







1 订阅与发布
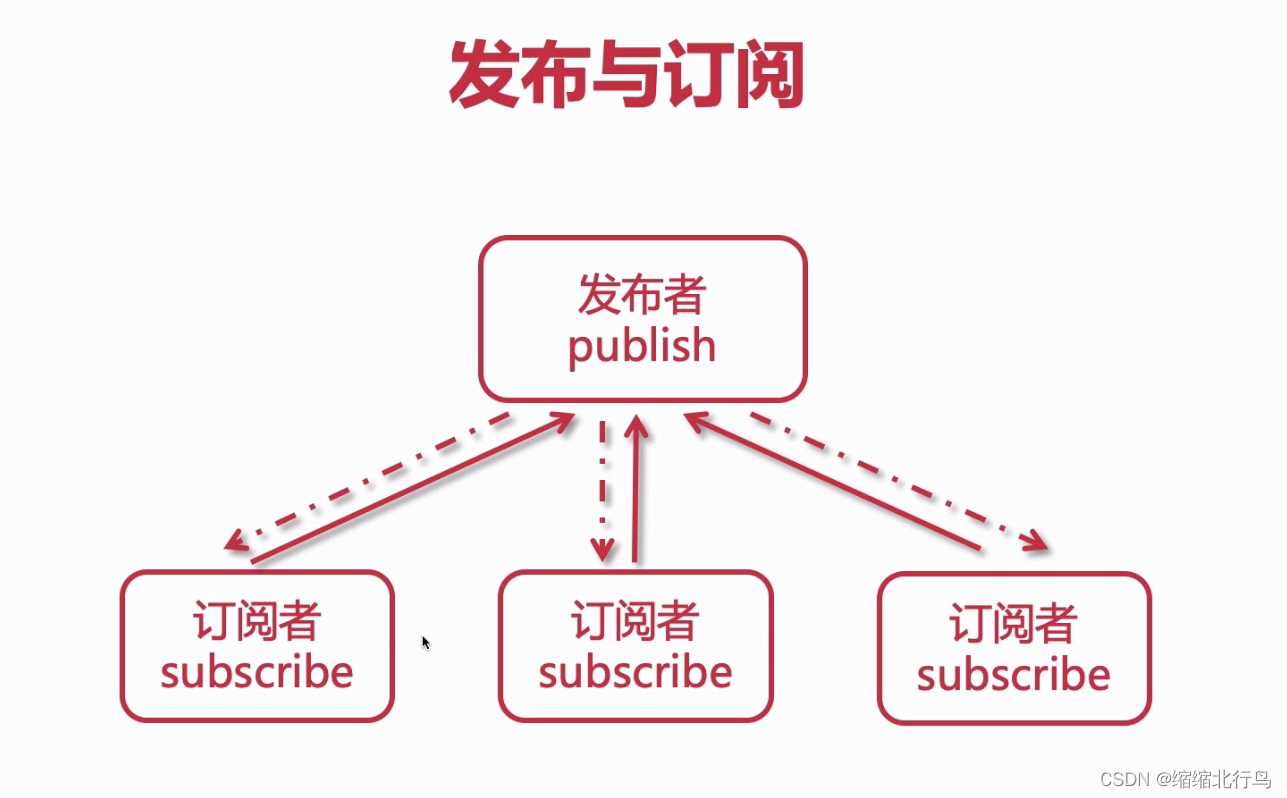
Redis 分布与订阅功能本质是基于消息去实现,它会存在一个发布者去分发 publish 消息,其它订阅 subscribe 了该发布者的订阅者就可以接受相应的消息。
订阅者使用 subscribe [channel...] 订阅频道,如:
subscribe NBA
或者使用 psubscribe [pattern] 订阅符合通配符的相关频道,如:
psubscribe NB*
发布者使用 publish channel msg 发布消息,如下,此时对应的订阅者就会收到相应的信息:
publish NBA Curry
虽然 Redis 可以实现类似消息队列的机制,不过一般来讲,企业都只是会使用 Redis 充当缓存的角色
2 Redis 持久化机制
Redis 的缓存数据是存放在内存里的,一旦服务器发生宕机等异常,内存里的缓存数据会消失,而 Redis 的持久化机制会将缓存信息写入到磁盘中,等再一次启动 Redis 的时候,它就可以恢复相应数据,Redis 有两个持久化机制。
2.1 RDB(Redis DataBase)
RDB:每隔一段时间,把内存中的数据写入磁盘的临时文件,作为快照,恢复的时候把快照文件读进内存。
- 优势:
- 每隔一段时间备份,全量备份
- 灾备简单,可以远程传输(因为它的备份是一个单独文件)
- 子进程备份的时候,主线程不会有任何io操作(不会写入修改或删除),保证备份数据的完整性
- 相对AOF来说,当有更大文件的时候可以快速重启恢复
- 劣势:
- 发生故障时。可能会丢失最后一次备份数据
- 子进程所占用的内存会与父进程一样,导致CPU负担
- 只能定时备份,即无法实现实时备份
核心配置文件中的相应配置,进入配置文件中搜索 SNAPSHOTTING 后,其下方配置就是 RDB 的配置:
默认保存机制,其中 seconds 表示延迟时间,changes 表示修改个数,如 save 900 1 表示当一个 key发生改变,则 900 秒后备份:
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving completely by commenting out all "save" lines.
#
# It is also possible to remove all the previously configured save
# points by adding a save directive with a single empty string argument
# like in the following example:
#
# save ""
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes 表示备份保存出错后就会停止写操作,如果修改成 no 就可能会导致数据不一致
rdbcompression yes 表示启动 rdb 压缩
rdbchecksum yes:使用 CRC64 算法对数据校验
2.2 AOF(Append Only File)
如果追求数据的完整性,就需要考虑使用 AOF 了。
AOF 以日志的形式记录用户请求的写操作,文件会以最加的形式而不是修改的形式,Redis 的 AOF 恢复其实就是把追加的文件从开始到结尾读取执行写操作。
- 优势:
- AOF更加耐用,可以以秒级别为单位备份,即 AOF 可以每秒备份一次,使用
fsync操作,此时如果发生问题,也只会丢失最后一秒的数据,大大增加了可靠性和数据完整性。 - 以 log 日志形式追加
- 当数据太大的时候,redis 可以在后台自动重写 AOF,缩小文件大小。当 Redis 继续把日志追加到老的文件中时,重写也是非常安全的,不会影响客户端的读写操作。
- AOF 日志包含所有写操作,会更加便于 Redis 的解析恢复
