







实现索引的方法
- 使用hashmap实现索引就不能实现范围查询。
- 使用红黑树实现索引会存在树太高的情况,因为每查找一层就需要向磁盘发起一次请求,导致io消耗过大,消耗时间长,而且磁盘每个block是4k,使用红黑树存在空间浪费的现象。
这时候就需要更优的数据结构来存储数据,其中B树,B+树,B*树便是很好的一个选择。
B树
b树又叫多路查找树,b树中所有节点的孩子节点数的最大值称为b树的阶。其实就是将二叉搜索树合并。
M阶B树有一些重要特性:
- 定义任意非叶子结点最多只有M个儿子;且M>2;
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M];
- 每个结点存放至少M/2(取上整)-1和至多M-1个关键字;(至少2个关键字,根节点至少一个关键字);
- 非叶子结点的关键字个数=指向儿子的指针个数-1;
- 非叶子结点的关键字:K[1], K[2], …, K[m-1],m<M+1;且K[i]< K[i+1] ;
- 非叶子结点的指针:P[1], P[2], …, P[m];其中P[1]指向关键字小于K[1]的子树,P[m]指向关键字大于K[m-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
- 所有叶子结点位于同一层;
b树的搜索
- 先在节点内部使用二分搜索搜索元素。
- 如果命中,搜索结束。
- 如果未命中,再去对应的子节点中搜索元素。
查找算法时间复杂度O(logn),其思想与二分查找类似。
b树的添加
- 首先使用b树搜索,搜索到指定适合的位置放入。
- 如果对于m阶b树其值的个数超过m-1个,就需要进行上溢操作。
上溢
比如现在有个5阶b树:
- 插入34后不满足5阶b树的性质,则需要上溢
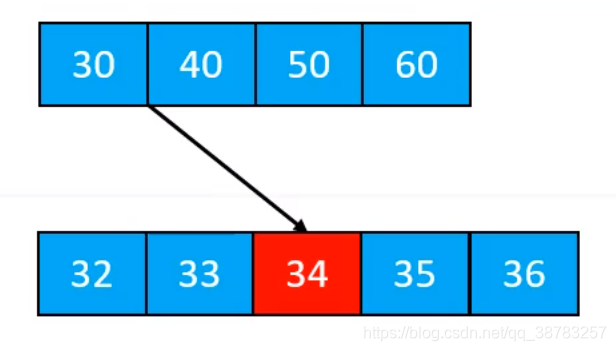
- 上溢后需要父节点再次上溢
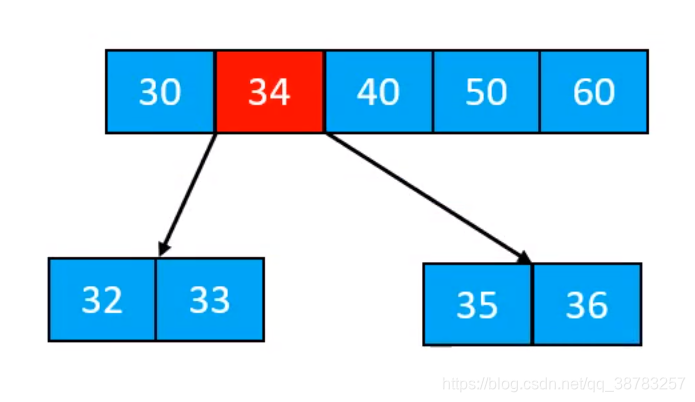
- 这个是最终结果
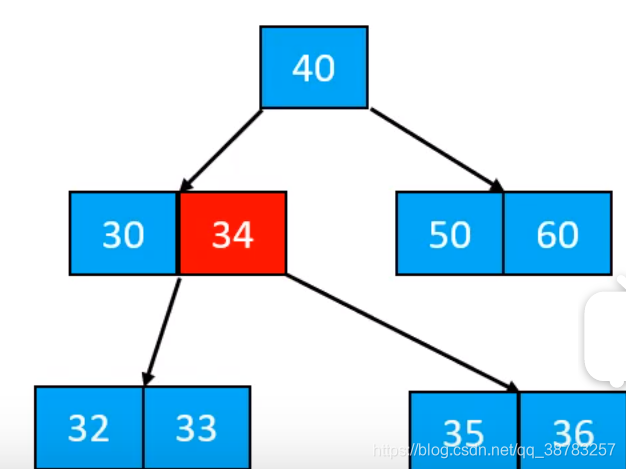
b树的删除
- 如果删除的值在叶子节点,那么直接删除。
- 如果删除的值在非叶子节点:
- 先找到前驱(值的左树的最大值)或者后继(值的右树的最小值)元素。
- 当前值替换成该元素的值。
- 删除前驱或者后继。
因为b树有个性质:每个结点存放至少M/2(取上整)-1和至多M-1个关键字,如果叶子节点删除后值的个数小于M/2(取上整),就需要进行下溢操作。
下溢
下溢分2种情况:
- 如果兄弟节点的个数大于等于M/2(取上整),那么借一个数(旋转)
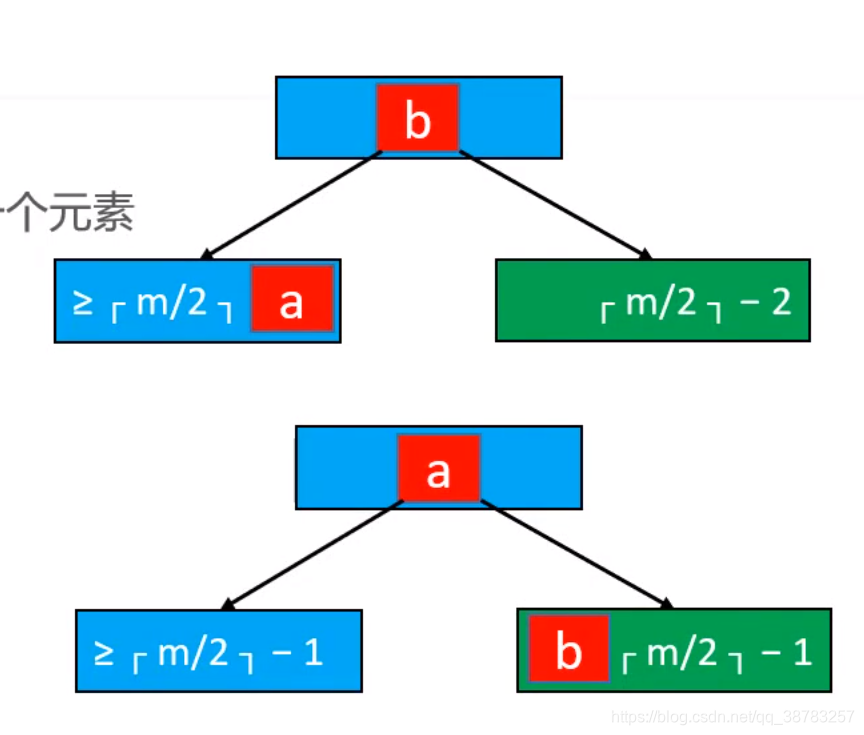
- 假如兄弟节点只有M/2-1不能借了,那么只能合并,也就是下溢

