







Skeleton-Based Action Recognition with Directed Graph Neural Networks-DGNN读书笔记
Skeleton-Based Action Recognition with Directed Graph Neural Networks
代码:https://github.com/kenziyuliu/Unofficial-DGNN-PyTorch
论文:http://openaccess.thecvf.com/content_CVPR_2019/papers/Shi_Skeleton-Based_Action_Recognition_With_Directed_Graph_Neural_Networks_CVPR_2019_paper.pdf
1.摘要
简单的说就是利用骨骼数据在动作识别上已经有了飞速的发展,骨骼和关节两类数据分别对动作识别有着重要的作用。如何更好的利用骨骼和关节数据去识别动作,就是这篇论文要讨论的问题。在这项工作中,作者基于自然人体关节和骨骼之间的运动学相关性,将骨骼数据表示为有向无环图(DAG)。 专门设计了一种新颖的定向图神经网络,用于提取关节,骨骼及其关系的信息,并根据提取的特征进行预测。此外,为了更好地适应动作识别任务,基于训练过程使图的拓扑结构具有自适应性,从而带来了显著的改进。 此外,利用骨骼序列的运动信息并将其与空间信息结合,以进一步增强两流框架中的性能。并且在两大数据集NTU-RGBD和 Skeleton-Kinetics中都取得了SOTA
2. 引言
简单介绍了一下动作识别的应用,对比与传统的动作识别方法,基于骨骼数据的识别方法可以抵抗人体比例,运动速度,摄像机视点和背景干扰等变化所带来的识别阻碍。而且骨骼数据目前可以很容易通过传感器以及姿态估计算法获得。深度学习在此任务上的三大方法:
1.GNN
数据主要是基于图形
2.RNN
数据主要是基于矢量序列
3.CNN
数据主要是基于伪图像
有人证明过骨骼数据更有利于动作识别。因为人类自然地根据骨骼在人体中的方向和位置来评估动作,而不是关节的位置。此外,已经证明关节和骨骼信息是彼此互补的,并且将它们组合可以导致识别性能的进一步提高。 对于自然的人体,关节和骨骼牢固地结合在一起,每个关节(骨骼)的位置实际上是由它们连接的骨骼(关节)确定的。我的理解是:利用好关节(骨骼)与关节(骨骼)的相关性,可以提升识别的效果。
论文中举了个例子:例如,肘关节的位置取决于上臂骨的位置,同时也决定了前臂骨的位置。现有的基于图的方法通常将骨骼表示为一个无向图,并用两个独立的网络对骨骼和关节进行建模,而这两个网络不能充分利用关节和骨骼之间的这些依赖性。一种很简单的解决办法:把骨骼描述为一个有向无环图,关节作为顶点,骨骼作为边.
除此之外,又存在一个问题,最初的骨骼是根据人体结构手工设计的,这对于动作识别任务来说可能不是最理想的。这一点刚开始很不好理解,论文中举了一个例子:简单的说就是拥抱或者握手等考察双手依赖性较强的动作时,这种双手的依赖性并不能在人工设计的骨骼结构中体现出来。解决方法:采用adaptive graph。
这篇文章也和其他论文一样,采用了two-stream框架。即 spatial stream 和motion stream
3. 理论
思路:原始骨架数据是一系列帧,每个帧包含一组关节坐标。对于给定的骨骼序列,我们首先根据关节的二维或三维坐标提取骨骼信息。然后,将每个帧中的关节和骨骼(空间信息)表示为图中的顶点和边,并将这些顶点和边送入有向图神经网络(directed graph neural network, DGNN)中,以提取行为识别的特征。最后,将与空间信息相同的图形结构表示的运动信息提取并与two-stream框架中的空间信息相结合,进一步提高性能。
3.1骨骼信息
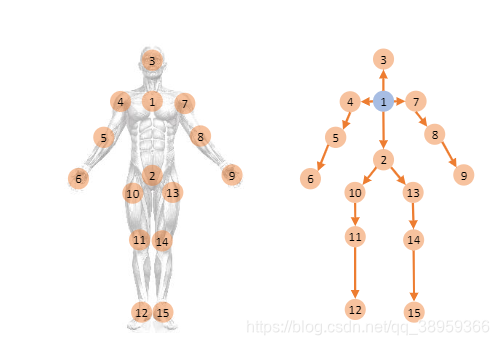
例如上面这张图片,编号处为关节点,很容易想出两个关节点 v 1 , v 2 v1,v2 v1,v2中间即为一根骨骼。所以在论文中的对于关节点 v 1 = ( x 1 , y 1 , z 1 ) v_1=(x_1,y_1,z_1) v1=(x1,y1,z1)和关节点 v 2 = ( x 2 , y 2 , z 2 ) v_2=(x_2,y_2,z_2) v2=(x2,y2,z2),构成了由 v 1 , v 2 v1,v2 v1,v2连接的骨骼 e ( v 1 , v 2 ) = ( x 1 − x 2 , y 1 − y 2 , z 1 − z 2 ) e_(v1,v2)=(x_1-x_2,y_1-y_2,z_1-z_2) e(v1,v2)=(x1−x2,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7655
7655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









