







1.C++ 是一门面向对象的编程语言,理解 C++,首先要理解类(Class)和对象(Object)这两个概念。
C++ 中的类(Class)可以看做C语言中结构体(Struct)的升级版。结构体是一种构造类型,可以包含若干成员变量,每个成员变量的类型可以不同;可以通过结构体来定义结构体变量,每个变量拥有相同的性质。例如:
#include <stdio.h>
#include<iostream>
using namespace std;
//定义结构体 Student
struct Student {
//结构体包含的成员变量
const char *name;
int age;
float score;
};
//显示结构体的成员变量
void display(struct Student stu) {
printf("%s的年龄是 %d,成绩是 %f\n", stu.name, stu.age, stu.score);
}
int main() {
struct Student stu1;
//为结构体的成员变量赋值
stu1.name = "小明";
stu1.age = 15;
stu1.score = 92.5;
//调用函数
display(stu1);
system("pause");
return 0;
}
运行结果:
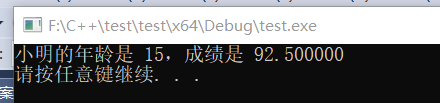
C++ 中的类也是一种构造类型,但是进行了一些扩展,类的成员不但可以是变量,还可以是函数;通过类定义出来的变量也有特定的称呼,叫做“对象”。例如:
#include <stdio.h>
#include<iostream>
//通过class关键字类定义类
class Student {
public:
//类包含的变量
const char *name;
int age;
float score;
//类包含的函数
void say() {
printf("%s的年龄是 %d,成绩是 %f\n", name, age, score);
}
};
int main() {
//通过类来定义变量,即创建对象
class Student stu1; //也可以省略关键字class
//为类的成员变量赋值
stu1.name = "小明";
stu1.age = 15;
stu1.score = 92.5f;
//调用类的成员函数
stu1.say();
system("pause");
return 0;
}
运行结果与上例相同。
对于熟悉 C++ 的读者,这段代码并不规范,请忽略这一细节,本节的重点是引入类和对象的概念
C语言中的 struct 只能包含变量,而 C++ 中的 class 除了可以包含变量,还可以包含函数。display() 是用来处理成员变量的函数,在C语言中,我们将它放在了 struct Student 外面,它和成员变量是分离的;而在 C++ 中,我们将它放在了 class Student 内部,使它和成员变量聚集在一起,看起来更像一个整体。
在第二段代码中,我们先通过 class 关键字定义了一个类 Student,然后又通过 Student 类创建了一个对象 stu1。变量和函数都是类的成员,创建对象后就可以通过点号.来使用它们。
可以将类比喻成图纸,对象比喻成零件,图纸说明了零件的参数(成员变量)及其承担的任务(成员函数);一张图纸可以生产出多个具有相同性质的零件,不同图纸可以生产不同类型的零件。
类只是一张图纸,起到说明的作用,不占用内存空间;对象才是具体的零件,要有地方来存放,才会占用内存空间。
在 C++ 中,通过类名就可以创建对象,即将图纸生产成零件,这个过程叫做类的实例化,因此也称对象是类的一个实例(Instance)。
有些资料也将类的成员变量称为属性(Property),将类的成员函数称为方法(Method)。
1.1 面向对象编程(Object Oriented Programming,OOP)
C++、Java、C#、PHP 等语言都支持类和对象,所以使用这些语言编写程序也被称为面向对象编程,这些语言也被称为面向对象的编程语言。C语言因为不支持类和对象的概念,被称为面向过程的编程语言。
在C语言中,我们会把重复使用或具有某项功能的代码封装成一个函数,将拥有相关功能的多个函数放在一个源文件,再提供一个对应的头文件,这就是一个模块。使用模块时,引入对应的头文件就可以。
而在 C++ 中,多了一层封装,就是类(Class)。类由一组相关联的函数、变量组成,你可以将一个类或多个类放在一个源文件,使用时引入对应的类就可以。下面是C和C++项目组织方式的对比:
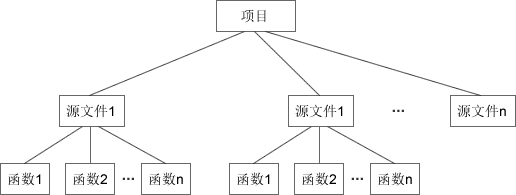
图1:C语言中项目的组织方式
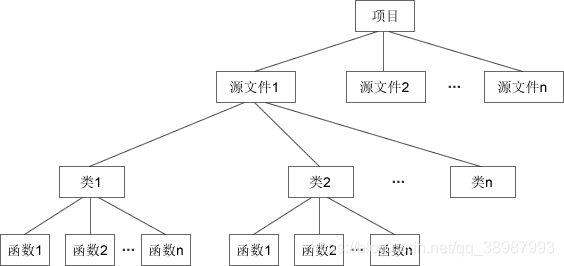
不要小看类(Class)这一层封装,它有很多特性,极大地方便了中大型程序的开发,它让 C++ 成为面向对象的语言。
2.C++ new和delete运算符简介
在C语言中,动态分配内存用 malloc() 函数,释放内存用 free() 函数。如下所示:
int *p = (int*) malloc( sizeof(int) * 10 ); //分配10个int型的内存空间
free(p); //释放内存
在C++中,这两个函数仍然可以使用,但是C++又新增了两个关键字,new 和 delete:new 用来动态分配内存,delete 用来释放内存。
