










最近一直在爬当当网相关数据。首先我们想要爬取图书排行榜
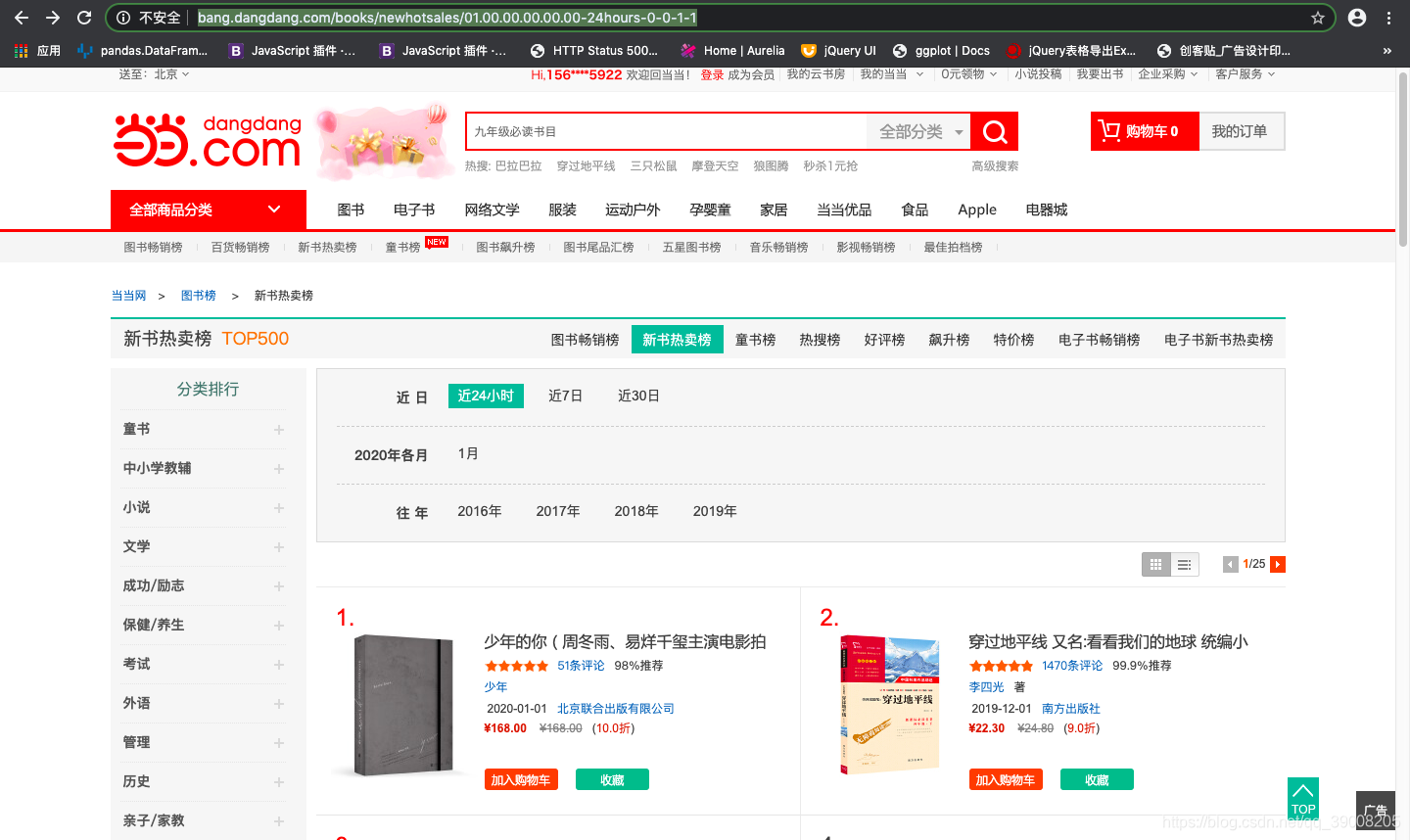
- 我们分析一下网址
http://bang.dangdang.com/books/newhotsales/01.00.00.00.00.00-24hours-0-0-1-1
最后的01.00.00.00.00.00-24hours-0-0-1-1 是什么我们选择的最近24小时。如果换成最近七日就变成了01.00.00.00.00.00-recent7-0-0-1-1 - 我们可以看到它的分页是20本书,每20本一分页。我们要太多也没有用。如果想爬多页怎么办那?我们点击下一页,观察网址的变化:
http://bang.dangdang.com/books/newhotsales/01.00.00.00.00.00-recent7-0-0-1-2
可以发现最后的7-0-0-1-( ),括号位置发生了变化。我们猜一下第三页是什么样的:http://bang.dangdang.com/books/newhotsales/01.00.00.00.00.00-24hours-0-0-1-3
不说废话了,我们今天只爬一页。
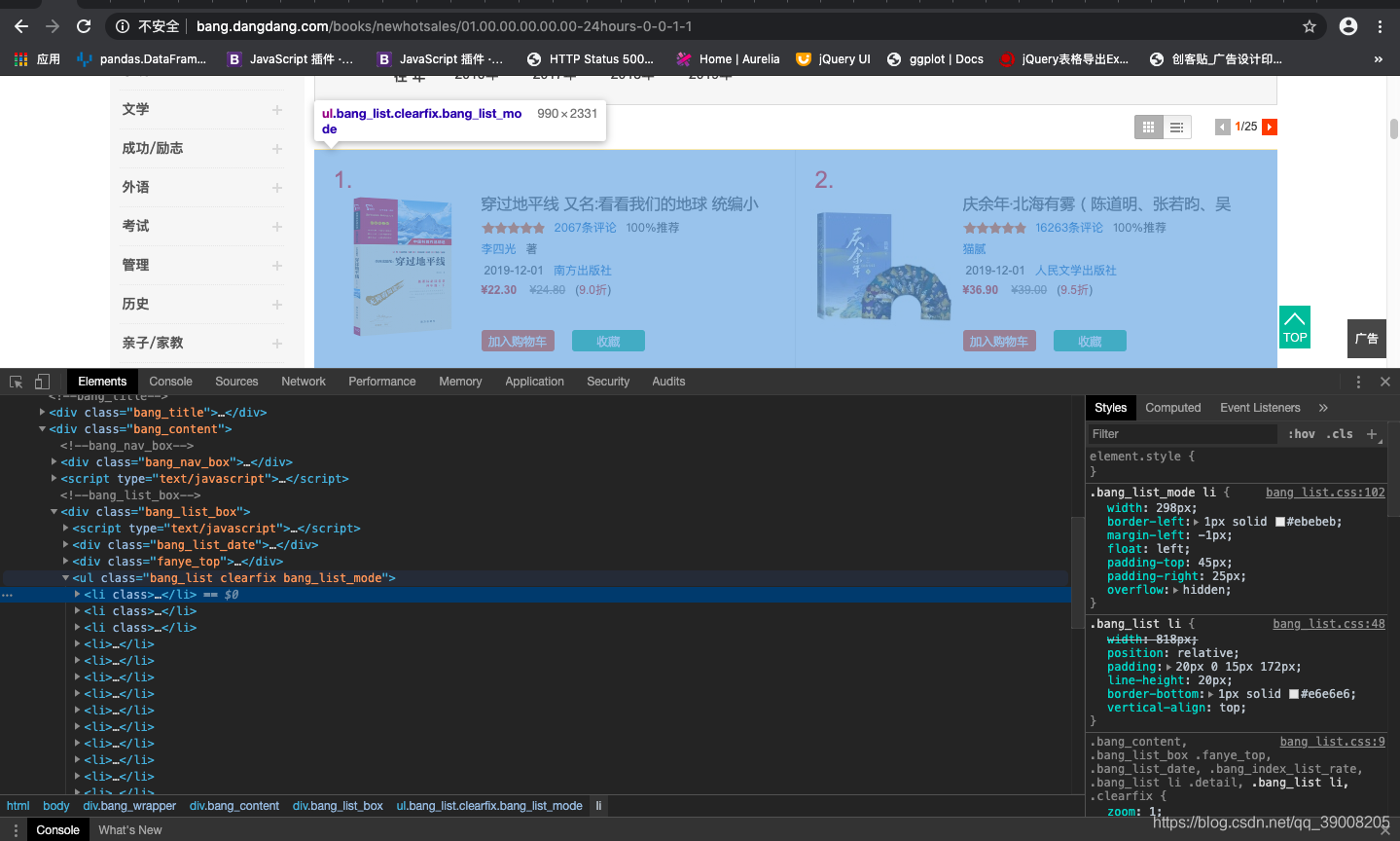
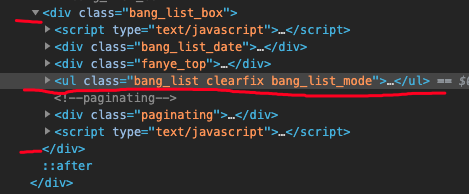
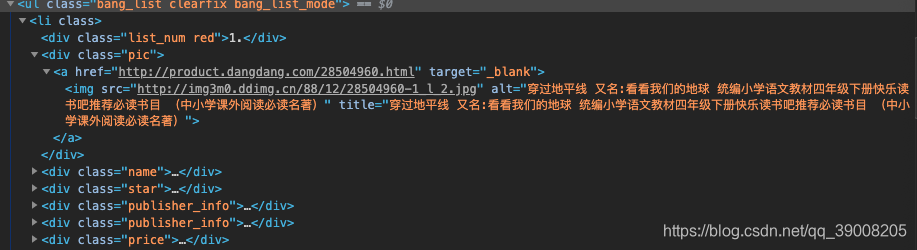
所有的我们想要的图书信息都在class为bang_list_box的div标签下的ul标签下的li标签,每一个li里都有一本书的信息。
from lxml import etree
import requests
def spider():
url='http://bang.dangdang.com/books/bestsellers/'
html = requests.get(url).text
xpath_object = etree.HTML(html,etree.HTMLParser())
