






Deepseek-r1-zero
前言
zero是一个实验,它不足以作为商业化模型进行应用。
方法
核心就两块,一个grpo,一个规则约束方法。
GRPO
grpo来自于DeepseekMath,如下图。事先说明,这个不是r1-zero用的grpo,zero的是阉割版的,会在后面展示。
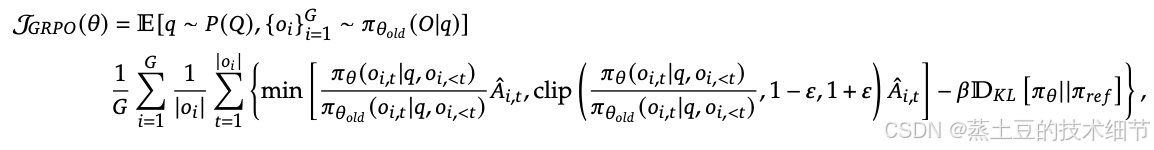
熟悉ppo的人看这个很亲切,min(xxx)就是clip。A是优势函数,用
π
\pi
π的比值做拒绝采样。KL散度限制模型变化幅度,这里有KL(p||q)和KL(q||p)之分,根据其原理分别叫forward KL和reverse KL,后者采样基于训练后的模型
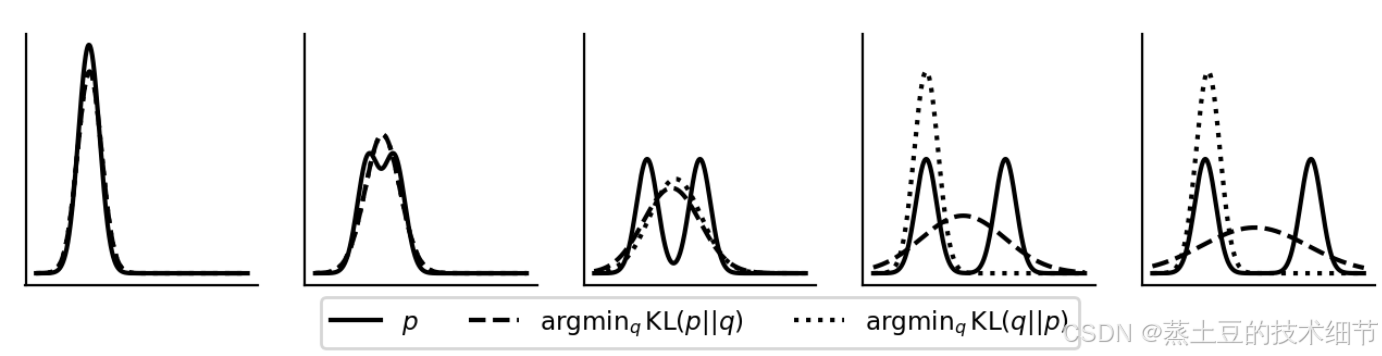
上面的图显示了不同KL下拟合分布p的模型q的效果,后面的图里,reverse KL会拟合单峰而非双峰,因此方差小均值偏差大,我们追求模型训练稳定性,因此关注方差小这一块,这大概是选择KL(q||p)的原因。
GRPO括号里的搞明白了,再看外面的,对于一条训练数据,采样G次,那么oi就是其中一条采样序列。然后拿着这个序列去计算后面的loss,并按照其长度做加和平均(否则长序列会有天然的大loss,不好)。
以下是zero的grpo,可见,对每个数据采样G个从头到尾的输出,然后对每个输出计算clip和KL。优势函数A用归一化的reward score ri。reward model不是DeepseekMath用的GAE,是基于规则约束给的规则reward score。
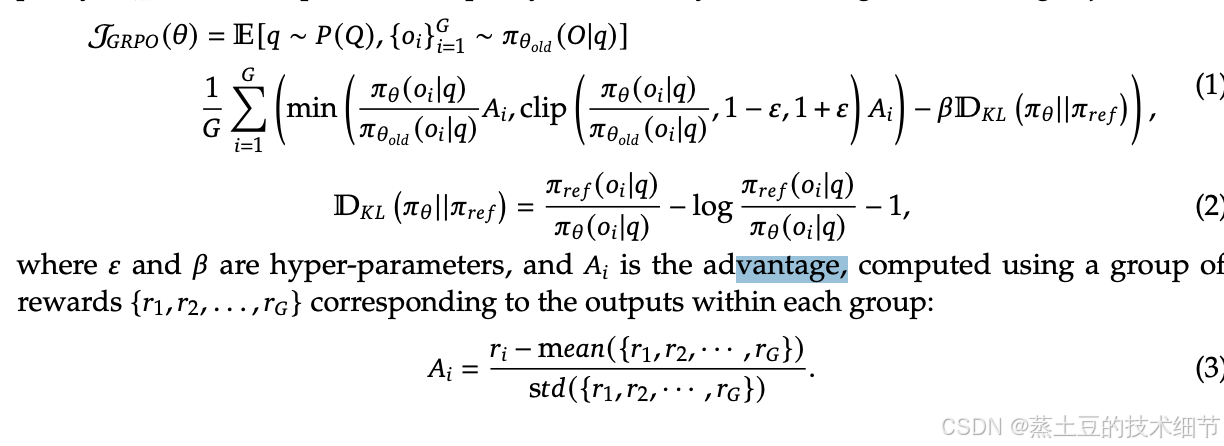
规则约束
优势函数的背后是reward model给的score,zero给的reward score很暴力,用规则硬算。
规则分两块:
- 要求最终答案与ground-truth一样
- 要求输出格式正确,例如把思考过程放在<think>思考过程<\think>里。
为了引导格式输出,只用一个简单的prompt约束:

DeepSeek-R1
zero效果惊艳,但是有如下问题:
- 由于粗暴的规则约束,导致思考过程有时不可读。
- 由于粗暴的规则约束,有时候思考思考着,它会换一种语言,我们自己测试时会发现,中文提问,思考了一会儿开始用英语思考,或者日语,然后answer是中文。这也对用户不友好。
- zero用来推理还行,我们的训练都是推理任务,但是创造性的任务它不太行,例如文学创作。
所以zero只能当成一个不稳定的高质量cot数据提取器。
为了让zero的成果转化为商用,有了如下思路:
- 沿着zero的经验,希望搞一版高效生成cot的推理模型,至少能把zero的12问题克服。
- 基于提取的数据,再去用sft+rl训练deepseek-v3,拿到商用模型。
只能说验证过的商用化训练方法还是稳的,唯一变量是我们现在有了高质量cot数据生成方法。
第一步,搞一个高效生成cot的r1-zero加强版
这回不能直接上grpo了,怎么说它也是个rl方法,不稳定性太强。因此两步走,先冷启动,用一批数据sft稍微规范cot输出格式,然后用grpo增强推理能力。
sft冷启动
sft数据来源:
- 用任何能收集长cot的方法收集一些cot数据,具体来说,用few-shot方法给cot例子,然后再提取cot数据。
- 用zero生成的cot数据,为了能用,必须做人工过滤
- 人工要过一遍这些数据,能改则改,保持上述数据的高质量。
训练:正常sft
grpo训练
这次与zero唯一不同的是,增加了一个约束。会计算期望语言在采样序列中的占比,占比越小reward score越小。这被称为语言一致性约束。
第二步,训练v3->r1
第一步拿到了一个高效的cot生成模型。且看下面如何使用它生成数据。
训练v3->r1仍然使用sft+rl两阶段。
全场景sft
全场景,意味着训练数据的广度,意味着对所有领域精心设计prompt才能使其生成符合领域的cot数据。
数据:
- 针对推理场景:第一步的推理强化模型自己蒸数据出来。对于一个问题,生成多个候选答案,为了让其有多样性,会用到拒绝采样,即相同token采过后会降权。然后用v3判断其cot的混乱度、可读性等,通过测试才合格。如果是对有Q有A的数据额外增加cot思考,则还需要判断answer对不对的上。
- 非推理场景:(1)拿一部分v3训练数据。(2)一部分没有answer数据,用第一步的推理强化模型生成cot和答案,cot就不要了。(3)需要省略中间过程直接出答案的一批数据。
上面两部分数据60w+20w训两个epoch。
全场景rl
除了常规helpful和harmless的人类偏好数据集,还要精炼数学、代码等方向的能力。这里对人类便好数据集用普通的rl方法,估计是InstructGPT那一套。精炼方向用GRPO的方法,估计是sft搞得比较好,所以此时GRPO没有出现zero的12问题。

















 3846
3846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