如果父节点值的数量又小于M/2-1了,递归下溢。
B+树
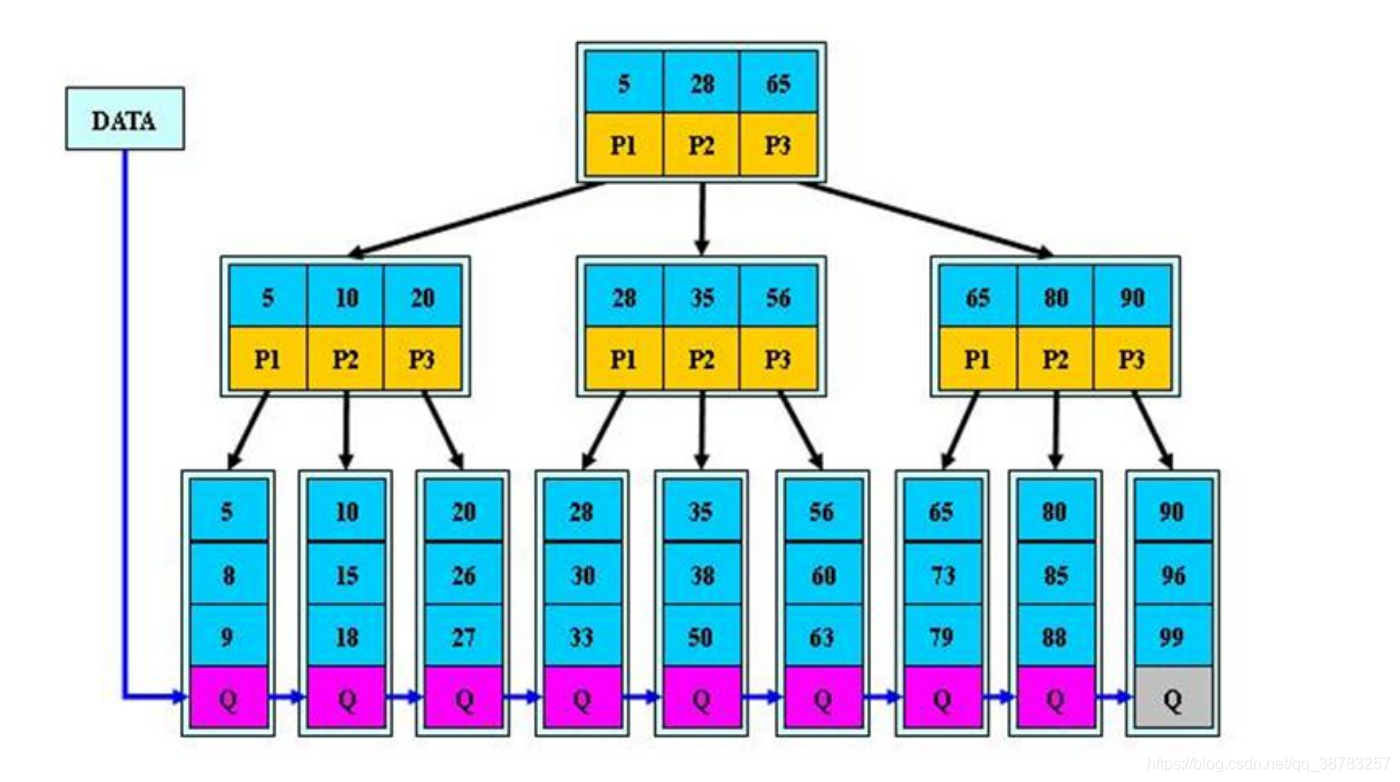
b+树的本质其实就是b树+链表。b树中不存放数据,只存放索引,而链表中存放数据。

















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