result = xpath_object.xpath('//div[@class="bang_list_box"]/ul/li') #list
for li in result:
num = li.xpath("div[@class='list_num ' or @class='list_num red']/text()")
img = li.xpath("div[@class='pic']/a/img/@src")
title = li.xpath("div[@class='pic']/a/img/@title")
star = li.xpath("div[@class='star']/span/span/@style")
comment_num = li.xpath("div[@class='star']/a/text()")
comment_href= li.xpath("div[@class='star']/a/@href")
comment_hrefs = "".join(comment_href)
publisher_info = li.xpath("div[@class='publisher_info'][1]/a/text()")
publish_date = li.xpath("div[@class='publisher_info']/span/text()")
publish_company = li.xpath("div[@class='publisher_info'][2]/a/text()")
price_n = li.xpath("div[@class='price']/p[1]/span[@class='price_n']/text()")
price_r = li.xpath("div[@class='price']/p[1]/span[@class='price_r']/text()")
price_e = li.xpath("div[@class='price']/p[@class='price_e']/span[@class='price_n']/text()")
if __name__ == '__main__': #主函数注意下缩紧
spider()
我用的是requests库,也可以用urllib的request库。但我觉得requests库更简单些。
步骤:
- 通过requests的get方法请求网址,获得整个网页的html
- 通过lxml的etree方法将html解析成xpath对象
- 对应找到每个li标签
- 用for循环循环每个li标签
- xpath写出想要的数据
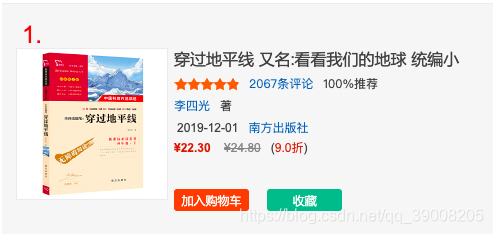
num:书的排名序号,前三本书和后面的class名不同,所以我用的or
img:图片的网址对应这src属性
star:style属性的宽度对应着星星的个数。得到的是width: 98.8%;我们在存入数据库的时候在用截取字符串活着正则匹配就可以获得想要的这个98.8%了。
我们的得到的这些都是list列表数据类型。
comment_hrefs = "".join(comment_href)此方法可以将列表转换为我们需要的字符串。
如果想将价格转换为float类型再存入数据库,我直接用float方法强转报错

那么我们自己些个转换成float类型的方法
from functools import reduce
def StrToFloat(s):
l=s.split('.')
return reduce(lambda x,y:int(x)+int(y)/10**len(y),l)
- 我们接下来爬相关的评论信息:
评论数对应的超链接就是我们想要爬的评论信息的网址:
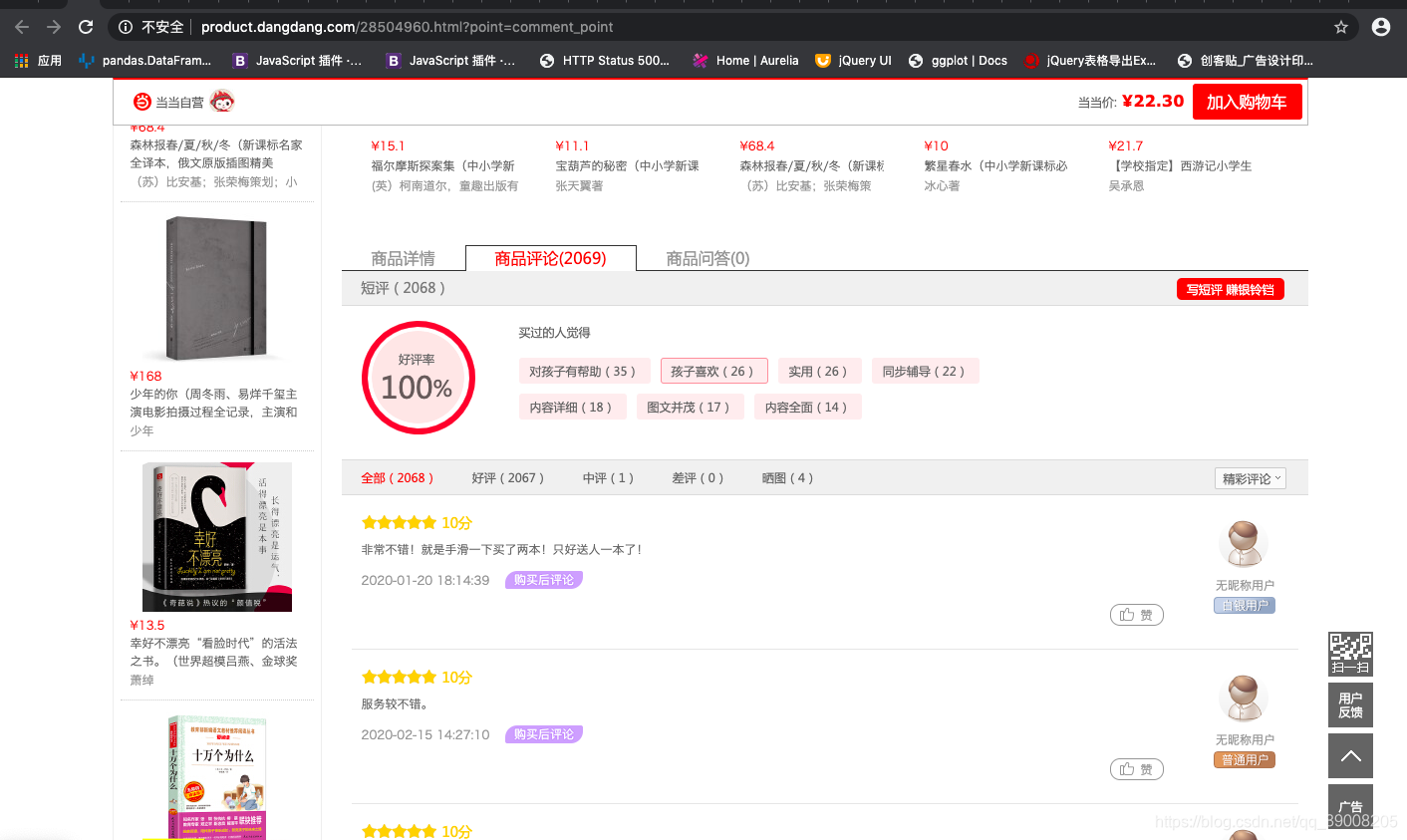
我想要爬到好评率还有商品评论的标签。我按照之前的xpath方式爬到的都是空值。我又换了BeautifulSoup爬到的还是空值。
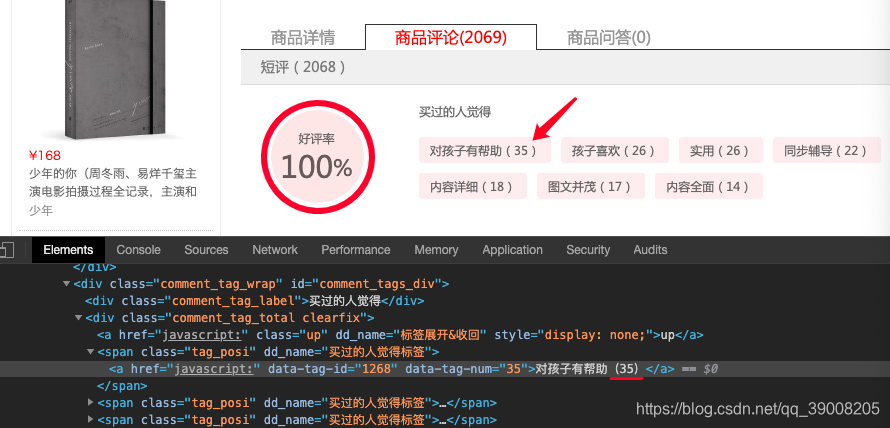
我看到页面上还有审查元素的代码中都是有值的,并不是空。但是就是爬不到相应的数据。
我将爬到的html文件输出到文本当中才发现html文件中并没有我们想要的
#读写文件
f = open('ab.txt','w+')
f.write('%s'%comment_html)
<div class="comment_tag_wrap" id="comment_tags_div"></div>
<!-- <div class="comment_chart_list">对已购商品写评论<a type="button" id = 'writeCutComment' class="btn_red" dd_name="写评论入口">写短评 赚银铃铛</a></div> -->
</div>
<div class="comment_body" ddt-area="comment_body" ddt-expose="on">
<div class="comment_tabs">
<!-- 评论数 -->
<div class="clearfix comment_tabs_wrap" id="comment_num_tab">
<span class="on" data-type="1" dd_name="全部评论" onclick="true">全部</span>
<span data-type="2" dd_name="好评" onclick="true">好评</span>
<span data-type="3" dd_name="中评" onclick="true">中评</span>
<span data-type="4" dd_name="差评" onclick="true">差评</span>
<span data-type="5" dd_name="晒图评论" onclick="true">有图评论</span>
</div>
<div class="comment_sort " id="comment_sort">
<i class="icon"></i>
<span class="pl02">精彩评论</span>
<ul>
<li><a href="javascript:" dd_name="精彩评论排序">精彩评论</a></li>
<li><a href="javascript:" dd_name="时间排序">时间排序</a></li>
</ul>
</div>
</div>
id为comment_tags_div的div中是空的
我们在看看好评数、差评数,对应的代码中只有文字没有数字那么到底为什么?