用 new 和 delete 分配内存更加简单:
int *p = new int; //分配1个int型的内存空间
delete p; //释放内存
new 操作符会根据后面的数据类型来推断所需空间的大小。
如果希望分配一组连续的数据,可以使用 new[]:
int *p = new int[10]; //分配10个int型的内存空间
delete[] p;
用 new[] 分配的内存需要用 delete[] 释放,它们是一一对应的。
和 malloc() 一样,new 也是在堆区分配内存,必须手动释放,否则只能等到程序运行结束由操作系统回收。为了避免内存泄露,通常 new 和 delete、new[] 和 delete[] 操作符应该成对出现,并且不要和C语言中 malloc()、free() 一起混用。
3.C++函数重载
在C语言中,即使功能相同都是交换两个变量的值,由于两个变量有多种类型,可以是 int、float、char、bool 等,程序员往往需要分别设计出三个不同名的函数,其函数原型与下面类似:
void swap1(int *a, int *b); //交换 int 变量的值
void swap2(float *a, float *b); //交换 float 变量的值
void swap3(char *a, char *b); //交换 char 变量的值
void swap4(bool *a, bool *b); //交换 bool 变量的值
但在C++中,这完全没有必要。C++ 允许多个函数拥有相同的名字,只要它们的参数列表不同就可以,这就是函数的重载(Function Overloading)。借助重载,一个函数名可以有多种用途。
参数列表又叫参数签名,包括参数的类型、参数的个数和参数的顺序,只要有一个不同就叫做参数列表不同。
【示例】借助函数重载交换不同类型的变量的值:
#include <iostream>
using namespace std;
//交换 int 变量的值
void Swap(int *a, int *b){
int temp = *a;
*a = *b;
*b = temp;
}
//交换 float 变量的值
void Swap(float *a, float *b){
float temp = *a;
*a = *b;
*b = temp;
}
//交换 char 变量的值
void Swap(char *a, char *b){
char temp = *a;
*a = *b;
*b = temp;
}
//交换 bool 变量的值
void Swap(bool *a, bool *b){
char temp = *a;
*a = *b;
*b = temp;
}
int main(){
//交换 int 变量的值
int n1 = 100, n2 = 200;
Swap(&n1, &n2);
cout<<n1<<", "<<n2<<endl;
//交换 float 变量的值
float f1 = 12.5, f2 = 56.93;
Swap(&f1, &f2);
cout<<f1<<", "<<f2<<endl;
//交换 char 变量的值
char c1 = 'A', c2 = 'B';
Swap(&c1, &c2);
cout<<c1<<", "<<c2<<endl;
//交换 bool 变量的值
bool b1 = false, b2 = true;
Swap(&b1, &b2);
cout<<b1<<", "<<b2<<endl;
return 0;
}
运行结果:
200, 100
56.93, 12.5
B, A
1, 0
在使用重载函数时,同名函数的功能应当相同或相近,不要用同一函数名去实现完全不相干的功能,虽然程序也能运行,但可读性不好,使人觉得莫名其妙。
注意,参数列表不同包括参数的个数不同、类型不同或顺序不同,仅仅参数名称不同是不可以的。函数返回值也不能作为重载的依据。
函数的重载的规则:
- 函数名称必须相同。
- 参数列表必须不同(个数不同、类型不同、参数排列顺序不同等)。
- 函数的返回类型可以相同也可以不相同。
- 仅仅返回类型不同不足以成为函数的重载。
C++ 是如何做到函数重载的
C++代码在编译时会根据参数列表对函数进行重命名,例如void Swap(int a, int b)会被重命名为_Swap_int_int,void Swap(float x, float y)会被重命名为_Swap_float_float。当发生函数调用时,编译器会根据传入的实参去逐个匹配,以选择对应的函数,如果匹配失败,编译器就会报错,这叫做重载决议(Overload Resolution)。
不同的编译器有不同的重命名方式,这里仅仅举例说明,实际情况可能并非如此。
从这个角度讲,函数重载仅仅是语法层面的,本质上它们还是不同的函数,占用不同的内存,入口地址也不一样。
4.C++类的定义和对象的创建
类是创建对象的模板,一个类可以创建多个对象,每个对象都是类类型的一个变量;创建对象的过程也叫类的实例化。每个对象都是类的一个具体实例(Instance),拥有类的成员变量和成员函数。
有些教程将类的成员变量称为类的属性(Property),将类的成员函数称为类的方法(Method)。在面向对象的编程语言中,经常把函数(Function)称为方法(Method)。