- AOF更加耐用,可以以秒级别为单位备份,即 AOF 可以每秒备份一次,使用
- 劣势
- 相同的数据,同一份数据,AOF 比 RDB 大
- 针对不同的同步机制,AOF 会比 RDB 慢
核心配置文件中的相应配置,进入配置文件中搜索 APPEND ONLY MODE 后,其下方配置就是 AOF 的配置:
#每次操作都会备份,安全并数据完整,但性能差、慢
#appendfsync always
#不同步
#appendfsync no
#每秒备份
appendfsync everysec
重写的时候,是否要同步将新的操作添加到日志中,no 可以保证数据安全
no-appendfsync-on-rewrite no
重写机制:为了避免文件越来越大,自动优化压缩命令,会fork一个新的进程去完成重写动作,新进程里的内存数据会被重写,此时旧的 AOF 文件不会被读取使用,类似 RDB。下面代码是 AOF 的重写配置,它的意思是:当前 AOF 文件的大小是上一次 AOF 大小的 100%时,且文件体积达到 64M 时,就会触发重写。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
RDB 和 AOF 可以结合一起做持久化,此时Redis恢复加载 AOF。RDB 做冷备,可以在不同时期对不同版本做恢复,AOF 做热备,保证数据仅仅只有1秒的损失。当 AOF 破损不可用时,再用 RDB 恢复。
3 主从架构
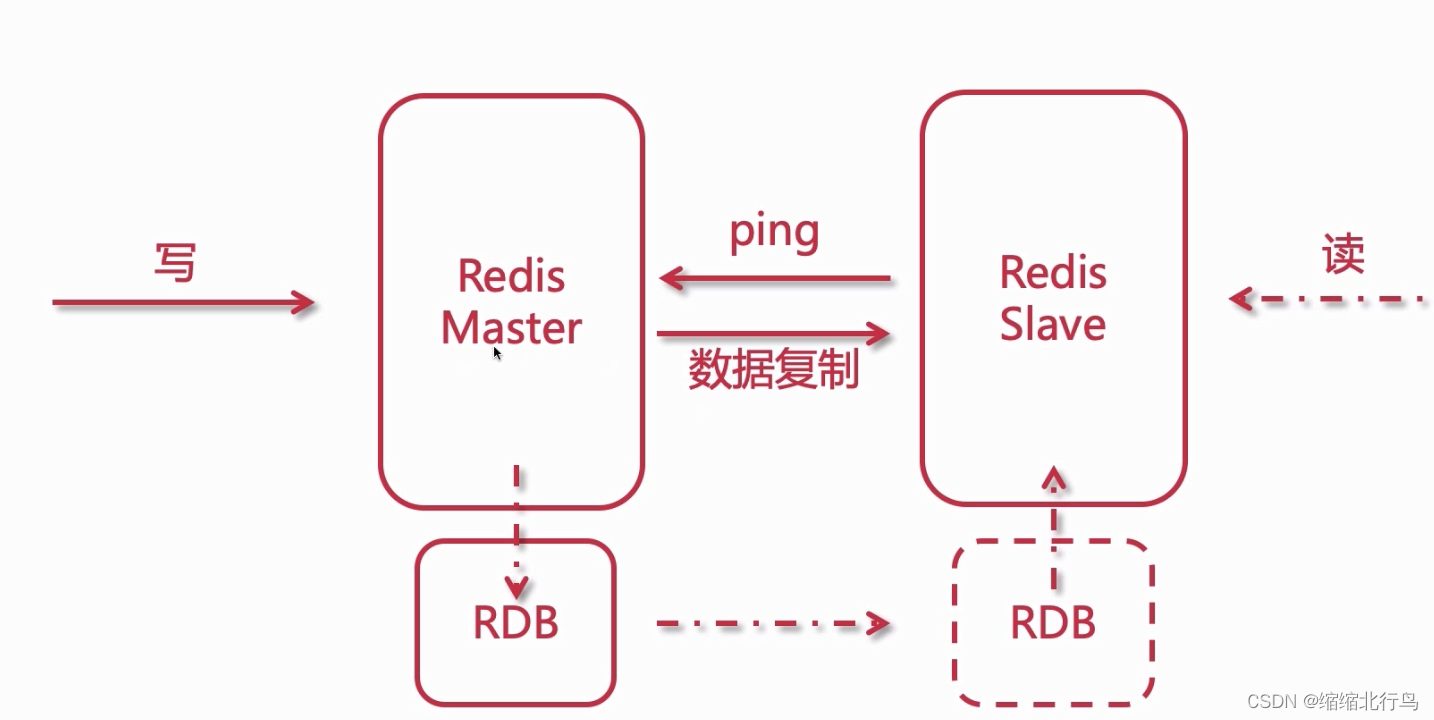
Redis 的主从架构也可以看作为读写分离的架构,主节点负责写操作,从节点负责读操作。
使用
info replication命令可以查看当前 Redis 的主从信息。
在核心配置文件中配置以下信息,可将 Redis 配置为从节点。
# replicaof <masterip> <masterport>
# 设置父节点 IP 及端号
replicaof 192.168.1.9 6379