- 后来我开始看network的请求
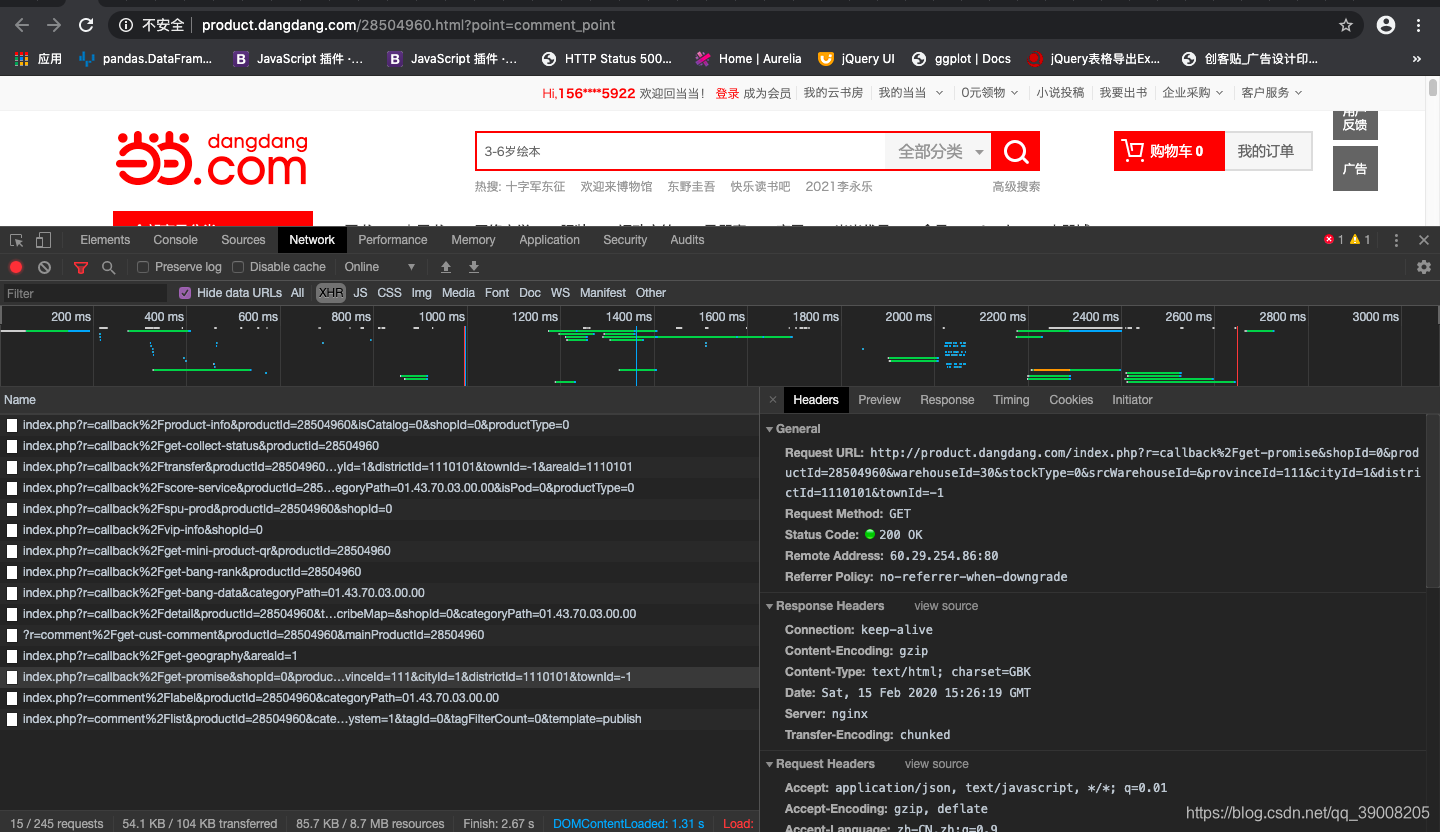
很有可能请求的ajax。我看了它请求的每个文件
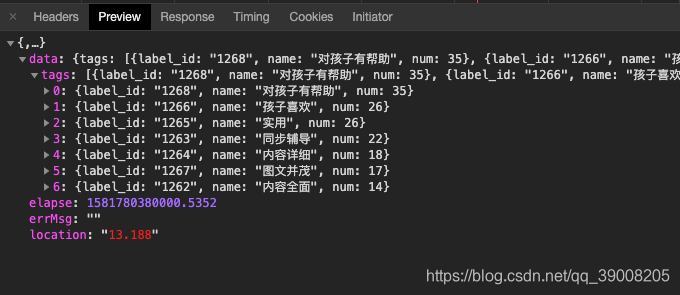
终于找到了,果然是ajax请求的json文件 - 请求的网址为
http://product.dangdang.com/index.php?r=comment%2Flabel&productId=28504960&categoryPath=01.43.70.03.00.00
我们发现它传递了三个参数 r , productId和categoryPath
