







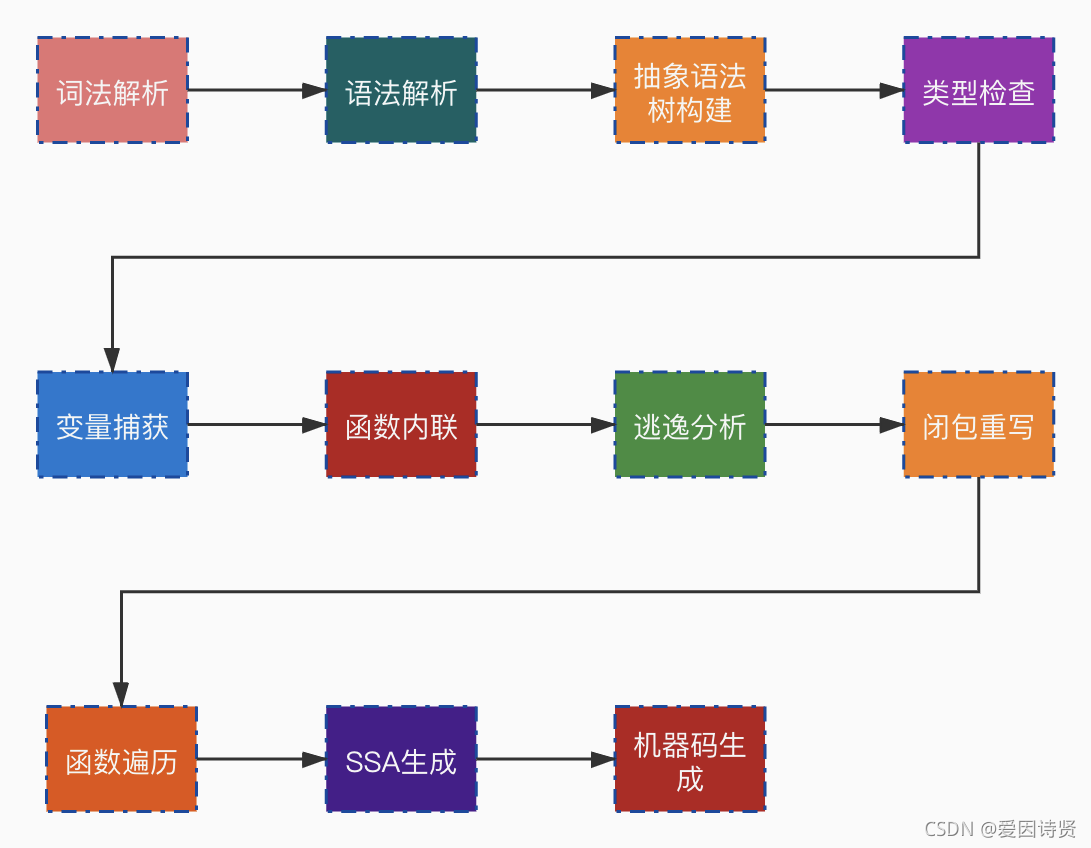
 本文深入介绍了Go语言编译器的工作流程,从三阶段编译器到Go语言编译器的实现,详细讲解了词法解析的`scanner.go`和`token.go`代码,以及语法解析的`nodes.go`和`parser.go`。通过对Go源代码的扫描、token化和语法解析,展示了如何构建抽象语法树,为后续的类型检查、变量捕获、函数内联和逃逸分析奠定基础。
本文深入介绍了Go语言编译器的工作流程,从三阶段编译器到Go语言编译器的实现,详细讲解了词法解析的`scanner.go`和`token.go`代码,以及语法解析的`nodes.go`和`parser.go`。通过对Go源代码的扫描、token化和语法解析,展示了如何构建抽象语法树,为后续的类型检查、变量捕获、函数内联和逃逸分析奠定基础。
Go学习笔记-Go编译器简介
1.编译器
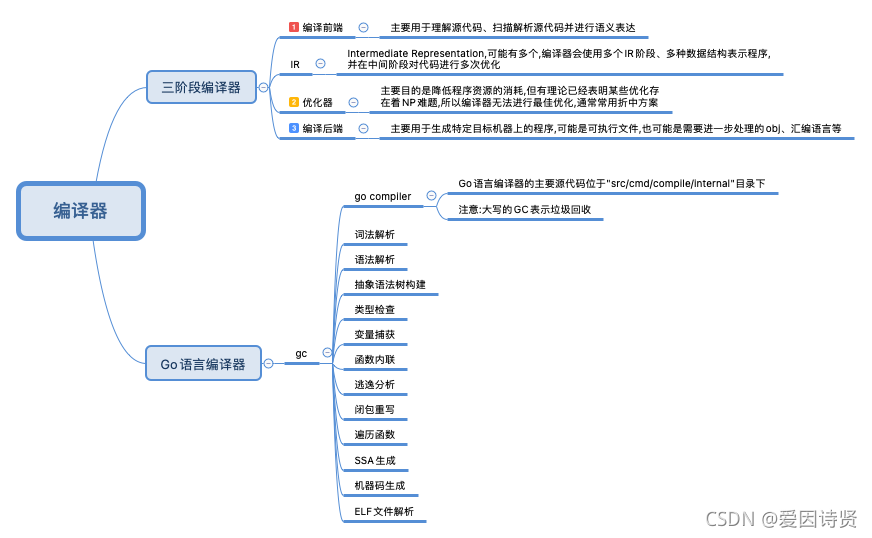
1.1 三阶段编译器
- 编译器前端: 主要用于理解源代码、扫描解析源代码并进行语义表达
- IR: Intermediate Representation,可能有多个,编译器会使用多个 IR 阶段、多种数据结构表示程序,并在中间阶段对代码进行多次优化
- 优化器: 主要目的是降低程序资源的消耗,但有理论已经表明某些优化存在着NP难题,所以编译器无法进行最佳优化,通常常用折中方案
- 编译后端: 主要用于生成特定目标机器上的程序,可能是可执行文件,也可能是需要进一步处理的obj、汇编语言等
1.2 Go语言编译器
- go compiler: Go语言编译器的主要源代码位于"src/cmd/compile/internal"目录下
Tips: 注意:大写的GC表示垃圾回收
2.词法解析
- Go编译器会扫描源代码,并且将其符号(token)化,例如 “+”、"-"操作符会被转化为
_IncOp,赋值符号":="会被转化为_Define。 - token 是用iota声明的整数,定义在
go/src/cmd/compile/internal/syntax/tokens.go文件中。
- Go语言标准库
go/src/go/scanner、go/src/go/token中提供了许多接口用于扫描源代码。 - Go 编译器把文件内容词法扫后,将每个标识符与运算符都被特定的 token 代替。
2.1 scanner.go 代码简介
scanner.go 文件位于 go/src/go/scanner 目录下,实现了Go源代码的扫描,采用一个 []byte 作为源,然后可以通过重复调用 Scan 方法对其进行标记。
- type ErrorHandler func(pos token.Position, msg string): 可以向Scanner.Init 提供 ErrorHandler,如果遇到语法错误并安装了处理程序,则调用处理程序并提供位置和错误消息,该位置指向错误标记的开始。
