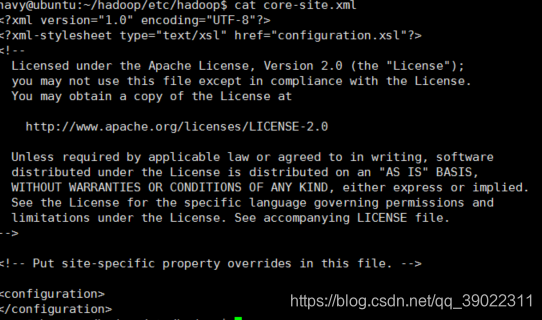
在< configuration >中添加如下配置
(1)添加指定中间数据文件存放目录的配置。
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop-2.7.6/tmp</value>
</property>
//tmp目录是hadoop存放文件的临时目录,如果不进行指定的话,它将会跟随着计算机的每次重启而删除,
为了不引起没必要的数据丢失,自己创建一个tmp文件夹来存储文件
(2)添加指定默认文件系统名称的配置。即,请求这个hdfs的URL地址。
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
//后期如果需要连接服务器或者虚拟机的话,就将localhost改为对应的地址
添加完后,使用cat命令查看该文件信息,如下图所示:
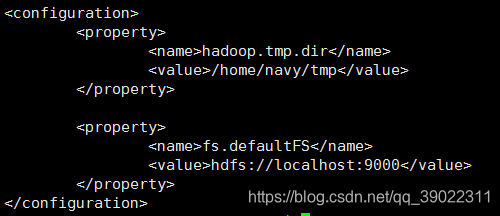
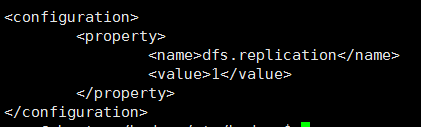
-修改3:修改hadoop中etc/hadoop目录下的hdfs-site.xml文件。
打开hdfs-site.xml文件,在< configuration >< /configuration >标签中添加如下代码:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
这个是用来指定hdfs的副本数的,默认值为3。现在我们用的是伪分布式,没有那么多副本节点,所以我们将其改为1。
修改完成后:
4.设置ssh 无密码登陆
现在当我们每次使用ssh localhost访问的时候,都需要输入密码。此时我们可以改成无密码登录。首先退出root用户,到普通用户。然后执行 ssh-keygen -t rsa(使用rsa加密,还有一种方式是dsa)命令生成密钥。执行后会在用户登录目录下生成.ssh目录和id_rsa、id_rsa.pub个文件,如下图所示:

将生成的公钥加入到许可文件中,即将公钥复制到 .ssh/authorized_keys中,这样登录就不需要密码了。执行命令 cp id_rsa.pub authorized_keys,完成后.ssh目录中的文件如下:

5.关闭防火墙
查看防火墙状态:sudo ufw status
关闭防火墙:sudo ufw disable
开启防火墙:sudo ufw enable
6.准备打开hadoop
- 格式化文件系统。执行hadoop中bin目录下的hdfs namenode -format 指令即可。
- 开启节点守护进程。执行hadoop 中sbin 目录下的start-dfs.sh 指令即可。
- 使用jps查看进程启动情况,如下图所示
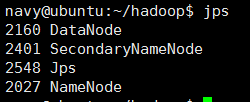
当 NameNode DataNode都存在时,才可。
7.查看
在浏览器中输入http://<hadoop服务器IP地址>:50070,如:http://192.168.65.129:50070能看到启动进程页面,说明搭建成功。页面如下:
如果不知道虚拟机的ip地址,可以输入命令:ifconfig查看

















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