我们可以用postman模拟下请求看看传三个参数可不可以
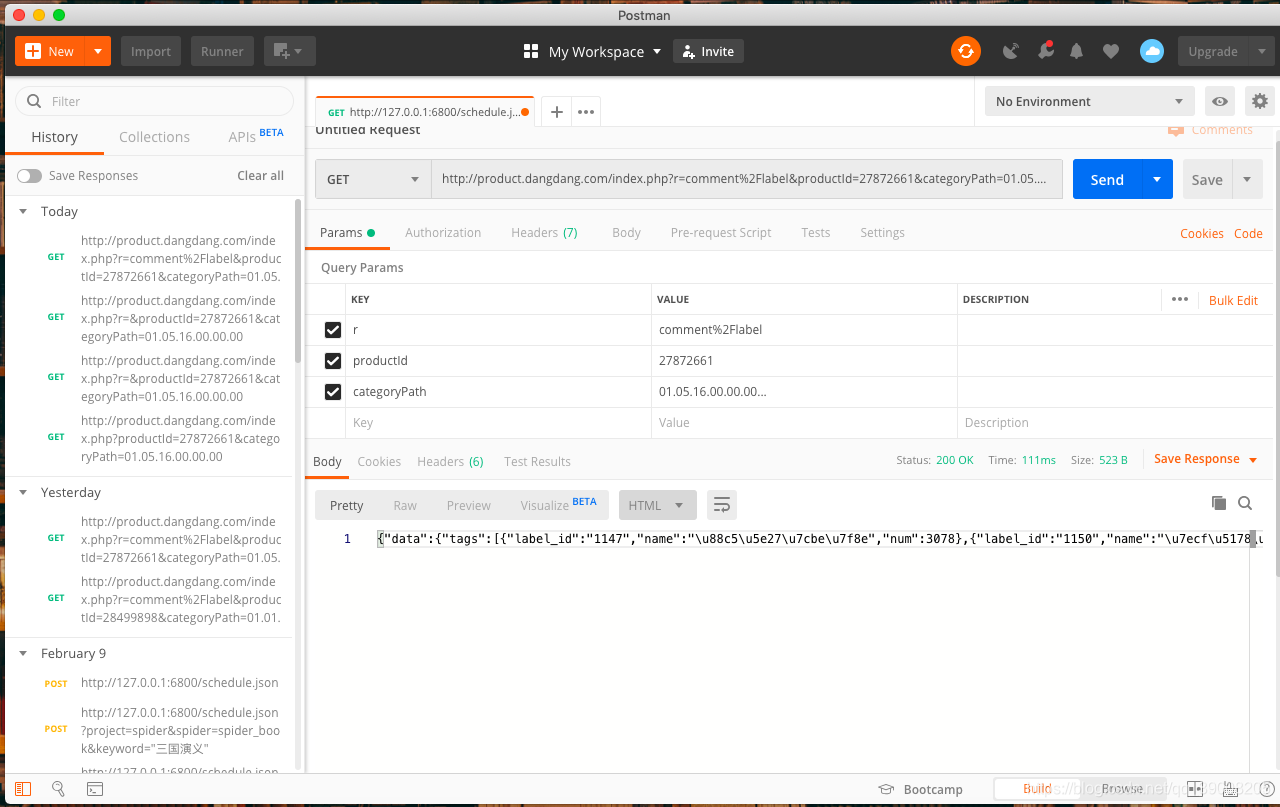
如图我们传递三个参数后获得了数据 - 我们传递这三个参数不能写死,要动态获取,那怎么办那?
我们再去看看输出的html中能不能找到每页都对应的这三个参数
我在js代码中找到了我们想要的三个中的两个参数
这样看着不清晰我们转换成惊悚数据看看
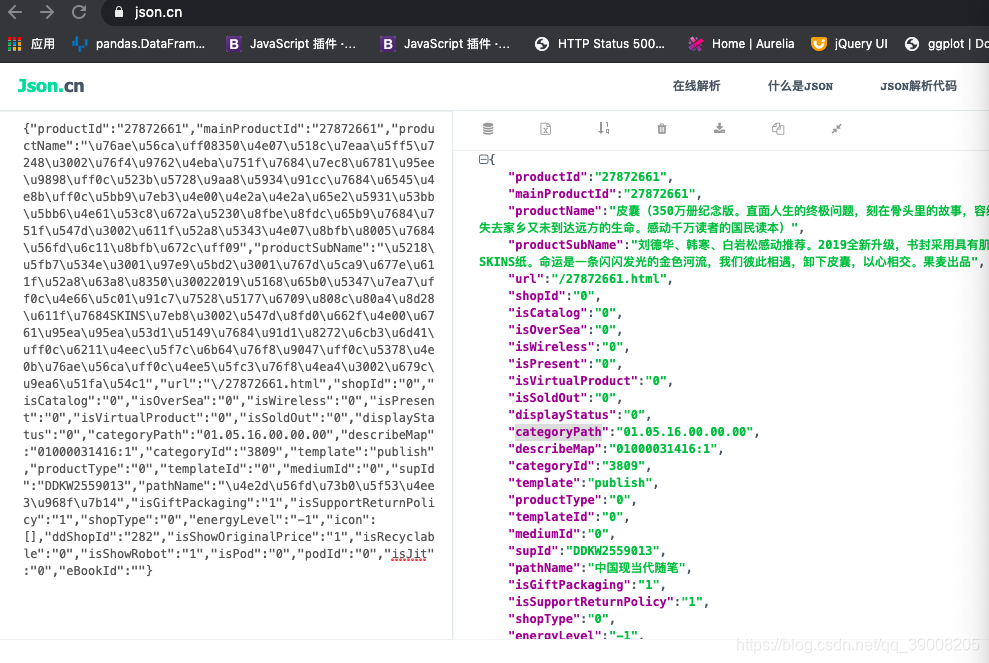
如图:productId 和categoryPath对应的值就是我们需要的参数。那另一个参数怎么办那?