- type Scanner struct: 扫描器在处理给定文本时保持扫描器的内部状态。
- const bom = 0xFEFF: 字节顺序标记,只允许作为第一个字符。
- next()函数: 将下一个Unicode字符读入 s.ch,S.ch < 0 表示文件结束。
- peek()函数: Peek返回跟随最近读取字符的字节,而不推进扫描仪,如果扫描器在 EOF, peek 返回 0。
- type Mode uint: 模式值是一组标志(或 0),它们控制扫描行为。
const (
ScanComments Mode = 1 << iota // 返回注释作为注释标记
dontInsertSemis // 不要自动插入分号-仅用于测试
)
- Init()函数: Init 通过在 src 的开头设置扫描器来让扫描器 s 标记文本src,扫描器使用文件集文件来获取位置信息,并为每一行添加行信息。当重新扫描相同的文件时,可以重复使用相同的文件,因为已经存在的行信息被忽略了。如果文件大小与 src 大小不匹配,Init 会导致 panic。如果遇到语法错误且 err 不是nil,则调用 Scan 将调用错误处理程序 err。此外,对于遇到的每个错误, Scanner 字段 ErrorCount 增加 1,mode 参数决定如何处理注释。
Tips: 注意,如果文件的第一个字符有错误,Init 可能会调用 err。
- updateLineInfo()函数: updateLineInfo 将输入的注释文本在 offset off 处解析为一个行指令。如果成功,它将根据 line 指令更新下一个位置的行信息表。
- isLetter()函数: 判断 rune 字符是否为
a-z、A-Z、_或符合utf8.RuneSelf定义的字符。
func isLetter(ch rune) bool {
return 'a' <= ch && ch <= 'z' || 'A' <= ch && ch <= 'Z' || ch == '_' || ch >= utf8.RuneSelf && unicode.IsLetter(ch)
}
- isDigit() 函数: 判断 rune 字符是否为
0-9或符合utf8.RuneSelf定义的字符。
func isDigit(ch rune) bool {
return '0' <= ch && ch <= '9' || ch >= utf8.RuneSelf && unicode.IsDigit(ch)
}
- digitVal()函数: 返回 rune 字符对应的整型数。
- scanEscape()函数: scanEscape 解析转义序列,其中 rune 是接受的转义引号,在语法错误的情况下,它在错误字符处停止(不使用它)并返回 false,否则返回 true。
2.2 token.go 代码代码简介
token.go 文件位于 go/src/go/token 目录下。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









