







多跳几个坑,你就会明白的。
先看完这个:
先看完这个:
先看完这个:
我使用的环境是node.js 代码使用ts格式,当然js也是可以用的
先打开网站,然后找到想要获取的内容,按下F12,找到数据对应的div(或者其他元素)的id然后“盘”它
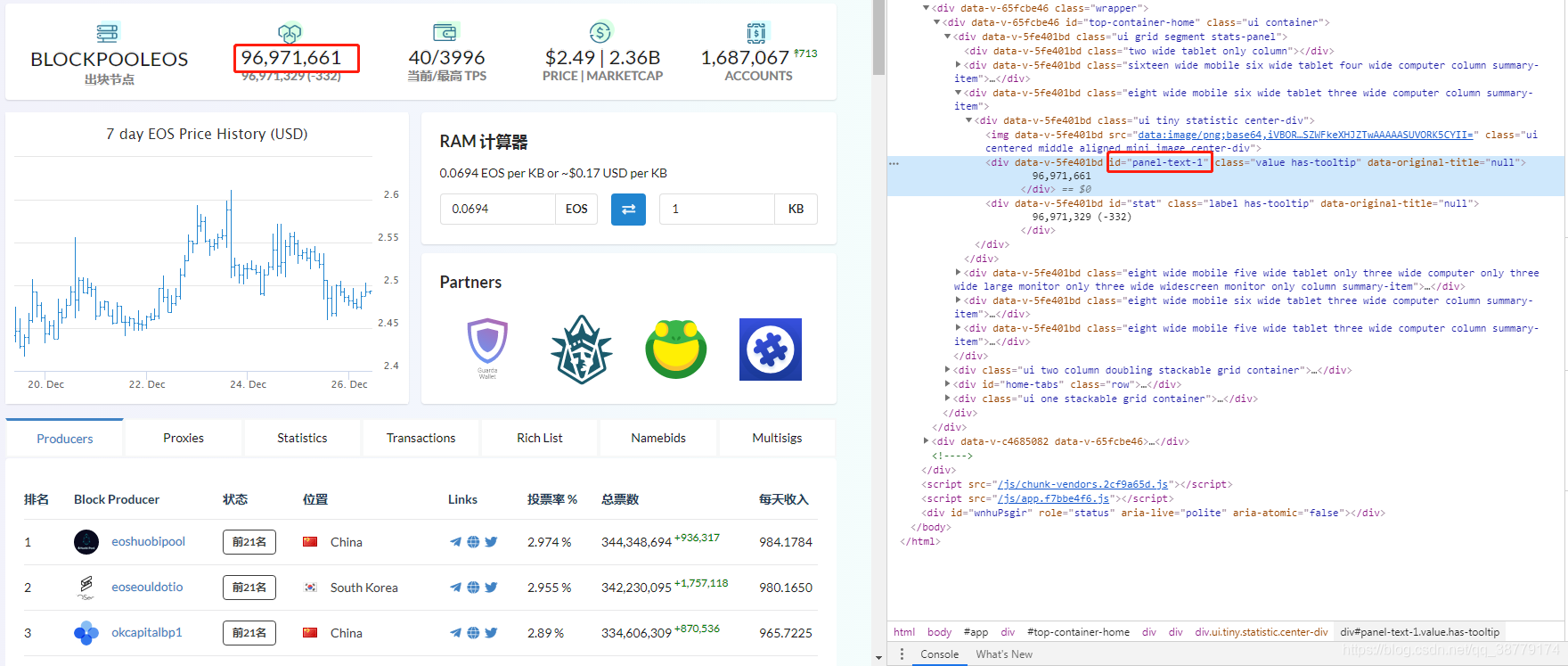
下面是干货:
const puppeteer = require('puppeteer');
(async () => {
try {
// 创建一个浏览器实例 Browser 对象
let browser = await puppeteer.launch({
// 是否不显示浏览器, 为true则不显示,
'headless': true,
});
//创建 Page 对象,这样就能从page(界面)上获取信息了
let page = await browser.newPage();
// 设置浏览器信息
const UA = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/63.0.3239.84 Chrome/63.0.3239.84 Safari/537.36";
await Promise.all([
page.setUserAgent(UA),
// 允许运行js
page.setJavaScriptEnabled(true),
// 设置页面视口的大小
page.setViewport({ width: 1000, height: 1080 }),
]);
// 这个是要访问的网站地址,这个网址是区块链网址不需要登录,所以比较简单
let chapter_list_url = `https://bloks.io/`
// 打开网址,await是异步的方式打开,await和async是一起出现的,想使用await,方法名前必须加async
await page.goto(chapter_list_url);
let aaa = "";
//定时器,两秒获取一次数据
setInterval(async function () {
// 使用css选择器的方式获取页面中的数据
aaa = await page.$eval('#panel-text-1', el => el.innerText);
//打印爬取的数据
console.log(aaa)
}, 2000);
} catch (err) {
console.log(err)
}
})()

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









