1.自学python后的简单demo,记录一下
from urllib.request import urlopen,Request,urlretrieve
from urllib.error import HTTPError
import re
import os
from bs4 import BeautifulSoup as bf
'''
爬取图片
使用正则表达式匹配标签
'''
def down(imgUrl,path):
img = urlopen(imgUrl)
img = img.read()
f = open(path, "wb")
f.write(img)
f.close()
def downLoadImg(imgUrl,name):
path = "D:/img/"
if not os.path.isdir(path):
os.makedirs(path)
path = '{}{}.jpg'.format(path, name)
# print("保存图片到本地:",path)
urlretrieve(imgUrl, path)
def saveImg(url):
print(url)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
} # 头部信息
try:
request = Request(url, headers=header)
myURL = urlopen(request)
print("该网页是否存在:", myURL.getcode()) # 200
if myURL.getcode() == 200:
html = myURL.read().decode('gbk')
# print(html)
reg = '<img src=".*?" alt=".*?"'
imgre = re.compile(reg) # 编译一下,提升运行速度
urls = imgre.findall(html) # 匹配
# print(urls)
urlMap = iter(urls)
for i in urlMap:
str = list(i.split('"'))
downLoadImg("https://pic.xxxnetbian.com" + str[1], str[3])
else:
if myURL.getcode() == 404:
print(404) # 404
except HTTPError as e:
print(e)
for i in range(10):
if i==0:
url = 'https://pic.xxxnetbian.com'
saveImg(url)
elif i == 1:
continue
else:
url = 'https://pic.xxxnetbian.com/index_'+str(i)+'.html'
saveImg(url)
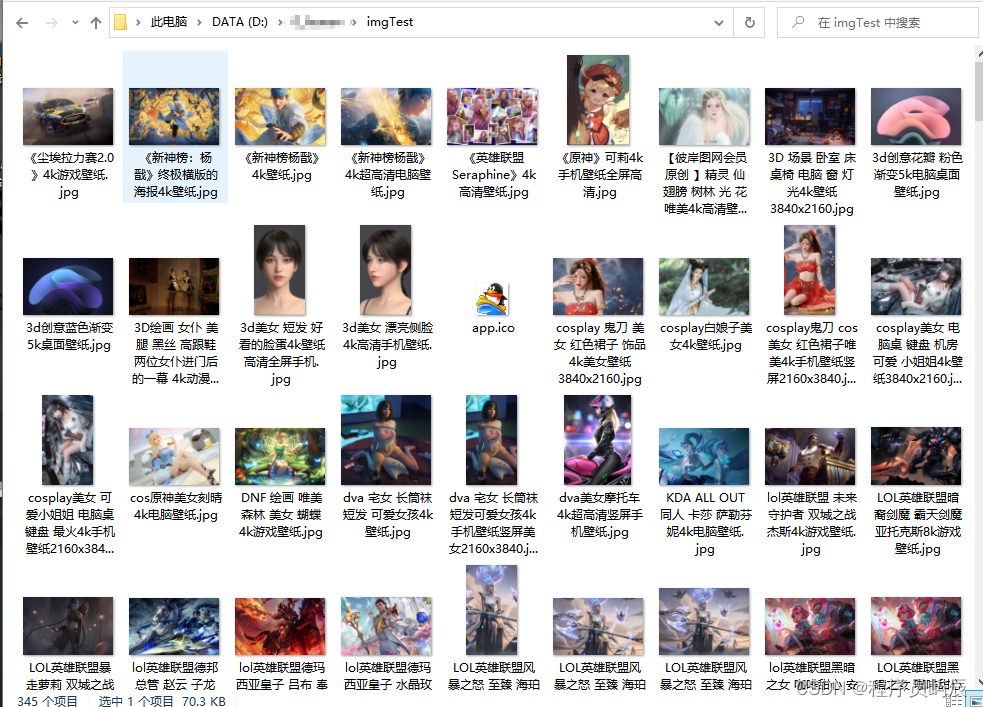
2.效果:




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











