







 本文深入探讨了MySQL中ORDER BY操作的工作原理,包括全字段排序和ROWID排序的流程,并给出了优化建议。通过实验数据展示了如何利用存储过程插入数据,以及使用EXPLAIN分析查询性能。通过调整max_length_for_sort_data参数,避免全字段排序,减少回表操作。最后,提出了创建合适的联合索引来进一步提升查询效率。
本文深入探讨了MySQL中ORDER BY操作的工作原理,包括全字段排序和ROWID排序的流程,并给出了优化建议。通过实验数据展示了如何利用存储过程插入数据,以及使用EXPLAIN分析查询性能。通过调整max_length_for_sort_data参数,避免全字段排序,减少回表操作。最后,提出了创建合适的联合索引来进一步提升查询效率。
MySQL学习笔记-order by工作原理
1.表结构

CREATE TABLE `t` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL DEFAULT '',
`age` int unsigned NOT NULL DEFAULT '0',
`addr` varchar(128) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `city` (`city`) USING BTREE
) ENGINE=InnoDB;
2.插入实验数据
delimiter;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=20000)do
if i<=15000 then
insert into t values(i,SUBSTRING("杭州杭州杭州杭州杭州",1,RAND()*10), SUBSTRING("爱因诗贤爱因诗贤爱因诗贤",1,RAND()*10), RAND()*100,SUBSTRING("地址地址地址地址地址",1,RAND()*10));
else
insert into t values(i,"武汉", SUBSTRING("爱因诗贤爱因诗贤爱因诗贤",1,RAND()*10), RAND()*100,SUBSTRING("地址地址地址地址地址",1,RAND()*10));
end if;
set i=i+1;
end while;
end;
delimiter ;
call idata();
Tips:使用存储过程插了
20000条数据,其中插入了5000条city='武汉'的数据。
3.执行排序查询
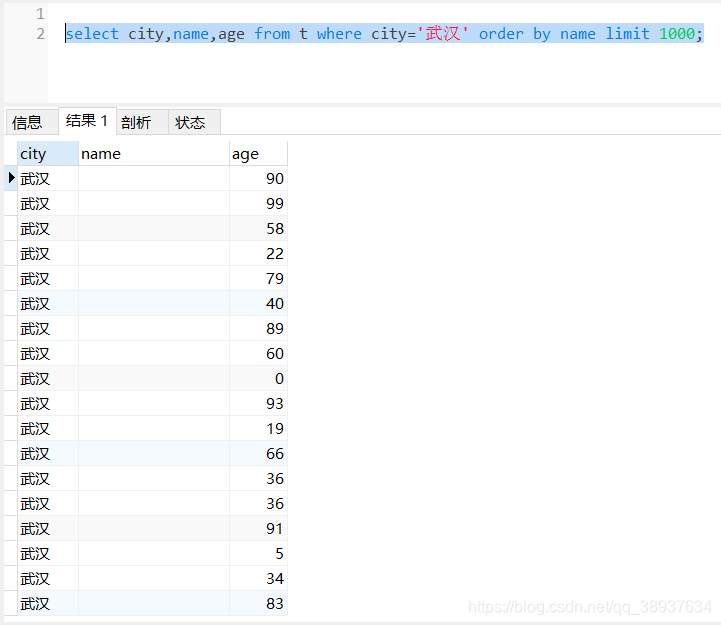
select city,name,age from t where city='武汉' order by name limit 1000;
执行结果如下图:
4.explain 分析
explain select city,name,age from t where city='武汉' order by name limit 1000;