与结构体一样,类只是一种复杂数据类型的声明,不占用内存空间。而对象是类这种数据类型的一个变量,或者说是通过类这种数据类型创建出来的一份实实在在的数据,所以占用内存空间
类的定义
类是用户自定义的类型,如果程序中要用到类,必须提前说明,或者使用已存在的类(别人写好的类、标准库中的类等),C++语法本身并不提供现成的类的名称、结构和内容。
一个简单的类的定义:
class Student{
public:
//成员变量
char *name;
int age;
float score;
//成员函数
void say(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
}
};
class是 C++ 中新增的关键字,专门用来定义类。Student是类的名称;类名的首字母一般大写,以和其他的标识符区分开。{ }内部是类所包含的成员变量和成员函数,它们统称为类的成员(Member);由{ }包围起来的部分有时也称为类体,和函数体的概念类似。public也是 C++ 的新增关键字,它只能用在类的定义中,表示类的成员变量或成员函数具有“公开”的访问权限
注意在类定义的最后有一个分号;,它是类定义的一部分,表示类定义结束了,不能省略。
整体上讲,上面的代码创建了一个 Student 类,它包含了 3 个成员变量和 1 个成员函数。
类只是一个模板(Template),编译后不占用内存空间,所以在定义类时不能对成员变量进行初始化,因为没有地方存储数据。只有在创建对象以后才会给成员变量分配内存,这个时候就可以赋值了。
类可以理解为一种新的数据类型,该数据类型的名称是 Student。与 char、int、float 等基本数据类型不同的是,Student 是一种复杂数据类型,可以包含基本类型,而且还有很多基本类型中没有的特性。
创建对象
有了 Student 类后,就可以通过它来创建对象了,例如:
Student liLei; //创建对象
Student是类名,liLei是对象名。这和使用基本类型定义变量的形式类似:
int a; //定义整型变量
从这个角度考虑,我们可以把 Student 看做一种新的数据类型,把 liLei 看做一个变量。
访问类的成员
创建对象以后,可以使用点号.来访问成员变量和成员函数,这和通过结构体变量来访问它的成员类似,如下所示:
#include <iostream>
using namespace std;
//类通常定义在函数外面
class Student{
public:
//类包含的变量
const char *name;
int age;
float score;
//类包含的函数
void say(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
}
};
int main(){
//创建对象
Student stu;
stu.name = "小明";
stu.age = 15;
stu.score = 92.5f;
stu.say();
return 0;
}
运行结果:
小明的年龄是15,成绩是92.5
stu 是一个对象,占用内存空间,可以对它的成员变量赋值,也可以读取它的成员变量。
类通常定义在函数外面,当然也可以定义在函数内部,不过很少这样使用。
使用对象指针
上面代码中创建的对象 stu 在栈上分配内存,需要使用&获取它的地址,例如:
Student stu;
Student *pStu = &stu;
pStu 是一个指针,它指向 Student 类型的数据,也就是通过 Student 创建出来的对象。
当然,你也可以在堆上创建对象,这个时候就需要使用前面讲到的new关键字
Student *pStu = new Student;
在栈上创建出来的对象都有一个名字,比如 stu,使用指针指向它不是必须的。但是通过 new 创建出来的对象就不一样了,它在堆上分配内存,没有名字,只能得到一个指向它的指针,所以必须使用一个指针变量来接收这个指针,否则以后再也无法找到这个对象了,更没有办法使用它。也就是说,使用 new 在堆上创建出来的对象是匿名的,没法直接使用,必须要用一个指针指向它,再借助指针来访问它的成员变量或成员函数。
栈内存是程序自动管理的,不能使用 delete 删除在栈上创建的对象;堆内存由程序员管理,对象使用完毕后可以通过 delete 删除。在实际开发中,new 和 delete 往往成对出现,以保证及时删除不再使用的对象,防止无用内存堆积。
有了对象指针后,可以通过箭头->来访问对象的成员变量和成员函数,这和通过结构体指针来访问它的成员类似,请看下面的示例:
pStu -> name = "小明";
pStu -> age = 15;
pStu -> score = 92.5f;
pStu -> say();
下面是一个完整的例子:
#include <iostream>
using namespace std;
class Student{
public:
char *name;
int age;
float score;
void say(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
}
};
int main(){
Student *pStu = new Student;
pStu -> name = "小明";
pStu -> age = 15;
pStu -> score = 92.5f;
pStu -> say();