我看了几个之后发现,每个页面传递的r参数对应的值都是‘comment%2Flabel’ - 接下来
from urllib.parse import urlencode
import re
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Connection': 'keep-alive',
'Host': 'product.dangdang.com',
'Cookie':'ddscreen=2; __permanent_id=20191226212500804616435824430929787; MDD_channelId=70000; MDD_fromPlatform=307; NTKF_T2D_CLIENTID=guest7DD800D3-9D6C-FAD2-F447-4491A1AB045C; permanent_key=20191231094316855241971031298c57; login_dang_code=20191231094358215658251164eabb96; dangdang.com=email=MTU2OTQxNDU5MjIzNTUwNUBkZG1vYmlscGhvbmVfX3VzZXIuY29t&nickname=&display_id=3042420451630&customerid=Gm+hJ6C967mkV/H5e69RuQ==&viptype=kGYygxOYquw=&show_name=156%2A%2A%2A%2A5922; ddoy=email=1569414592235505%40ddmobilphone__user.com&nickname=&agree_date=1&validatedflag=0&uname=15694145922&utype=1&.ALFG=on&.ALTM=1577756911; deal_token=11a5ef72a8271691706cb7f548582b4be0833d99f6b8cb8635da0e27aef05bfbbc8a47ea8d05483391; LOGIN_TIME=1578288900466; pos_1_start=1578581238955; pos_1_end=1578581238964; _jzqco=%7C%7C%7C%7C%7C1.903190947.1578581553369.1578581553369.1578581553369.1578581553369.1578581553369.0.0.0.1.1; from=460-5-biaoti; order_follow_source=P-460-5-bi%7C%231%7C%23sp0.baidu.com%252F9q9JcDHa2gU2pMbgoY3K%252Fadrc.php%253Ft%253D06KL00c00fZ-jkY0jSwh0KGwAs0BzHqX00000200mdC00000LvNOis%7C%230-%7C-; __ddc_15d_f=1581238638%7C!%7C_utm_brand_id%3D11106; __ddc_15d=1581303323%7C!%7C_utm_brand_id%3D11106; __dd_token_id=20200210113139498284657440b6cdc0; login.dangdang.com=.AYH=2020021011313902393116236&.ASPXAUTH=; pos_9_end=1581305594375; pos_0_end=1581305594410; pos_0_start=1581305597390; dest_area=country_id%3D9000%26province_id%3D111%26city_id%3D1%26district_id%3D1110101%26town_id%3D-1; nTalk_CACHE_DATA={uid:dd_1000_ISME9754_guest7DD800D3-9D6C-FA,tid:1581403494064314}; __visit_id=20200212202346464138979607734227221; __out_refer=; priceab=b; producthistoryid=28473192%2C27907090%2C28497063%2C28499898%2C28480229%2C28507820%2C28500236%2C28490031%2C28470981%2C28508847; pos_6_start=1581512545847; pos_6_end=1581512545860; __rpm=%7Cp_28473192.029..1581512546326; __trace_id=20200212210708740312605248881972107',
#'Referer': '',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
url_a1 ='http://product.dangdang.com/index.php?'
comment_html = requests.get(comment_hrefs,headers=header).text
productId=re.findall(r'"productId":"(.*?)"',comment_html)
productId_str = "".join(productId)
categoryPath = re.findall(r'"categoryPath":"(.*?)"',comment_html)
categoryPath_str = "".join(categoryPath)
r = "comment2Flabel"
parm ={
'r' : r,
'productId' : productId_str,
'categoryPath' : categoryPath_str
}
#构造ajax请求url
ajax_url = url_a1 + urlencode(parm)
aj = ajax_url.replace('comment','comment%')
#调用ajax请求
response = requests.get(aj, headers=header)
#print(response)
#ajax请求返回的是json数据,通过调用json()方法得到json数据
json = response.json()
data=json.get('data')
先模拟请求头,请求头对应的键值都在headers中找
url_a1:是我们请求的目标网址
comment_html :通过requests的get方法请求到的html
productId :通过正则表达式找到js中我们想要的productId值
productId_str :将productId转换成字符串类型
parm :要传递的参数
然后构造ajax请求。
有一点要注意:用urlencode方法之后,将我们的所有参数都进行了转义
urllib库里面有个urlencode函数,可以把key-value这样的键值对转换成我们想要的格式,返回的是a=1&b=2这样的字符串,比如:
>>> from urllib import urlencode
>>> data = { ... 'a': 'test', ... 'name': '魔兽' ... }
>>> print urlencode(data) a=test&name=%C4%A7%CA%DE
我遇到了什么问题那?它将comment%2Flabel中的‘%’转义成了25
http://product.dangdang.com/index.php?r=comment%2Flabel&productId=28512571&categoryPath=01.01.01.00.00.00`在这里插入代码片`
http://product.dangdang.com/index.php?r=comment%252Flabel&productId=28473192&categoryPath=01.05.17.00.00.00
搞得我很懵,为什么会出来个25那?百度半天才知道对应的转义字符的值是25。
因此我们在后面urlencode之后再对url进行处理将comment替换成comment%
- 还需要写一个ajax请求次数的方法
def ajax_f():
#调用ajax的次数,这里调用5次。
for offset in (range(0,5)):
parse_ajax_web(offset*20)
- 最后我们得到了相应的json数据

完整代码
from lxml import etree
import requests
import pymysql
from bs4 import BeautifulSoup
from urllib.parse import urlencode
import re
from urllib import parse
from functools import reduce
import datetime
def StrToFloat(s):
l=s.split('.')