Tips:可以看到扫描行数
rows=5000行,Extra中的Using filesort表示需要排序。
5.全字段排序流程
若查询要返回的字段很少,每行要返回的结果集数据比较小,内存中能同时存放的行数比较多,全字段排序流程如下:
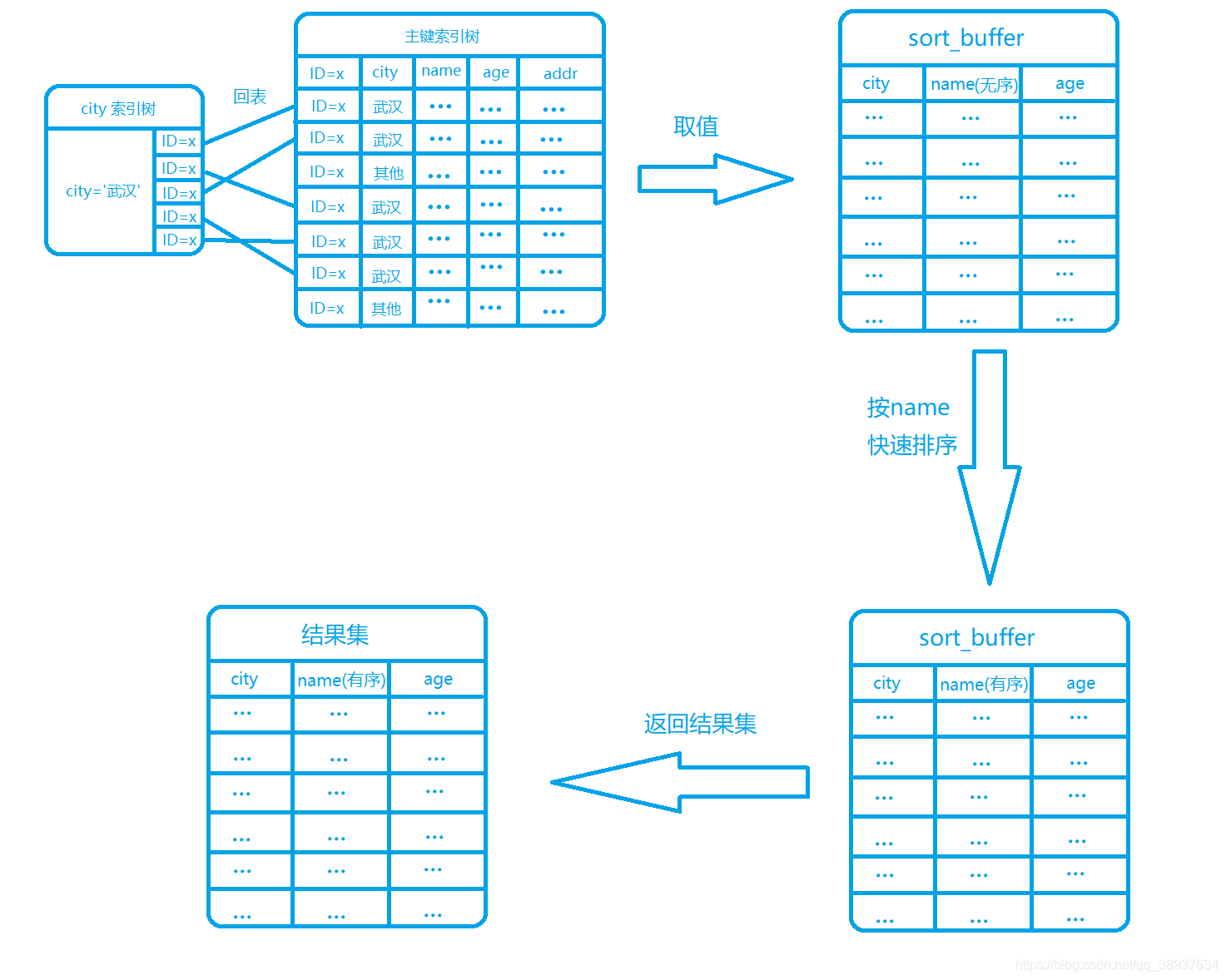
- **(1)**初始化
sort_buffer,确定放入name、city、age这三个字段 - (2) 从二级索引树
city上找到第一个满足city='武汉'条件的主键id - **(3)**然后到主键索引树上通过
id取出整行,取name、city、age三个字段的值,存入sort_buffer中 - **(4)**从二级索引树
city取下一个记录的主键id; - **(5)**重复步骤
(3)、(4)直到city的值不满足查询条件为止 - **(6)**对
sort_buffer中的数据按照字段name做快速排序 - **(7)**按照排序结果取前
1000行返回给客户端
Tips:
MySQL会给每个线程分配一块内存用于排序,称为sort_buffer,其中第(6)步按照name快速排序,可能在内存中完成,也可能需要外部排序,取决于参数sort_buffer_size的大小。
6.rowid 排序流程
如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差,先设置一个参数,可以让 MySQL 采用 rowid 的方式来排序:
SET max_length_for_sort_data = 16;
Tips:
max_length_for_sort_data表示用于排序的行数据的长度的参数,表示如果单行的长度超过这个值,MySQL就认为单行太大,要换一个排序算法,city、name、age这三个字段的定义总长度是36,比16大。
rowid 排序流程如下:
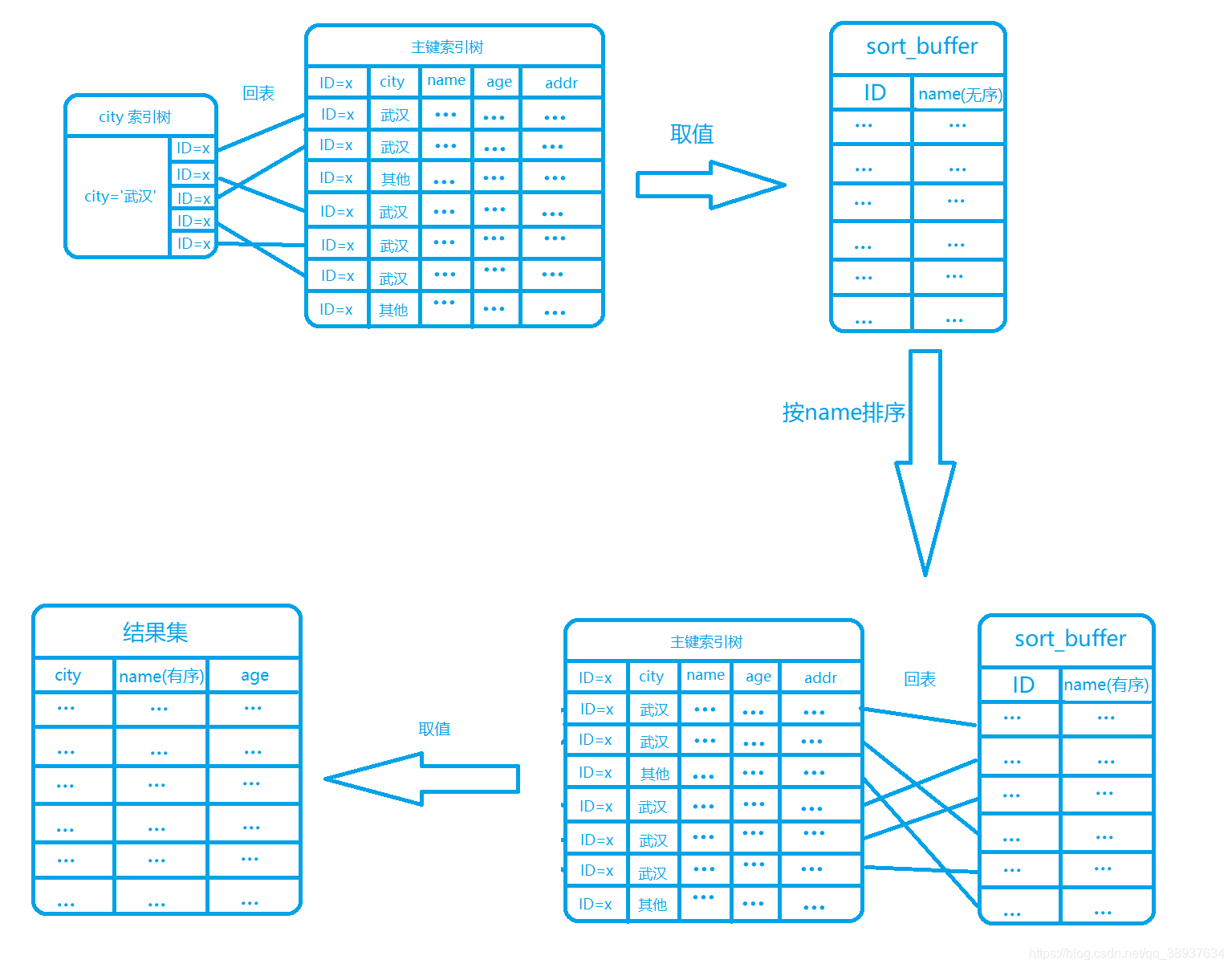
- **(1)**初始化