delete pStu; //删除对象
return 0;
}
运行结果:
小明的年龄是15,成绩是92.5
4.1 C++类的成员变量和成员函数
类的成员变量和普通变量一样,也有数据类型和名称,占用固定长度的内存。但是,在定义类的时候不能对成员变量赋值,因为类只是一种数据类型或者说是一种模板,本身不占用内存空间,而变量的值则需要内存来存储。
类的成员函数也和普通函数一样,都有返回值和参数列表,它与一般函数的区别是:成员函数是一个类的成员,出现在类体中,它的作用范围由类来决定;而普通函数是独立的,作用范围是全局的,或位于某个命名空间内。
class Student{
public:
//成员变量
char *name;
int age;
float score;
//成员函数
void say(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
}
};
这段代码在类体中定义了成员函数。你也可以只在类体中声明函数,而将函数定义放在类体外面,如下图所示:
class Student{
public:
//成员变量
char *name;
int age;
float score;
//成员函数
void say(); //函数声明
};
//函数定义
void Student::say(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
}
在类体中直接定义函数时,不需要在函数名前面加上类名,因为函数属于哪一个类是不言而喻的。
但当成员函数定义在类外时,就必须在函数名前面加上类名予以限定。::被称为域解析符(也称作用域运算符或作用域限定符),用来连接类名和函数名,指明当前函数属于哪个类。
成员函数必须先在类体中作原型声明,然后在类外定义,也就是说类体的位置应在函数定义之前。
在类体中和类体外定义成员函数的区别
在类体中和类体外定义成员函数是有区别的:在类体中定义的成员函数会自动成为内联函数,在类体外定义的不会。当然,在类体内部定义的函数也可以加 inline 关键字,但这是多余的,因为类体内部定义的函数默认就是内联函数。
内联函数一般不是我们所期望的,它会将函数调用处用函数体替代,所以我建议在类体内部对成员函数作声明,而在类体外部进行定义,这是一种良好的编程习惯,实际开发中大家也是这样做的。
当然,如果你的函数比较短小,希望定义为内联函数,那也没有什么不妥的。
如果你既希望将函数定义在类体外部,又希望它是内联函数,那么可以在定义函数时加 inline 关键字。当然你也可以在函数声明处加 inline,不过这样做没有效果,编译器会忽略函数声明处的 inline。
下面是一个将内联函数定义在类外部的例子:
class Student{
public:
char *name;
int age;
float score;
void say(); //内联函数声明,可以增加 inline 关键字,但编译器会忽略
};
//函数定义
inline void Student::say(){
cout<<name<<"的年龄是"<<age<<",成绩是"<<score<<endl;
}
这样,say() 就会变成内联函数。
这种在类体外定义 inline 函数的方式,必须将类的定义和成员函数的定义都放在同一个头文件中(或者同一个源文件中),否则编译时无法进行嵌入(将函数代码的嵌入到函数调用出),
4.2 C++类成员的访问权限以及类的封装
C++通过 public、protected、private 三个关键字来控制成员变量和成员函数的访问权限,它们分别表示公有的、受保护的、私有的,被称为成员访问限定符。所谓访问权限,就是你能不能使用该类中的成员。
在类的内部(定义类的代码内部),无论成员被声明为 public、protected 还是 private,都是可以互相访问的,没有访问权限的限制。
在类的外部(定义类的代码之外),只能通过对象访问成员,并且通过对象只能访问 public 属性的成员,不能访问 private、protected 属性的成员
#include <iostream>
using namespace std;
//类的声明
class Student{
private: //私有的
char *m_name;
int m_age;
float m_score;
public: //共有的
void setname(char *name);
void setage(int age);
void setscore(float score);
void show();
};
//成员函数的定义
void Student::setname(char *name){
m_name = name;
}
void Student::setage(int age){
m_age = age;
}
void Student::setscore(float score){
m_score = score;
}
void Student::show(){
cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
}
int main(){
//在栈上创建对象
Student stu;
stu.setname("小明");
stu.setage(15);
stu.setscore(92.5f);
stu.show();
//在堆上创建对象
Student *pstu = new Student;