return reduce(lambda x,y:int(x)+int(y)/10**len(y),l)
def spider():
url='http://bang.dangdang.com/books/bestsellers/'
html = requests.get(url).text
xpath_object = etree.HTML(html,etree.HTMLParser())
result = xpath_object.xpath('//div[@class="bang_list_box"]/ul/li') #list
for li in result:
num = li.xpath("div[@class='list_num ' or @class='list_num red']/text()")
img = li.xpath("div[@class='pic']/a/img/@src")
title = li.xpath("div[@class='pic']/a/img/@title")
star = li.xpath("div[@class='star']/span/span/@style")
comment_num = li.xpath("div[@class='star']/a/text()")
comment_href= li.xpath("div[@class='star']/a/@href")
comment_hrefs = "".join(comment_href)
publisher_info = li.xpath("div[@class='publisher_info'][1]/a/text()")
publish_date = li.xpath("div[@class='publisher_info']/span/text()")
publish_company = li.xpath("div[@class='publisher_info'][2]/a/text()")
price_n = li.xpath("div[@class='price']/p[1]/span[@class='price_n']/text()")
price_r = li.xpath("div[@class='price']/p[1]/span[@class='price_r']/text()")
price_e = li.xpath("div[@class='price']/p[@class='price_e']/span[@class='price_n']/text()")
header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Connection': 'keep-alive',
'Host': 'product.dangdang.com',
'Cookie':'ddscreen=2; __permanent_id=20191226212500804616435824430929787; MDD_channelId=70000; MDD_fromPlatform=307; NTKF_T2D_CLIENTID=guest7DD800D3-9D6C-FAD2-F447-4491A1AB045C; permanent_key=20191231094316855241971031298c57; login_dang_code=20191231094358215658251164eabb96; dangdang.com=email=MTU2OTQxNDU5MjIzNTUwNUBkZG1vYmlscGhvbmVfX3VzZXIuY29t&nickname=&display_id=3042420451630&customerid=Gm+hJ6C967mkV/H5e69RuQ==&viptype=kGYygxOYquw=&show_name=156%2A%2A%2A%2A5922; ddoy=email=1569414592235505%40ddmobilphone__user.com&nickname=&agree_date=1&validatedflag=0&uname=15694145922&utype=1&.ALFG=on&.ALTM=1577756911; deal_token=11a5ef72a8271691706cb7f548582b4be0833d99f6b8cb8635da0e27aef05bfbbc8a47ea8d05483391; LOGIN_TIME=1578288900466; pos_1_start=1578581238955; pos_1_end=1578581238964; _jzqco=%7C%7C%7C%7C%7C1.903190947.1578581553369.1578581553369.1578581553369.1578581553369.1578581553369.0.0.0.1.1; from=460-5-biaoti; order_follow_source=P-460-5-bi%7C%231%7C%23sp0.baidu.com%252F9q9JcDHa2gU2pMbgoY3K%252Fadrc.php%253Ft%253D06KL00c00fZ-jkY0jSwh0KGwAs0BzHqX00000200mdC00000LvNOis%7C%230-%7C-; __ddc_15d_f=1581238638%7C!%7C_utm_brand_id%3D11106; __ddc_15d=1581303323%7C!%7C_utm_brand_id%3D11106; __dd_token_id=20200210113139498284657440b6cdc0; login.dangdang.com=.AYH=2020021011313902393116236&.ASPXAUTH=; pos_9_end=1581305594375; pos_0_end=1581305594410; pos_0_start=1581305597390; dest_area=country_id%3D9000%26province_id%3D111%26city_id%3D1%26district_id%3D1110101%26town_id%3D-1; nTalk_CACHE_DATA={uid:dd_1000_ISME9754_guest7DD800D3-9D6C-FA,tid:1581403494064314}; __visit_id=20200212202346464138979607734227221; __out_refer=; priceab=b; producthistoryid=28473192%2C27907090%2C28497063%2C28499898%2C28480229%2C28507820%2C28500236%2C28490031%2C28470981%2C28508847; pos_6_start=1581512545847; pos_6_end=1581512545860; __rpm=%7Cp_28473192.029..1581512546326; __trace_id=20200212210708740312605248881972107',
#'Referer': '',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
url_a1 ='http://product.dangdang.com/index.php?'
comment_html = requests.get(comment_hrefs,headers=header).text
productId=re.findall(r'"productId":"(.*?)"',comment_html)
productId_str = "".join(productId)
categoryPath = re.findall(r'"categoryPath":"(.*?)"',comment_html)
categoryPath_str = "".join(categoryPath)
r = "comment2Flabel"
parm ={
'r' : r,
'productId' : productId_str,
'categoryPath' : categoryPath_str
}
#构造ajax请求url
ajax_url = url_a1 + urlencode(parm)
aj = ajax_url.replace('comment','comment%')
#调用ajax请求
response = requests.get(aj, headers=header)
#print(response)
#ajax请求返回的是json数据,通过调用json()方法得到json数据
json = response.json()
data=json.get('data')
tags = data['tags']
print(tags[1]['name'])
def ajax_f():
#调用ajax的次数,这里调用5次。
for offset in (range(0,5)):
parse_ajax_web(offset*20)
if __name__ == '__main__':
spider()
ajax_f()
今天我们先到这里,有不对的地方希望大佬指正。我也是初学,希望大家交流探讨。持续更新中

















 996
996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