# masterauth <master-password>
# 设置父节点的 Redis 密码
masterauth 123456
# 从节点 Redis 只读
replica-read-only yes
主从复制默认的方式是磁盘复制,即主节点导出 RDB 数据传递到从节点下载到从节点的磁盘中,并由从节点完成复制,而如果服务器的硬盘是机械硬盘,速度比较慢,而此时内网的速度比较快,就可以使用无磁盘化复制方式。
repl-diskless-sync yes
4 Redis 的缓存过期机制
设置了 expire 的 key 缓存过期了,服务器的内存可能还是会被占用, 这是因为 Redis 的两种删除策略:
- 主动定时删除:定时随机的检差过期的 key,如果过期则清理删除,每秒检查次数在核心配置文件中的
hz配置 - 被动惰性删除:当客户端请求一个已经过期的 key 的时候,那么 Redis 会检查这个 key 是否已过期,如果过期就会清除,这种策略对 CPU 比较友好,当相应的内存占用会比前者高
5 内存淘汰机制
如果内存占满了,可以使用硬盘,当此时就没有意义了,因为硬盘慢,会影响性能。所以内存占用满了之后,Redis 提供了一套缓存淘汰机制:MEMORY MANAGEMENT,它清理那些没有设置 expire 的 key
# 当内存到达该使用率时,开始清理缓存
# maxmemory <bytes>
maxmemory 5000
# 清理方式
# maxmemory-policy noeviction
# noeviction 旧缓存永不清理,新缓存设置的时候会返回错误
# allkeys-lru:清除最少用的旧缓存,然后保存新的缓存
# allkeys-random:在所有缓存中随机删除
# volatile-lru:在那些设置了 expire 的缓存中清除最少用的旧缓存
# volatile-random:在那些设置了 expire 的缓存中随机删除
# volatile-ttl:在那些设置了 expire 的缓存中删除即将过期的
maxmemory-policy noeviction
