






1.报错场景
使用多张910B卡推理大模型时报错显存不足,8张卡远远足够用,说明不是因为模型参数太大导致的。NPU out of memory. Tried to allocate 88.00 MiB (NPU 1; 29.50 GiB total capacity; 28.30 GiB already allocated; 28.30 GiB current active; 29.59 MiB free; 29.50 GiB allowed; 28.88 GiB reserved in total by PyTorch)
2.解决方法
(1)关闭多余进程
npu-smi info,先看下有没有其它进程在用显卡,如果有的话,kill -9 掉对应的进程;
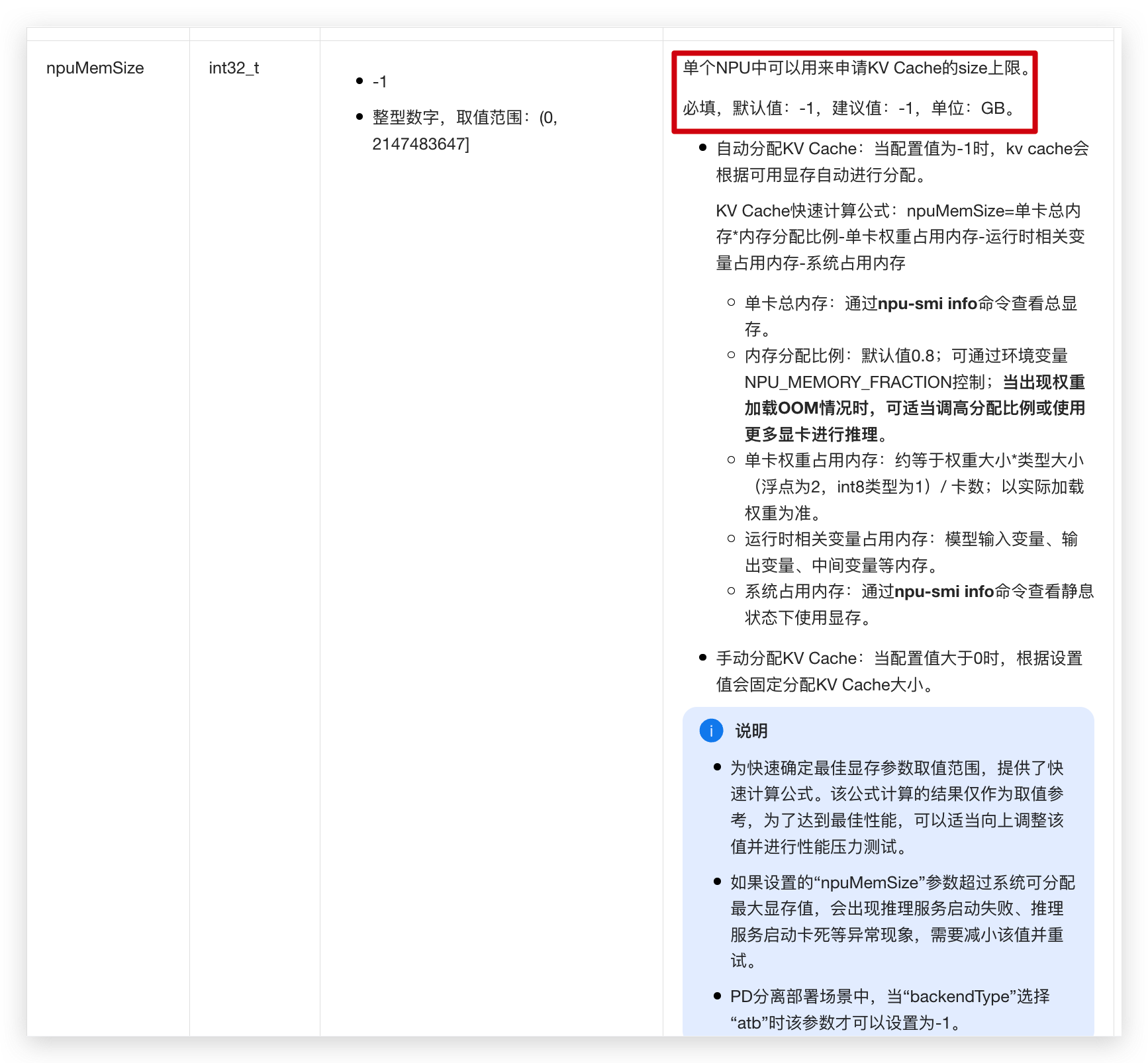
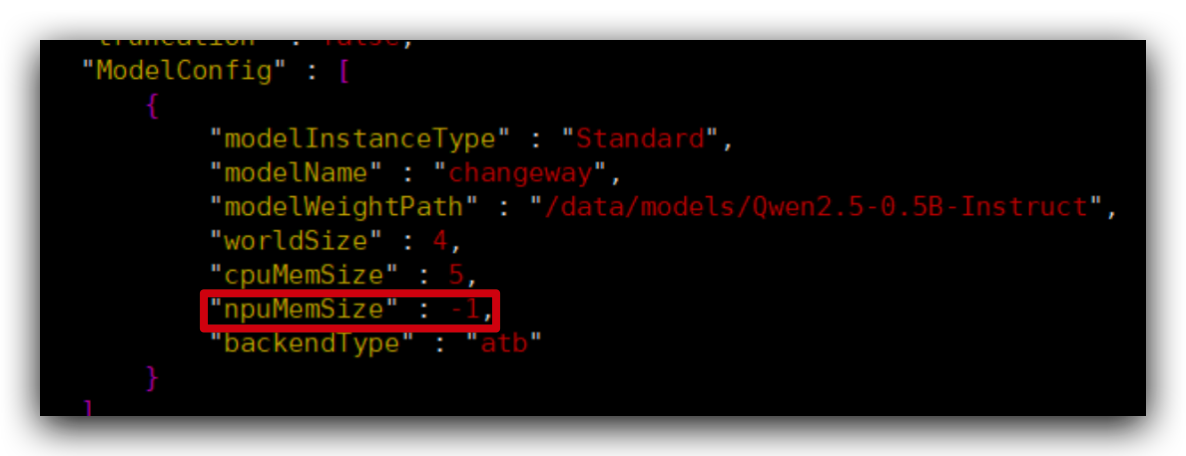
(2)修改显存配置
编辑mindie配置文件,/usr/local/Ascend/mindie/latest/mindie-service/conf/config.json。里面ModelConfig中有个参数npuMemSize,默认值是-1(代表无限制),把它改小点,比如8。

















08-05
 1865
1865
1865
07-06
20万+
20万+
04-12
1万+
1万+
01-24
3232
3232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