sort_buffer,确定放入两个字段,即name和id - (2) 从二级索引树
city上找到第一个满足city='武汉'条件的主键id - **(3)**然后到主键索引树上通过
id取出整行,取name、id这两个字段,存入sort_buffer中 - **(4)**从二级索引树
city取下一个记录的主键id; - **(5)**重复步骤
(3)、(4)直到city的值不满足查询条件为止 - **(6)**对
sort_buffer中的数据按照字段name排序 - **(7)**遍历排序结果,取前
1000行,并按照id的值回到原表中取出city、name和age三个字段返回给客户端
Tips:相比于全字段排序,
rowid排序多了一次回表
7.优化建议
- 上述排序是按照
name字段进行排序的,如果name字段本来就是有序的,那么在排序查询就不需要使用排序这个步骤,因此可以建立city、name联合索引:
ALTER TABLE `t` DROP INDEX `city`,ADD INDEX `city_user`(`city`, `name`) USING BTREE;
explain 分析如下:
explain select city,name,age from t where city='武汉' order by name limit 1000;

Tips:此时
Extra中没有Using filesort了,因此不需要排序了。
- 由于最后返回字段总共包含
city、name、age三个字段,为了减少回表次数,可以在上面基础上,直接建立city、name、age联合索引:
ALTER TABLE `t` DROP INDEX `city`,
ADD INDEX `city_user_age`(`city`, `name`, `age`) USING BTREE;
扫码关注


















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