6 缓存穿透
当客户可以直接跳过 Redis 访问到数据库,比如说用户指定访问数据A,此时 Redis 并没有该数据,正常情况下,它就会直接访问到数据库取出数据A并缓存到 Redis 中,如果此时数据库也没有数据A这个数据,而后端此时又没有编写设置 Redis 该数据A为空的逻辑,那么此后用户每次访问数据A的数据还是会相应的访问到数据库,万一请求量大,此时数据库的性能就会受到考验,严重可能导致奔溃,这种情况就是 缓存穿透。
解决缓存穿透最简单的方法就是在第一次访问数据A的时候,就直接在 Redis 中将数据A设置为空值,此时也可以为此设置过期时间,这样此后用户每次访问都会从 Redis 中获取数据,而不是直接访问到数据库中。
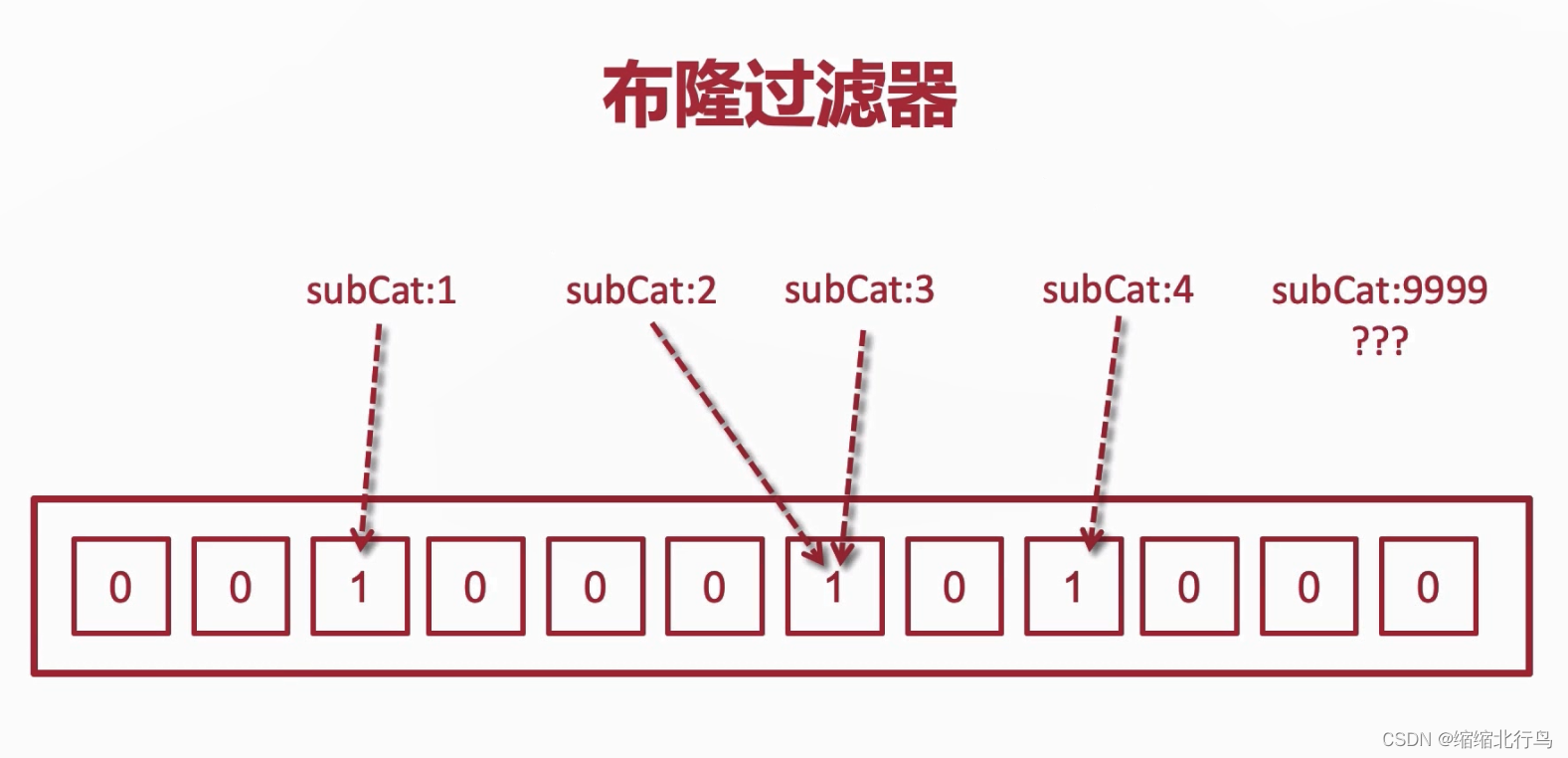
还有一种方法叫做 布隆过滤器,它实质就是一个拦截器,它在请求到 Redis 之前进行一个拦截,如下图,它由一个二进制的数组存储相应的 Key 是有值,如果拦截之后发现有值才会继续放行到 Redis 中进行取值。由于这个实现起来需要额操作,同时假如 subCat:2 这个数值后期在数据库删除了,布隆过滤器也无法实现同步,因为它该对应的节点不仅仅代表 subCat:2 是否有值,还代表 subCat:3 是否有值。而且使用布隆过滤器也会有一定概率的bug发生,所以就不作推荐了。
7 缓存雪崩
当 Redis 中的过期数据在同一时间内集体过期,此时客户的请求有巨大,从而直接访问到数据库中,导致数据库奔溃,这种情况就是 缓存雪崩。
缓存雪崩无法完全避免,只能尽量地减低这个情况的发生:
- 设置缓存永不过期
- 过期时间错开
- 多缓存结合,比如添加 Memcache 一并使用
- 采购第三方 Redis


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









