







分析过程:
url:https://lol.qq.com/data/info-heros.shtml
没分析请求之前准备用xpath取出每个英雄的链接然后再发送请求取出英雄皮肤图片和皮肤名,该方案可行难度不高
在分析请求后发现有一个js请求里包含了所有英雄的信息,可以取出英雄id和name :https://lol.qq.com/biz/hero/champion.js
每个英雄的信息页面有一个js请求包含了英雄的皮肤数量和皮肤名称,Galio为英雄的名称,是第一个js中获取的英雄名,如: https://lol.qq.com/biz/hero/Galio.js
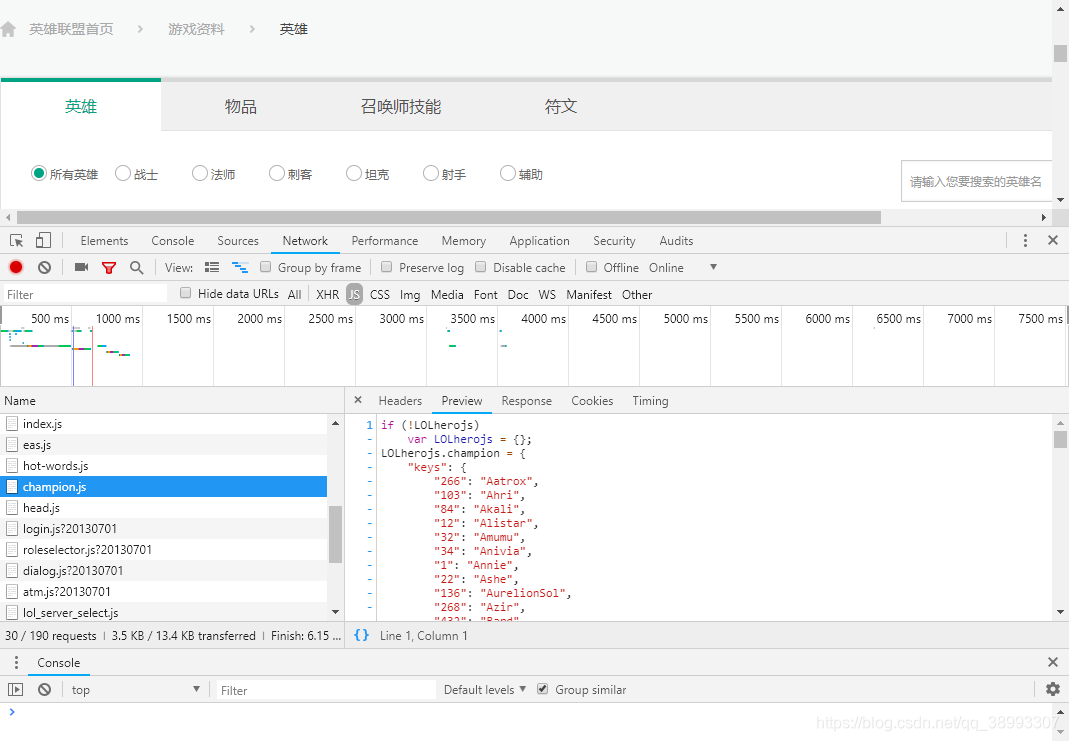
爬取思路:
1、获取第一个js请求所有英雄的id和name
2、组合所有英雄的js请求url列表:heros_url = []
3、遍历列表,获取每个英雄的皮肤名称和图片链接地址
4、下载图片
代码如下:
# coding: utf-8
import urllib2
import os
import json, re
def get_heros_json():
''' 通过url,获取所有hero的信息集合,json格式为:
{u'133': u'Quinn', u'91': u'Talon'} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 912
912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









