






 本文详细介绍了浏览器的工作原理,从用户界面到渲染引擎,再到网络和数据存储的各个组成部分。解析HTML构建DOM树和Render树的过程被阐述,以及渲染引擎如何逐步完成页面展示。此外,还详细解析了从域名解析到HTTP请求发送的整个流程,涉及TCP连接的建立和请求头信息。最后,概述了浏览器发送HTTP请求的步骤,从应用层到网络层的数据封装过程。
本文详细介绍了浏览器的工作原理,从用户界面到渲染引擎,再到网络和数据存储的各个组成部分。解析HTML构建DOM树和Render树的过程被阐述,以及渲染引擎如何逐步完成页面展示。此外,还详细解析了从域名解析到HTTP请求发送的整个流程,涉及TCP连接的建立和请求头信息。最后,概述了浏览器发送HTTP请求的步骤,从应用层到网络层的数据封装过程。
浏览器工作原理
浏览器工作原理
浏览器功能:将用户选择的web资源呈现出来
浏览器组成:
- 用户界面(包括地址栏、前进后退等)
- 浏览器引擎(用于查询及操作渲染引擎的接口)
- 渲染引擎(用于显示请求的内容,如果请求内容是html,它负责解析html及css)
- 网络(用于完成http请求)
- UI后端(用于绘制基本组件)
- JS解释器(解释执行JS代码)
- 数据存储(属于持久层)
渲染引擎执行过程:
解析html以构建dom树(html中标签对应dom树的节点)
-> 构建render树(由dom节点以及节点的css组成)
-> 布局render树(确定每个节点在屏幕上的确切位置)
-> 绘制render树(通过UI后端绘制每个节点)
逐步完成,边解析边显示

解析HTML构建dom:html本身是一个字符串,要转为dom树需要经过解析器解析
浏览器中输入url后执行过程
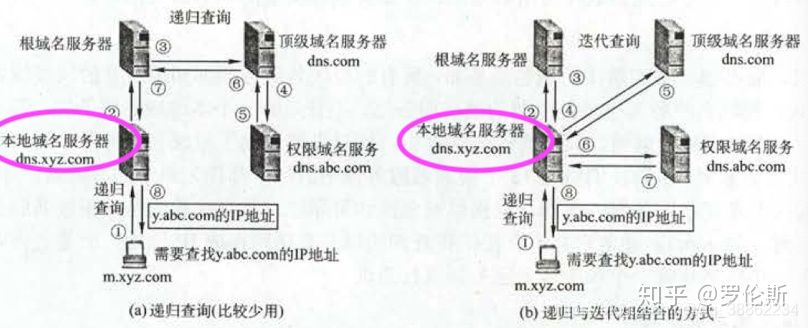
- 域名解析(获取IP地址):
1. 浏览器搜索自己的DNS缓存(域名与IP地址的对应表)
2. 搜索操作系统的DNS缓存
3. 搜索本地域名服务器缓存
4. 本地域名服务器向根域名服务器发送请求获取顶级域名服务器,本地域名服务器向顶级域名服务器发送请求获取权限域名服务器地址,本地域名服务器向权限域名服务器发送请求获取IP地址
5. 本地域名服务器缓存IP地址,同时返回给操作系统
6. 操作系统缓存IP地址,同时返回给浏览器
7. 浏览器得到IP地址
- 浏览器发送HTTP请求
- 传输层选择TCP或UDP封装应用层数据,添加TCP首部
- 网络层,根据目标IP地址获取MAC地址,添加IP首部
- 数据链路层,IP数据封装成MAC帧,建立TCP连接(三次握手),添加以太网首部
浏览器发送HTTP请求的请求头
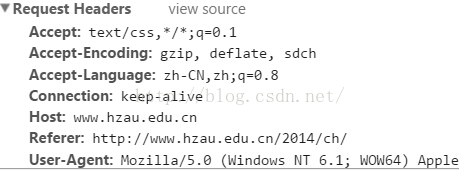
Accept:浏览器端可以接受的媒体类型
TCP建立连接3次握手

















 2732
2732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