pstu -> setname("李华");
pstu -> setage(16);
pstu -> setscore(96);
pstu -> show();
return 0;
}
运行结果:
小明的年龄是15,成绩是92.5
李华的年龄是16,成绩是96
类的声明和成员函数的定义都是类定义的一部分,在实际开发中,我们通常将类的声明放在头文件中,而将成员函数的定义放在源文件中。
类中的成员变量 m_name、m_age 和m_ score 被设置成 private 属性,在类的外部不能通过对象访问。也就是说,私有成员变量和成员函数只能在类内部使用,在类外都是无效的。
成员函数 setname()、setage() 和 setscore() 被设置为 public 属性,是公有的,可以通过对象访问。
private 后面的成员都是私有的,直到有 public 出现才会变成共有的;public 之后再无其他限定符,所以 public 后面的成员都是共有的。
成员变量大都以m_开头,这是约定成俗的写法,不是语法规定的内容。以m_开头既可以一眼看出这是成员变量,又可以和成员函数中的形参名字区分开。
以 setname() 为例,如果将成员变量m_name的名字修改为name,那么 setname() 的形参就不能再叫name了,得换成诸如name1、_name这样没有明显含义的名字,否则name=name;这样的语句就是给形参name赋值,而不是给成员变量name赋值。
因为三个成员变量都是私有的,不能通过对象直接访问,所以必须借助三个 public 属性的成员函数来修改它们的值。下面的代码是错误的:
简单地谈类的封装
private 关键字的作用在于更好地隐藏类的内部实现,该向外暴露的接口(能通过对象访问的成员)都声明为 public,不希望外部知道、或者只在类内部使用的、或者对外部没有影响的成员,都建议声明为 private。
根据C++软件设计规范,实际项目开发中的成员变量以及只在类内部使用的成员函数(只被成员函数调用的成员函数)都建议声明为 private,而只将允许通过对象调用的成员函数声明为 public。
另外还有一个关键字 protected,声明为 protected 的成员在类外也不能通过对象访问,但是在它的派生类内部可以访问,
将成员变量都声明为 private,如何给它们赋值呢,又如何读取它们的值呢?
我们可以额外添加两个 public 属性的成员函数,一个用来设置成员变量的值,一个用来修改成员变量的值。上面的代码中,setname()、setage()、setscore() 函数就用来设置成员变量的值;如果希望获取成员变量的值,可以再添加三个函数 getname()、getage()、getscore()。
给成员变量赋值的函数通常称为 set 函数,它们的名字通常以set开头,后跟成员变量的名字;读取成员变量的值的函数通常称为 get 函数,它们的名字通常以get开头,后跟成员变量的名字。
这种将成员变量声明为 private、将部分成员函数声明为 public 的做法体现了类的封装性。所谓封装,是指尽量隐藏类的内部实现,只向用户提供有用的成员函数。
对private和public的更多说明
声明为 private 的成员和声明为 public 的成员的次序任意,既可以先出现 private 部分,也可以先出现 public 部分。如果既不写 private 也不写 public,就默认为 private。
在一个类体中,private 和 public 可以分别出现多次。每个部分的有效范围到出现另一个访问限定符或类体结束时(最后一个右花括号)为止。但是为了使程序清晰,应该养成这样的习惯,使每一种成员访问限定符在类定义体中只出现一次。
下面的类声明也是完全正确的:
class Student{
private:
char *m_name;
private:
int m_age;
float m_score;
public:
void setname(char *name);
void setage(int age);
public:
void setscore(float score);
void show();
};
4.3 C++构造函数
在C++中,有一种特殊的成员函数,它的名字和类名相同,没有返回值,不需要用户显式调用(用户也不能调用),而是在创建对象时自动执行。这种特殊的成员函数就是构造函数。
#include <iostream>
using namespace std;
class Student{
private:
char *m_name;
int m_age;
float m_score;
public:
//声明构造函数
Student(char *name, int age, float score);
//声明普通成员函数
void show();
};
//定义构造函数
Student::Student(char *name, int age, float score){
m_name = name;
m_age = age;
m_score = score;
}
//定义普通成员函数
void Student::show(){
cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
}
int main(){
//创建对象时向构造函数传参
Student stu("小明", 15, 92.5f);
