







 本文介绍如何使用SQL查询优化器的提示来控制执行计划,包括优先级、延迟插入、直连查询、结果集大小预测、结果缓冲、缓存控制、行锁控制、索引强制和优化器参数调整。同时,针对不同类型的查询,如COUNT()、关联查询、子查询、GROUP BY和DISTINCT以及LIMIT分页,提供具体的优化策略。
本文介绍如何使用SQL查询优化器的提示来控制执行计划,包括优先级、延迟插入、直连查询、结果集大小预测、结果缓冲、缓存控制、行锁控制、索引强制和优化器参数调整。同时,针对不同类型的查询,如COUNT()、关联查询、子查询、GROUP BY和DISTINCT以及LIMIT分页,提供具体的优化策略。
查询优化器的提示
如果对于执行计划不是很满意,可以使用优化器提供的几个提示来控制最终执行计划。
以下为常见的提示:
- HIGH_PRIORITY和LOW_PRIORITY: 类似于线程优先级,LOW_PRIORITY可能让该语句一直处于等待状态(可作用于全局,可用HIGH_PRIORITY取消),查询优先顺序:HIGH_PRIORITY>无设置>LOW_PRIORITY 其他顺序:无设置>LOW_PRIORITY 。仅对表锁有效,不过可能会引起MyIASM并发插入被禁用导致失效
- DELAYED: 对INSERT和REPLACE有效。会立即返回结果与将行数据写于缓存中,在表空闲时再将数据批量写入。不过不是所有引擎都支持并且会导致函数LAST_INSERT_ID()无法正常工作。
- STRAIGHT_JOIN: 1.用于SELECT后表示,本次查询中连接表的顺序如SQL所示。2.用于两个关联表名字之间,用于固定这俩的顺序。
- SQL_SMALL_RESULT和SQL_BIG_RESULT: 只对SELECT有效,告诉优化器,在DISTINCT语句和GROUP BY查询中,如果是SMALL,会告诉优化器结果很小,则集放在内存中的索引临时表,以避免排序操作。另一个,则树木结果集可能会很大,建议使用磁盘临时表做排序操作。
- SQL_BUFFER_RESULT: 将查询结果放到一个临时表中(服务器端的缓存),尽快释放表锁。
- SQL_CHACE和SQL_NO_CHACE: 是否将查询结果缓存(客户端缓存)。
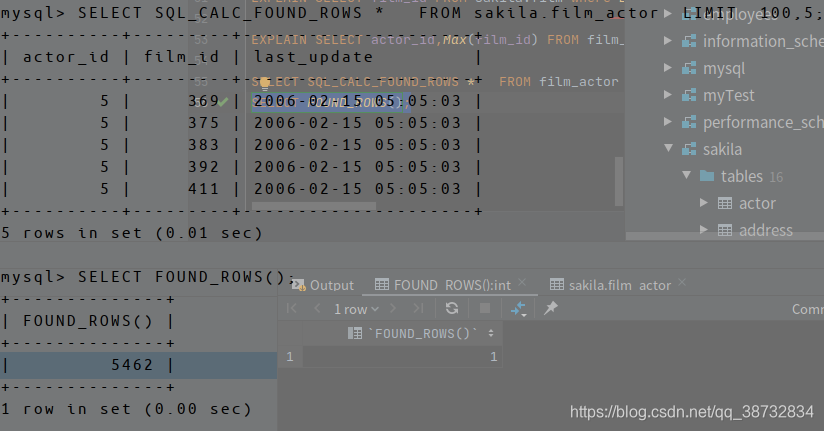
- SQL_CALC_FOUND_ROWS: 不建议使用,会扫描所有符合要求的行,返回行数(可使用FOUND_ROW()获取),而不是LIMIT限定的行数。(IDEA获取不到准确行数,命令行到时阔以)
- FOR UPDATE和LOCK IN SHARE MODE: 主要用于控制SELECT语句的锁机制,但只对实现了行级锁的存储引擎有效(INNODB),对符合条件的数据行加锁。不过可能会导致一些优化无法使用,比如索引覆盖扫描,InnoDB无法在不访问主键的情况下排他地锁定行(MVCC),滥用也会导致锁竞争情况产生。
- UES INDEX、IGNORE INDEX和FORCE INDEX: 告诉优化器使用或者不使用某个索引。第一个和第三个作用类似,除了程度比较强以外。