stu.show();
//创建对象时向构造函数传参
Student *pstu = new Student("李华", 16, 96);
pstu -> show();
return 0;
}
运行结果:
小明的年龄是15,成绩是92.5
李华的年龄是16,成绩是96
该例在 Student 类中定义了一个构造函数Student(char *, int, float),它的作用是给三个 private 属性的成员变量赋值。要想调用该构造函数,就得在创建对象的同时传递实参,并且实参由( )包围,和普通的函数调用非常类似。
在栈上创建对象时,实参位于对象名后面,例如Student stu(“小明”, 15, 92.5f);在堆上创建对象时,实参位于类名后面,例如new Student(“李华”, 16, 96)。
构造函数必须是 public 属性的,否则创建对象时无法调用。当然,设置为 private、protected 属性也不会报错,但是没有意义。
构造函数没有返回值,因为没有变量来接收返回值,即使有也毫无用处,这意味着:
- 不管是声明还是定义,函数名前面都不能出现返回值类型,即使是 void 也不允许;
- 函数体中不能有 return 语句。
构造函数的重载
和普通成员函数一样,构造函数是允许重载的。一个类可以有多个重载的构造函数,创建对象时根据传递的实参来判断调用哪一个构造函数。
构造函数的调用是强制性的,一旦在类中定义了构造函数,那么创建对象时就一定要调用,不调用是错误的。如果有多个重载的构造函数,那么创建对象时提供的实参必须和其中的一个构造函数匹配;反过来说,创建对象时只有一个构造函数会被调用。
对示例1中的代码,如果写作Student stu或者new Student就是错误的,因为类中包含了构造函数,而创建对象时却没有调用。
更改示例1的代码,再添加一个构造函数(示例2):
#include <iostream>
using namespace std;
class Student{
private:
char *m_name;
int m_age;
float m_score;
public:
Student();
Student(char *name, int age, float score);
void setname(char *name);
void setage(int age);
void setscore(float score);
void show();
};
Student::Student(){
m_name = NULL;
m_age = 0;
m_score = 0.0;
}
Student::Student(char *name, int age, float score){
m_name = name;
m_age = age;
m_score = score;
}
void Student::setname(char *name){
m_name = name;
}
void Student::setage(int age){
m_age = age;
}
void Student::setscore(float score){
m_score = score;
}
void Student::show(){
if(m_name == NULL || m_age <= 0){
cout<<"成员变量还未初始化"<<endl;
}else{
cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
}
}
int main(){
//调用构造函数 Student(char *, int, float)
Student stu("小明", 15, 92.5f);
stu.show();
//调用构造函数 Student()
Student *pstu = new Student();
pstu -> show();
pstu -> setname("李华");
pstu -> setage(16);
pstu -> setscore(96);
pstu -> show();
return 0;
}
运行结果:
小明的年龄是15,成绩是92.5
成员变量还未初始化
李华的年龄是16,成绩是96
构造函数Student(char *, int, float)为各个成员变量赋值,构造函数Student()将各个成员变量的值设置为空,它们是重载关系。根据Student()创建对象时不会赋予成员变量有效值,所以还要调用成员函数 setname()、setage()、setscore() 来给它们重新赋值。
构造函数在实际开发中会大量使用,它往往用来做一些初始化工作,例如对成员变量赋值、预先打开文件等。
默认构造函数
如果用户自己没有定义构造函数,那么编译器会自动生成一个默认的构造函数,只是这个构造函数的函数体是空的,也没有形参,也不执行任何操作。比如上面的 Student 类,默认生成的构造函数如下:
Student(){}
一个类必须有构造函数,要么用户自己定义,要么编译器自动生成。一旦用户自己定义了构造函数,不管有几个,也不管形参如何,编译器都不再自动生成。在示例1中,Student 类已经有了一个构造函数Student(char *, int, float),也就是我们自己定义的,编译器不会再额外添加构造函数Student(),在示例2中我们才手动添加了该构造函数。