参数:
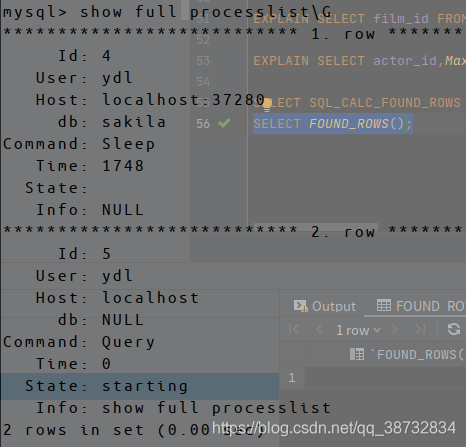
- optimizer_search_depth: 穷举执行计划时的限度,如果查询长时间处于“Statistics”状态,可以考虑调低此参数。使用show full processlist来查看状态
- optimizer_prune_level 默认打开,根据需要扫描的行数决定是否跳过某些执行计划
- optimizer_switch 包含了一些开启/关闭优化器特征的标志位。
注意:当版本升级时,有些优化器提示可能会成为新版优化策略失效的原因!
优化特定类型的查询
优化COUNT()查询
count()的作用:
1.统计列值的数量,不包含NULL
2.统计行数,并不会将行展开,只统计有几行。
MyISAM的神话:
只有没有任何WHERE语句的COUNT才很快,因为此时无需任何计算,直接读表中存储的值即可。
简单优化
在使用MyISAM表可使用子查询,减少扫描行数。
比如:
SELECT (SELECT COUNT(*) FROM world.City)-COUNT(*) FROM world.City WHERE ID<=6;
这个用法倒是有点意思,下面两句是等价的
SELECT SUM(IF(color = 'blue',1,0) AS blue,SUM(IF(color = 'red',1,0)) AS red FROM items;
SELECT COUNT(color='blue' OR NULL) AS blue ,COUNT(color='red' OR NULL) AS red FROM items;
使用近似值
精确度要求不高时,使用EXPLAIN的估算的行数也不错(不过为啥不用Redis的HyperLogLog呢)
更复杂的优化
最多还能从覆盖索引下手,或者单独整一个汇总表。快速、精确、简单三者只能择其二啊。
优化关联查询
- 确保ON或者USING字句有使用索引,一般来说只需要在关联表的第二个表中建立索引。
- 确保任何的GROUP BY和ORDER BY只涉及到一个表中的列,这样才可能走索引
- 当升级Mysql时,关联顺序或者语法可能会发生变化
优化子查询
尽量用关联代替(5.6以及以上版本和忽略)
优化GROUP B和DISTINCT
这俩都可使用索引来优化。
GROUP BY无法使用索引时,使用两种策略来完成:1.临时表 2.文件排序。
可使用SQL_BIG_RESULT或者BIG_SMALL_RESULT来选择两种方式的其一。
分组的列最好比较有标志性。
但是如果查询列是非分组列就可能会出问题,因为不同的执行计划可能会出现差异(所以5.7真就有了SQL_MODE中默认设置了ONLY_FULL_GROUP_BY),具体可参考。
排序也可人为指定一个,要不然就是默认排序,如果不需要排序可使用ORDER BY NULL.
优化LIMIT分页
尽可能使用覆盖索引。要不然全表扫描,如果还有大数字的偏移量,那也开销挺高的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