最后需要注意的一点是,调用没有参数的构造函数也可以省略括号。对于示例2的代码,在栈上创建对象可以写作Student stu()或Student stu,在堆上创建对象可以写作Student *pstu = new Student()或Student *pstu = new Student,它们都会调用构造函数 Student()。
4.4 C++析构函数
创建对象时系统会自动调用构造函数进行初始化工作,同样,销毁对象时系统也会自动调用一个函数来进行清理工作,例如释放分配的内存、关闭打开的文件等,这个函数就是析构函数。
析构函数(Destructor)也是一种特殊的成员函数,没有返回值,不需要程序员显式调用(程序员也没法显式调用),而是在销毁对象时自动执行。构造函数的名字和类名相同,而析构函数的名字是在类名前面加一个~符号。
注意:析构函数没有参数,不能被重载,因此一个类只能有一个析构函数。如果用户没有定义,编译器会自动生成一个默认的析构函数
我们定义了一个 VLA 类来模拟变长数组,它使用一个构造函数为数组分配内存,这些内存在数组被销毁后不会自动释放,所以非常有必要再添加一个析构函数,专门用来释放已经分配的内存。请看下面的完整示例:
#include <iostream>
using namespace std;
class VLA{
public:
VLA(int len); //构造函数
~VLA(); //析构函数
public:
void input(); //从控制台输入数组元素
void show(); //显示数组元素
private:
int *at(int i); //获取第i个元素的指针
private:
const int m_len; //数组长度
int *m_arr; //数组指针
int *m_p; //指向数组第i个元素的指针
};
VLA::VLA(int len): m_len(len){ //使用初始化列表来给 m_len 赋值
if(len > 0){ m_arr = new int[len]; /*分配内存*/ }
else{ m_arr = NULL; }
}
VLA::~VLA(){
delete[] m_arr; //释放内存
}
void VLA::input(){
for(int i=0; m_p=at(i); i++){ cin>>*at(i); }
}
void VLA::show(){
for(int i=0; m_p=at(i); i++){
if(i == m_len - 1){ cout<<*at(i)<<endl; }
else{ cout<<*at(i)<<", "; }
}
}
int * VLA::at(int i){
if(!m_arr || i<0 || i>=m_len){ return NULL; }
else{ return m_arr + i; }
}
int main(){
//创建一个有n个元素的数组(对象)
int n;
cout<<"Input array length: ";
cin>>n;
VLA *parr = new VLA(n);
//输入数组元素
cout<<"Input "<<n<<" numbers: ";
parr -> input();
//输出数组元素
cout<<"Elements: ";
parr -> show();
//删除数组(对象)
delete parr;
return 0;
}
运行结果:
Input array length: 5
Input 5 numbers: 99 23 45 10 100
Elements: 99, 23, 45, 10, 100
~VLA()就是 VLA 类的析构函数,它的唯一作用就是在删除对象后释放已经分配的内存。
函数名是标识符的一种,原则上标识符的命名中不允许出现符号,在析构函数的名字中出现的可以认为是一种特殊情况,目的是为了和构造函数的名字加以对比和区分。
注意:at() 函数只在类的内部使用,所以将它声明为 private 属性;m_len 变量不允许修改,所以用 const 进行了限制,这样就只能使用初始化列表来进行赋值。
C++ 中的 new 和 delete 分别用来分配和释放内存,它们与C语言中 malloc()、free() 最大的一个不同之处在于:用 new 分配内存时会调用构造函数,用 delete 释放内存时会调用析构函数。构造函数和析构函数对于类来说是不可或缺的,所以在C++中我们非常鼓励使用 new 和 delete。
析构函数的执行时机

#include <iostream>
#include <string>
using namespace std;
class Demo{
public:
Demo(string s);
~Demo();
private:
string m_s;
};
Demo::Demo(string s): m_s(s){ }
Demo::~Demo(){ cout<<m_s<<endl; }
void func(){
//局部对象
Demo obj1("1");
}
//全局对象
Demo obj2("2");
int main(){
//局部对象
Demo obj3("3");
//new创建的对象
Demo *pobj4 = new Demo("4");
func();
cout<<"main"<<endl;
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









